
Retrieval-augmented generation (RAG) models are a class of natural language processing models that leverage both retrieval and generation capabilities. They aim to produce high-quality text outputs by first retrieving relevant information from a large corpus of documents or knowledge sources, and then using that retrieved information to condition and augment the text generation process. The first step in a typical RAG model pipeline involves a retrieval component that encodes the input query and documents into dense vector representations. These vectors are then compared to find the top most relevant documents based on their similarity to the query vector. However, this initial retrieval step may not always surface the truly most relevant documents due to limitations in the vector encoding and similarity matching process.
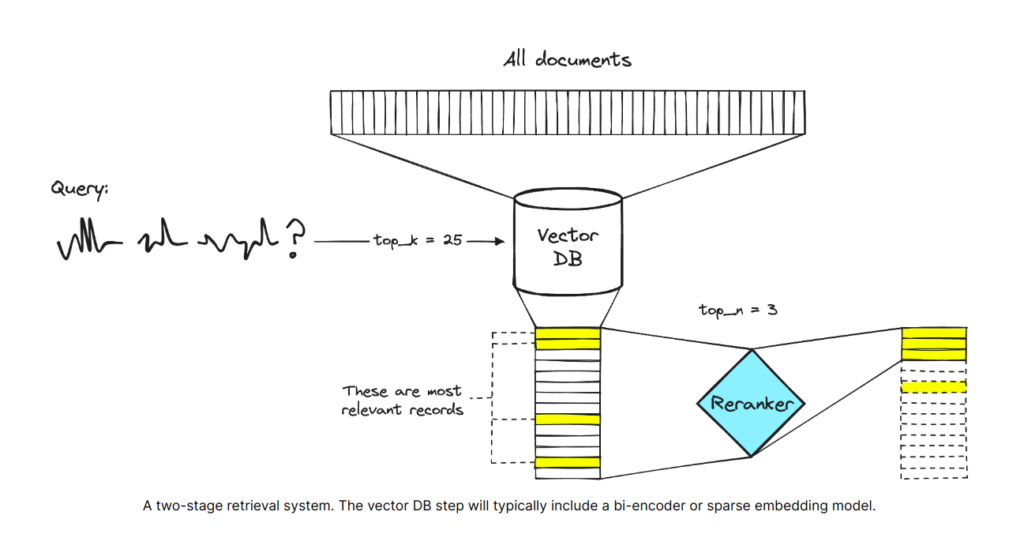
The typical RAG process is as follows:
1. The user asks a question or provides an instruction.
2. The system queries a vector database to find information relevant to the user’s question or instruction (“retrieval”).
3. The user’s prompt and any relevant information from the vector database are supplied to the language model (“augmentation”).
4. The language model uses the information from the database to answer the user’s prompt (“generation”).
Normally we use cosine similarly vector search when retrieving the related context from the Knowledge base or embedding.
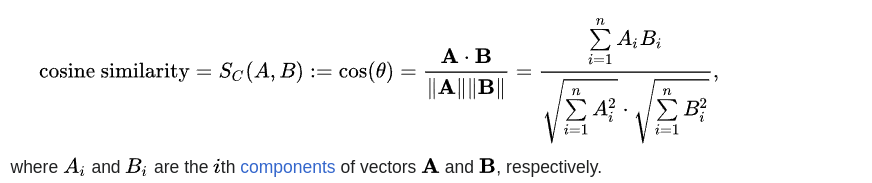
- Calculate the dot product of the two vectors: The dot product is calculated by multiplying the corresponding elements of the vectors and summing them up.
- dot_product = sum(a * b for a, b in zip(A, B))
- Calculate the L2 norm (Euclidean length) of each vector: The L2 norm is calculated by taking the square root of the sum of the squared elements of the vector.
- norm_A = sum(x ** 2 for x in A) ** 0.5
- norm_B = sum(x ** 2 for x in B) ** 0.5
- Calculate the cosine similarity: The cosine similarity is calculated as the dot product of the two vectors divided by the product of their L2 norms.
