
Table of Contents
1. TTS: The Dawn of a New Era in Communication
2 . StyleTTS2 Architecture and Training: Crafting Lifelike Voices with Precision
3. Kokoro: A Faster Alternative to StyleTTS 2
What if a machine could whisper words of comfort or deliver a laugh so genuine, you’d forget it wasn’t human? Welcome to the era of StyleTTS2.
Introduction
Imagine a world where machines don’t just speak but truly communicate—where synthetic voices are indistinguishable from human ones, brimming with emotion, nuance, and personality. This vision is closer than ever, thanks to groundbreaking advancements in Text-to-Speech (TTS) technology, particularly through innovations like StyleTTS2 and the emerging Kokoro model. These systems are redefining speech synthesis by blending cutting-edge techniques such as style diffusion, adversarial training, and large-scale Speech Language Models (SLMs). StyleTTS2, for instance, leverages probabilistic style sampling to dynamically adapt prosody, tone, and emotional depth, achieving human-like expressiveness and naturalness. Meanwhile, models like Kokoro aim to push these capabilities even further, setting new standards for realism and adaptability.
But here’s the exciting part: StyleTTS2 isn’t just about better sound quality—it represents a pivotal step toward bridging the gap between artificial intelligence and human-like interaction. While achieving Artificial General Intelligence (AGI)—machines capable of reasoning, understanding context, and self-learning—remains an elusive goal, innovations like StyleTTS2 bring us closer than ever before. Together, these advancements challenge the boundaries of how machines interpret language and express meaning, paving the way for a future where AI voices resonate with unparalleled authenticity.
TTS: The Dawn of a New Era in Communication
Text-to-Speech (TTS) technology has long been the bridge between text and voice, but its evolution is transforming it into something far more profound—a tool for genuine connection. In its early days, TTS relied on rule-based systems and rigid concatenative methods, stitching together pre-recorded audio snippets to form robotic, monotone outputs. While functional, these systems lacked the emotional depth and natural flow that define human speech.
The game-changer came with deep learning, where models like Tacotron and WaveNet introduced neural networks to synthesize smoother, more expressive voices. However, the real revolution lies in modern methodologies like diffusion models, adversarial training, and large Speech Language Models (SLMs). These innovations enable TTS systems to dynamically adapt tone, emotion, and prosody, creating voices that aren’t just heard but felt.
Today’s TTS isn’t just about converting text to sound—it’s about crafting lifelike interactions. With advancements like StyleTTS2, machines can now generate speech that mirrors human nuance, from subtle pauses to bursts of excitement, all without needing reference audio. This leap marks the dawn of a new era where TTS becomes a medium for storytelling, empathy, and authentic communication.
StyleTTS2 Architecture and Training: Crafting Lifelike Voices with Precision
At the heart of StyleTTS2 lies a powerful architecture combining an Encoder and a Vocoder , working seamlessly to transform text into natural, expressive speech. Let’s dive into how each component works and what makes this model revolutionary.
How the Encoder Works?
The Encoder operates through a series of well-defined steps:
1. Text Input :
The process begins with the input text, which is first converted into phonemes —the smallest units of sound in human speech. This phoneme representation serves as the foundation for generating speech.
“Hello, how are you?” —–> həˈloʊ | ˈhaʊ ɑːr juː?
Text Phonemes
2. Style Vector :
The phonemes are then transformed into a fixed-length style vector . This vector is sampled using a diffusion mechanism within the Generator of the GAN. The style vector guides the tone, emotion, or accent of the speech, ensuring diverse and expressive outputs without requiring reference audio.
3. Output :
The final result is a clean, high-quality Mel-Spectrogram that visually represents the text in the desired style.
How the Encoder is Trained?
To train the Encoder, we require paired data of text and audio, where the text is represented as phonemes and the audio is represented as a Mel-Spectrogram . The Encoder’s training process is powered by two key innovations: Generative Adversarial Networks (GANs) and a diffusion mechanism within the generator.
GAN Architecture
The Encoder employs a Generative Adversarial Network (GAN) to refine the quality of the generated Mel-Spectrograms. The GAN consists of two components:
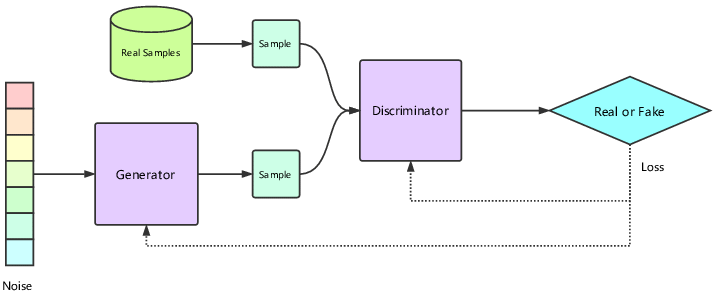
GAN WORKING
Generator :
The Generator creates a Mel-Spectrogram from the input text . Its goal is to produce something so realistic that it fools the Discriminator into thinking it’s real.