- cosine_similarity = dot_product / (norm_A * norm_B)
The cosine similarity metric doesn’t capture potential information loss or information mismatch between vectors during the initial encoding stage. It operates on the assumption that the vectors being compared accurately represent the underlying data or text. However, in practice, the process of encoding text or data into dense vectors using techniques like word embeddings or language models can introduce information loss or distortion. This can lead to situations where the cosine similarity between two vectors may not accurately reflect the true semantic similarity or relevance between the original text or data points.
Let’s consider an example to understand this issue:
Suppose we have two sentences:
“The quick brown fox jumps over the lazy dog.”
“A quick brown fox jumped over the sleeping dog.”
If we encode these sentences into dense vectors (let’s say 512-dimensional vectors) using a pre-trained language model, the resulting vectors may not capture the subtle differences in tense and article usage (“a” vs. “the”) due to the inherent limitations of the encoding process. Let’s represent the encoded vectors as
Sentence 1: v1 = [0.1, 0.2, -0.3, …, 0.2]
Sentence 2: v2 = [0.15, 0.25, -0.28, …, 0.18]
Now, if we calculate the cosine similarity between these two vectors:
cosine_similarity(v1, v2) = (v1 · v2) / (||v1|| * ||v2||)
The cosine similarity value may be very high, let’s say 0.98, indicating that these two sentences are highly similar according to the vector representations. However, if we look at the original sentences, we can see that there are subtle differences in tense and article usage, which may be important for certain applications or downstream tasks.
Why Re-Rank?
No matter the architecture of your model, there is a substantial performance degradation when you include 10+ retrieved documents. In brief: When models must access relevant information in the middle of long contexts, they tend to ignore the provided documents. This issue highlights one of the key reasons why the initial retrieval step alone may not work effectively in Retrieval-Augmented Generation (RAG) models. The initial retrieval process aims to surface the top-k most relevant documents based on vector similarity matching between the query and document embeddings.
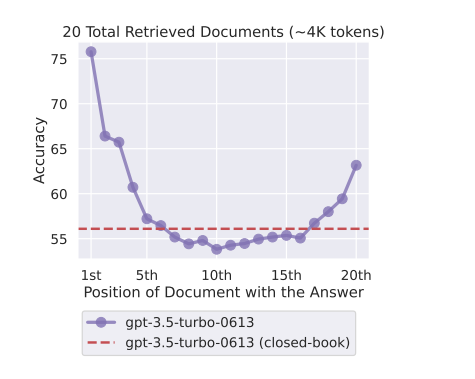
(Changing the location of relevant information (in this case, the position of the passage that answers an input question) within the language model’s input context results in a U-shaped performance curve—models are better at using relevant information that occurs at the very beginning (primacy bias) or end of its input context (recency bias). Performance degrades significantly when models must access and use information located in the middle of its input context.
Read: https://cs.stanford.edu/~nfliu/papers/lost-in-the-middle.arxiv2023.pdf
To overcome this we can re-rank the retrieved document and put the most relevant document in the beginning. There are several ways we can achieve this. we can use Bi-Encoder re-ranker, Cross-Encoder re-ranker, and LLM-based re-ranker.
There are several reasons why a re-ranker is beneficial in RAG models:
- Improved relevance: The re-ranker can employ more advanced models, such as cross-encoders or sequence classification models, to better capture the contextual relevance between the query and the retrieved documents. This helps surface the truly most relevant documents, which leads to improved generation quality.
- Handling complex queries: Simple vector similarity matching may struggle with complex, multi-faceted queries or queries involving logical reasoning. The re-ranker can better handle such cases by incorporating more advanced relevance signals. Mitigating retrieval errors: The initial retrieval step may sometimes fail to retrieve relevant documents due to encoding or matching errors. The re-ranker acts as a safeguard, potentially recovering relevant documents missed in the first step.
- Efficiency: While advanced cross-encoder models can be computationally expensive for the initial retrieval step, using a lightweight bi-encoder or sparse embedding model followed by a re-ranker can strike a balance between efficiency and effectiveness.
Just an Intro To Bi-Encoder models and Cross-Encoder models:
Before we jump into the re-ranker let’s see what is Bi-Encoder and Cross-Encoder models are.
Bi-Encoder models:
Bi-encoder models are utilized to generate dense vector embeddings for data, which can subsequently facilitate search queries. These models enable the comparison of data vectors and query vectors through methods such as cosine similarity. Utilizing a Bi-Encoder model, each item in the database can be represented by a vector embedding.
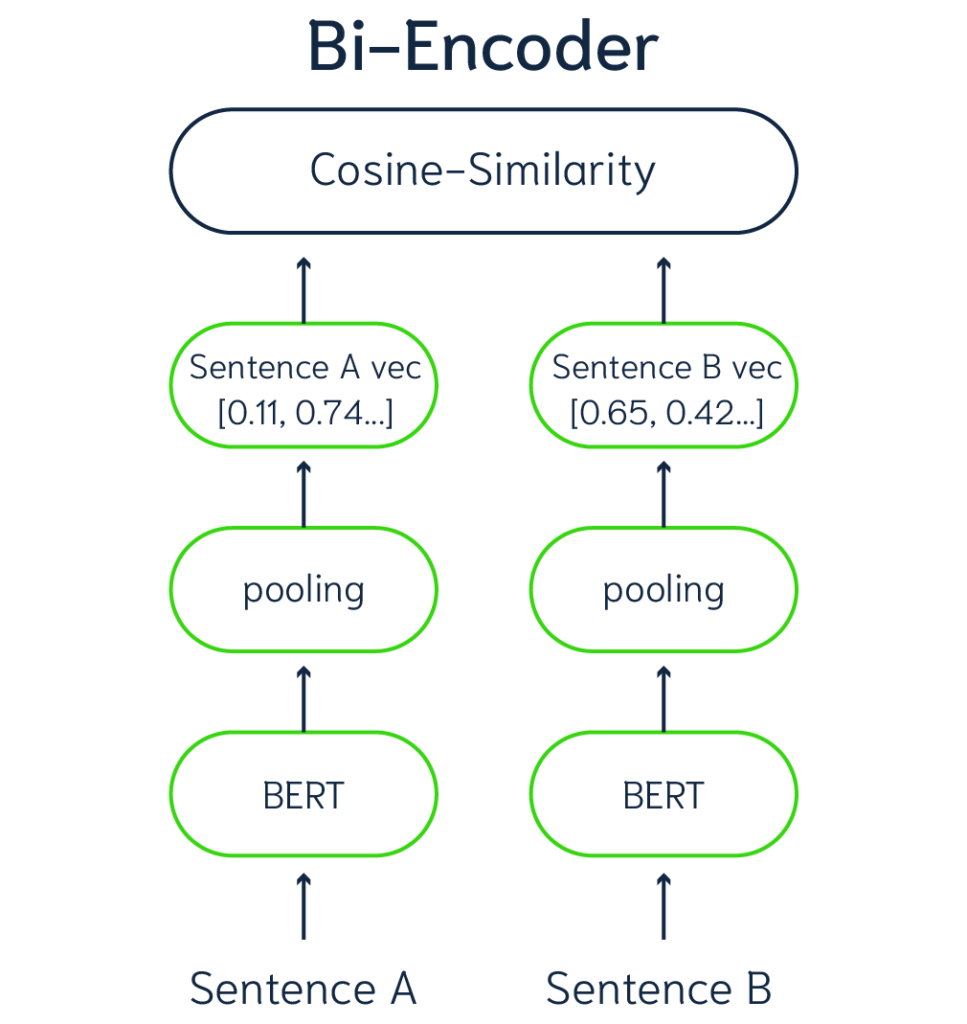
(Representation of a Bi-Encoder model)
Cross-Encoder models:
Bi-Encoder models represent one approach to assessing similarity between pairs of data. Alternatively, Cross-Encoder models offer a distinct strategy. Unlike Bi-Encoders, Cross-Encoders don’t generate vector embeddings for individual data points. Instead, they employ a classification mechanism specifically designed for data pairs. Each input to a Cross-Encoder model comprises a pair of data elements, like two sentences, producing a similarity score ranging from 0 to 1. Consequently, Cross-Encoders cannot process single sentences; they necessitate paired items for analysis. For search purposes, employing a Cross-Encoder involves pairing each data item with the search query to compute similarity.