Discriminator :
The Discriminator evaluates whether the Mel-Spectrogram is real (from original audio) or fake (generated by the Generator). It provides feedback to the Generator, pushing it to improve.
This adversarial process continues until the Generator produces Mel-Spectrograms so good that the Discriminator can’t distinguish them from real ones. This competition ensures unparalleled realism and expressiveness in the generated speech.
Diffusion Mechanism in the Generator
The diffusion mechanism is a key innovation in StyleTTS2, setting it apart from traditional TTS models. Instead of directly generating the entire Mel-Spectrogram, the model samples a style vector through a diffusion process. Here’s how it works:
DIFFUSION MECHANISM
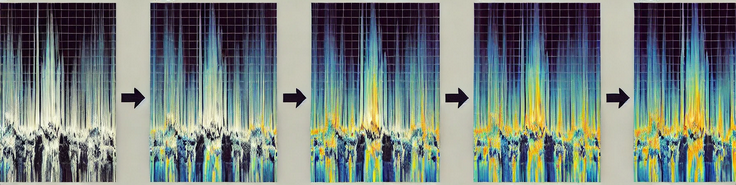
1. Initial Noise :
The Generator starts with a rough, noisy Mel-Spectrogram based on the input text.
2. Add Style Vector :
A fixed-length style vector is introduced to guide the tone, emotion, or accent of the speech.
3. Refinement :
The diffusion process gradually refines the noisy Mel-Spectrogram:
– It removes noise and enhances details in stages.
– The style vector ensures the output matches the desired speaking style.
4. Final Output :
The result is a clean, high-quality Mel-Spectrogram that mirrors the input text with the desired emotional depth.
This approach allows StyleTTS2 to dynamically adapt prosody, tone, and emotion, creating voices that feel truly alive.
The Vocoder: Bringing Sound to Life
The Vocoder in StyleTTS2 is responsible for converting the high-quality Mel-Spectrogram generated by the Encoder into natural, expressive speech audio. It serves as the final step in the synthesis pipeline, transforming the visual representation of sound into an audible waveform.
How the Vocoder Works?
The Vocoder takes the Mel-Spectrogram as input and generates the corresponding waveform through advanced neural architectures. StyleTTS2 employs two types of vocoders:
– HiFi-GAN-based : Directly generates high-fidelity waveforms with exceptional clarity and speed.
– iSTFTNet-based : Produces magnitude and phase information, which is converted into waveforms using inverse short-time Fourier transform (iSTFT) for faster inference.
Both architectures use the snake activation function , proven effective for waveform generation, and incorporate Adaptive Instance Normalization (AdaIN) to model style-dependent speech characteristics.
How the Vocoder is Trained?
The Vocoder is trained using paired data: Mel-Spectrograms (input) and their corresponding raw audio waveforms (output). The training process minimizes the difference between the generated audio and the ground truth audio, ensuring high-quality output. Advanced techniques like GAN-based training are employed to refine the waveform generation process, ensuring smooth, natural, and human-like speech.
By leveraging these methods, the Vocoder ensures that the final synthesized speech is not only accurate but also rich in detail and emotional nuance, bridging the gap between artificial and human communication.
Versatility and Adaptability of StyleTTS 2
StyleTTS 2 is inherently designed to support multilingual and multi-speaker synthesis , making it versatile for diverse applications. It can generate speech in multiple languages by leveraging phoneme-based input representations and adapt to various speakers using style diffusion and speaker embeddings. For specific needs, StyleTTS 2 can be fine-tuned for a particular language or speaker with significantly less data compared to training from scratch.
For example, fine-tuning requires only 1 hour of speech data for a language or a short 3-second reference audio for a speaker. This data-efficient approach ensures high-quality results while maintaining the model’s flexibility and performance. By fine-tuning, StyleTTS 2 achieves tailored outputs for niche languages or personalized voices without extensive computational resources.
Kokoro: A Faster Alternative to StyleTTS 2
Kokoro builds on the foundation of StyleTTS 2 but introduces key optimizations that make it significantly faster while maintaining high voice quality. These improvements make Kokoro a standout choice for real-time and resource-efficient applications.
What makes kokoro special?
1 . No Diffusion Steps :
– Eliminates iterative refinement in the generator, drastically reducing computational overhead.
– Directly generates high-quality Mel-Spectrograms, ensuring faster inference without compromising on expressiveness or naturalness.
2 . ISTFTNet Vocoder :
– Employs ISTFTNet , a lightweight vocoder optimized for speed and memory efficiency.
– Converts Mel-Spectrograms into waveforms using inverse short-time Fourier transform (iSTFT), enhancing both training and inference speed.
3. Resource Efficiency :
– Requires fewer computational resources for training compared to StyleTTS 2.
– Achieves high-quality synthesis with smaller datasets, making it ideal for real-time and low-resource applications.