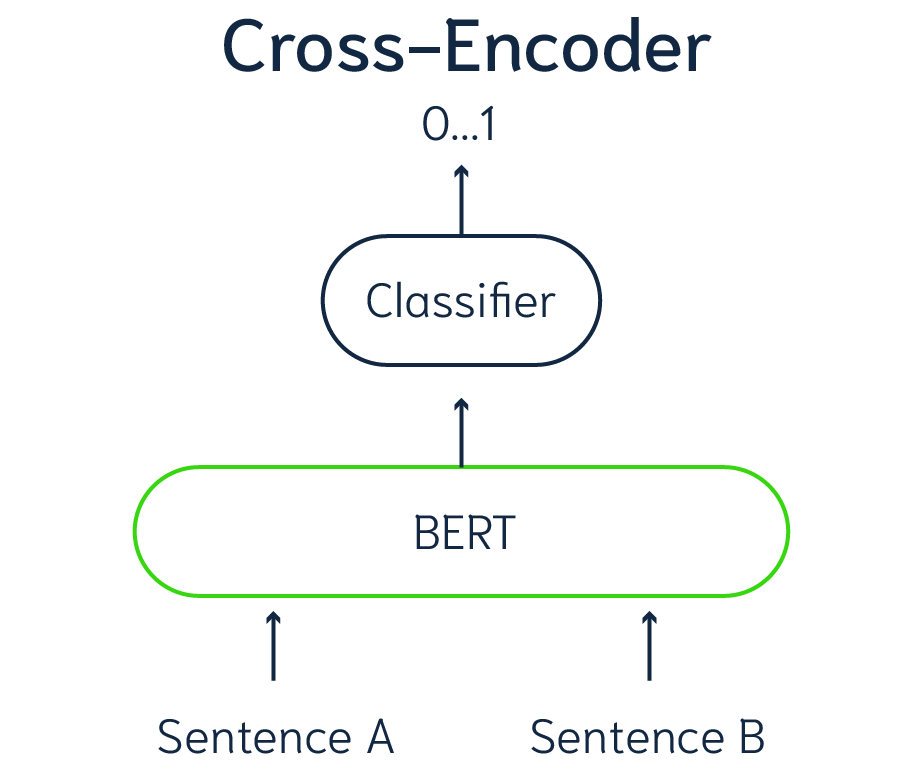
(Representation of a Cross-Encoder model)
Okay, that’s enough theory; let’s code.

Step 1: Install all the required packages we need.
!pip install –upgrade –quiet sentence-transformers langchain_community chromadb langchain langchain_openai
For demonstration purposes, we’ve released the Langchain 0.1 version blog, which you can find here: https://blog.langchain.dev/langchain-v0-1-0/
Step 2: Import all required packages into your working Notebook
from langchain.prompts import PromptTemplate
from langchain_community.document_transformers import (
LongContextReorder,
)
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAI
from langchain_community.document_loaders import WebBaseLoade
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import CrossEncoder
Step 3: Load the document and split it into chunks of 1000 with an overlap of 100.
"https://blog.langchain.dev/langchain-v0-1-0/"
)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
is_separator_regex = False
)
#
split_docs = text_splitter.split_documents(documents)
Step 4: Define the embedding model, convert the document into embeddings, and add the documents into Cromadb.
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
retriever = Chroma.from_documents(split_docs, embedding=embeddings)
# Create a retriever
retriever = retriever..as_retriever(
search_kwargs={"k": 5})
# Custom print function to print the retrieved document.
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n + {d.page_content}" for i,d in enumerate(docs)])
)
Step 5: Test document retrieval without re-ranking.
pretty_print_docs(retriever.get_relevant_documents("What are the major
changes in v 0.1.0?"))output:
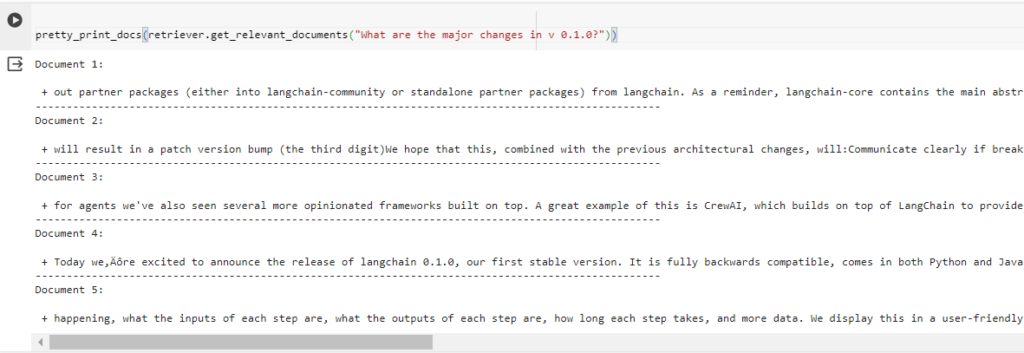
You can see this by viewing the 0th document that was not related to the question we asked. Also, the data was not chunked properly but we left it for some other time.
Step 6: Define a naive RAG (Retriever Answer Generator) with an OpenAI chat model.
import os
os.environ["OPENAI_API_KEY"] = "sk-*******"
ChatOpenAI = ChatOpenAI(model_name="gpt-3.5-turbo-16k",temperature=0.0
)
#
from langchain.chains import RetrievalQA
# create a retrieval chain
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
naive_response = qa("What are the major changes in v 0.1.0?")
print(naive_response['result'])
output:
1. Improved package architecture: LangChain has been re-architected to separate out langchain-core, which contains the main abstractions, interfaces, and core functionality, from partner packages. This separation allows for better organization and a stronger foundation for the project.
2. New versioning standard: LangChain now follows a new versioning standard. Any breaking changes to the public API will result in a minor version bump (the second digit), while bug fixes or new features will result in a patch version bump (the third digit). This new versioning standard aims to communicate clearly if breaking changes are made and provide developers with confidence when updating.
3. Focus and functionality improvements: The release of version 0.1.0 brings improved focus through both functionality and documentation. The stable version of LangChain is fully backwards compatible and comes with improved functionality and documentation, earning developer trust and allowing for systematic and safe evolution of the library.
Overall, these changes aim to provide clearer communication of breaking changes, reduce bloat, and improve stability and usability of LangChain.
Grate you have built a basic RAG. now let's implement the re-ranker to improve the address the lost in the middle issue
Grate you have built a basic RAG. now let's implement the re-ranker to improve the address the lost in the middle issue
Step 7: Let’s view the document with its re-ranking scores:
model = CrossEncoder('BAAI/bge-reranker-large', max_length=512)
query = "What are the major changes in v 0.1.0?"
docs = retriever.get_relevant_documents(query)
doc_with_rank_score = []
for doc in docs:
scores = model.predict([query,doc.page_content])
doc_with_rank_score.append((doc.page_content,scores))
print(doc_with_rank_score)
0.011810666),
('out partner packages (either into langchain-community or standalone partner packages) from langchain.\xa0As a reminder, langchain-core contains the main abstractions, interfaces, and core functionality. This code is stable and has been following a stricter versioning policy for a little over a month now.langchain itself, however, still remained on 0.0.x versions. Having all releases on minor version 0 created a few challenges:Users couldn’t be confident that updating would not have breaking changeslangchain became bloated and unstable as we took a “maintain everything” approach to reduce breaking changes and deprecation notificationsHowever, starting today with the release of langchain 0.1.0, all future releases will follow a new versioning standard. Specifically:Any breaking changes to the public API will result in a minor version bump (the second digit)Any bug fixes or new features will result in a patch version bump (the third digit)We hope that this, combined with the previous',
0.011810666),
('will result in a patch version bump (the third digit)We hope that this, combined with the previous architectural changes, will:Communicate clearly if breaking changes are made, allowing developers to update with confidenceGive us an avenue for officially deprecating and deleting old code, reducing bloatMore responsibly deal with integrations (whose SDKs are often changing as rapidly as LangChain)Even after we release a 0.2 version, we will commit to maintaining a branch of 0.1, but will only patch critical bug fixes. See more towards the end of this post on our plans for that.While re-architecting the package towards a path to a stable 0.1 release, we took the opportunity to talk to hundreds of developers about why they use LangChain and what they love about it. This input guided our direction and focus. We also used it as an opportunity to bring parity to the Python and JavaScript versions in the core areas outlined below. \uf8ffüí°While certain integrations and more tangential chains may',
0.007920413),
('will result in a patch version bump (the third digit)We hope that this, combined with the previous architectural changes, will:Communicate clearly if breaking changes are made, allowing developers to update with confidenceGive us an avenue for officially deprecating and deleting old code, reducing bloatMore responsibly deal with integrations (whose SDKs are often changing as rapidly as LangChain)Even after we release a 0.2 version, we will commit to maintaining a branch of 0.1, but will only patch critical bug fixes. See more towards the end of this post on our plans for that.While re-architecting the package towards a path to a stable 0.1 release, we took the opportunity to talk to hundreds of developers about why they use LangChain and what they love about it. This input guided our direction and focus. We also used it as an opportunity to bring parity to the Python and JavaScript versions in the core areas outlined below. \uf8ffüí°While certain integrations and more tangential chains may',
0.007920413),
("for agents we've also seen several more opinionated frameworks built on top. A great example of this is CrewAI, which builds on top of LangChain to provide an easier interface for multi-agent workloads.LangChain 0.2Even though we just released LangChain 0.1, we’re already thinking about 0.2. Some things that are top of mind for us are:Rewriting legacy chains in LCEL (with better streaming and debugging support)Adding new types of chainsAdding new types of agentsImproving our production ingestion capabilitiesRemoving old and unused functionalityImportantly, even though we are excited about removing some of the old and legacy code to make langchain slimmer and more focused, we also want to maintain support for people who are still using the old version. That is why we will maintain 0.1 as a stable branch (patching in critical bug fixes) for at least 3 months after 0.2 release. We plan to do this for every stable release from here on out.And if you've been wanting to get started",
0.07851976)]
Now you can use the scores to re-arrange the document. Not let’s implement this in langchain.
Step 8: langchain dose not support bge-reranker out of the box so you need to create your pipeline
from typing import Dict, Optional, Sequence
from langchain.schema import Document
from langchain.pydantic_v1 import Extra, root_validator
from langchain.callbacks.manager import Callbacks
from langchain.retrievers.document_compressors.base import BaseDocumentCompressor
from sentence_transformers import CrossEncoder
# from config import bge_reranker_large
class BgeRerank(BaseDocumentCompressor):
model_name:str = 'BAAI/bge-reranker-large'
"""Model name to use for reranking."""
top_n: int = 3
"""Number of documents to return."""
model:CrossEncoder = CrossEncoder(model_name)
"""CrossEncoder instance to use for reranking."""
def bge_rerank(self,query,docs):
model_inputs = [[query, doc] for doc in docs]
scores = self.model.predict(model_inputs)
results = sorted(enumerate(scores), key=lambda x: x[1], reverse=True)
return results[:self.top_n]
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
def compress_documents(
self,
documents: Sequence[Document],
query: str,
callbacks: Optional[Callbacks] = None,
) -> Sequence[Document]:
"""
Compress documents using BAAI/bge-reranker models.
Args:
documents: A sequence of documents to compress.
query: The query to use for compressing the documents.
callbacks: Callbacks to run during the compression process.
Returns:
A sequence of compressed documents.
"""
if len(documents) == 0: # to avoid empty api call
return []
doc_list = list(documents)
_docs = [d.page_content for d in doc_list]
results = self.bge_rerank(query, _docs)
final_results = []
for r in results:
doc = doc_list[r[0]]
doc.metadata["relevance_score"] = r[1]
final_results.append(doc)
return final_results
Step 9: Now let’s define our compression_pipeline
#
reordering = LongContextReorder()
#
reranker = BgeRerank()
#
pipeline_compressor = DocumentCompressorPipeline(transformers=[redundant_filter,reordering,reranker])
#
compression_pipeline = ContextualCompressionRetriever(base_compressor=pipeline_compressor,
base_retriever=retriever)
Now let's try the same query with compression_pipeline
docs = compression_pipeline.get_relevant_documents(“What are the major changes in v 0.1.0?”)
pretty_print_docs(docs)
pretty_print_docs(docs)
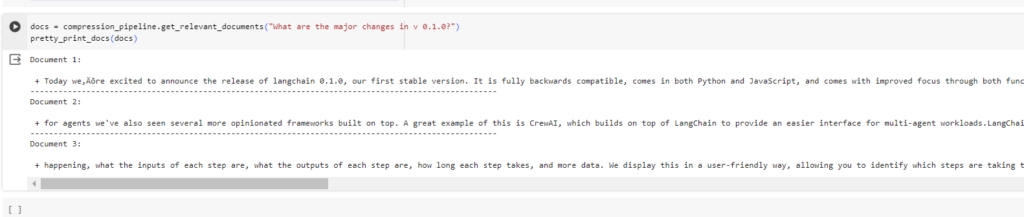
You can see there is a change in the document order now lets create RAG using our compression_pipeline as retrieval
Step 10: create RAG using our compression_pipeline as retrieval
from langchain.chains import RetrievalQA
#
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI,
chain_type="stuff",
retriever=compression_pipeline,
return_source_documents=True)
reranker_response = qa("What are the major changes in v 0.1.0?")
print(reranker_response['result'])
The major changes in the LangChain release include:
1. Re-architecting the package towards a stable 0.1 release.
2. Talking to hundreds of developers to gather input and feedback on LangChain.
3. Bringing parity to the Python and JavaScript versions in core areas.
4. Introducing a new versioning standard for LangChain releases.
5. Maintaining a stable branch (0.1) for critical bug fixes for at least 3 months after the 0.2 release.
6. Removing old and unused functionality.
7. Rewriting legacy chains in LCEL with better streaming and debugging support.
8. Adding new types of chains and agents.
9. Improving production ingestion capabilities.
10. Moving partner packages into langchain-community or standalone partner packages.
These changes aim to communicate breaking changes clearly, reduce bloat, and provide a more stable and focused LangChain experience.
Final output:
You see the different in the answer we get from the RAG.
Thank you for being with me until the very end! I know it’s a long blog, but in the end, we’re happy with the results we’ve achieved. ? Until next time, goodbye, and happy coding!











12 thoughts on “Retrieval-Augmented Ranking: A Key Technique for High-Performing RAGs”
Comments are closed.