4. Performance :
– Sets a new benchmark for TTS models by balancing speed and quality.
– Matches or exceeds StyleTTS 2 in terms of naturalness and expressiveness while being significantly faster during inference.
Conclusion: Bridging Human and Machine Communication
StyleTTS2 and Kokoro redefine Text-to-Speech (TTS) with style diffusion, adversarial training, and advanced vocoders, creating lifelike, expressive speech. StyleTTS2 sets new benchmarks in realism, while Kokoro enhances speed without quality loss. These innovations drive seamless, empathetic AI-human communication.
Beyond TTS, these models advance Artificial General Intelligence (AGI) by enabling nuanced, emotionally adaptive speech. As AI refines human-like interaction, TTS becomes a cornerstone for AGI’s evolution. With ethical safeguards, StyleTTS2 and Kokoro bring AI voices closer to human authenticity.











So I tried soso66 the other day. Not bad, not amazing. The interface is pretty easy to use, especially on mobile. Might be a good option if you like playing on your phone. See what you think: soso66
FC7777login? Alright, alright, let’s see what you got. Hope the login’s smooth ’cause ain’t nobody got time for glitches! Give it a whirl fc7777login.
Magnificent goods from you, man. I have understand your stuff previous to and you’re just extremely great. I really like what you have acquired here, certainly like what you’re saying and the way in which you say it. You make it entertaining and you still take care of to keep it sensible. I cant wait to read much more from you. This is actually a tremendous web site.
Hi, Neat post. There is an issue together with your website in internet explorer, may test this… IE nonetheless is the market chief and a large part of other folks will leave out your magnificent writing because of this problem.
Heard some whispers about Trangtongbong88 being the go-to spot. Worth a look if you’re trying to up your game! trangtongbong88
I cherished up to you will obtain performed right here. The caricature is attractive, your authored subject matter stylish. nonetheless, you command get bought an edginess over that you would like be delivering the following. in poor health no doubt come more before once more since exactly the similar nearly a lot steadily inside of case you protect this hike.
I am not rattling good with English but I come up this real easy to interpret.
I do agree with all of the ideas you have presented in your post. They’re really convincing and will certainly work. Still, the posts are too short for novices. Could you please extend them a little from next time? Thanks for the post.
Yay google is my world beater aided me to find this great web site! .
Howdy! I know this is kinda off topic but I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog post or vice-versa? My website covers a lot of the same subjects as yours and I believe we could greatly benefit from each other. If you are interested feel free to send me an email. I look forward to hearing from you! Fantastic blog by the way!
Excellent read, I just passed this onto a colleague who was doing some research on that. And he just bought me lunch because I found it for him smile Thus let me rephrase that: Thanks for lunch! “The capacity to care is what gives life its most deepest significance.” by Pablo Casals.
Hmm it appears like your website ate my first comment (it was extremely long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still new to everything. Do you have any points for newbie blog writers? I’d genuinely appreciate it.
Hello, you used to write excellent, but the last few posts have been kinda boringK I miss your great writings. Past several posts are just a little bit out of track! come on!
Thanks for sharing excellent informations. Your web site is very cool. I am impressed by the details that you¦ve on this web site. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found just the information I already searched all over the place and simply could not come across. What a perfect site.
Normally I do not read post on blogs, but I wish to say that this write-up very forced me to try and do so! Your writing style has been amazed me. Thanks, very nice post.
Thanks for any other informative site. The place else may just I am getting that type of info written in such a perfect approach? I have a venture that I’m just now operating on, and I have been on the look out for such information.
Its such as you learn my thoughts! You appear to understand a lot approximately this, like you wrote the book in it or something. I think that you just could do with a few p.c. to power the message house a bit, however other than that, this is excellent blog. A great read. I will certainly be back.
I’ve recently started a site, the info you offer on this web site has helped me tremendously. Thanks for all of your time & work.
whoah this blog is excellent i like reading your posts. Keep up the good work! You already know, lots of individuals are searching round for this information, you could help them greatly.
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
Thanx for the effort, keep up the good work Great work, I am going to start a small Blog Engine course work using your site I hope you enjoy blogging with the popular BlogEngine.net.Thethoughts you express are really awesome. Hope you will right some more posts.
Definitely, what a magnificent site and revealing posts, I surely will bookmark your website.Best Regards!
As I website possessor I conceive the subject matter here is real fantastic, thanks for your efforts.
Its such as you read my mind! You appear to know so much approximately this, like you wrote the guide in it or something. I think that you simply can do with some to drive the message house a bit, however instead of that, this is magnificent blog. An excellent read. I’ll certainly be back.
A powerful share, I just given this onto a colleague who was doing a little analysis on this. And he the truth is purchased me breakfast as a result of I discovered it for him.. smile. So let me reword that: Thnx for the treat! However yeah Thnkx for spending the time to debate this, I feel strongly about it and love studying extra on this topic. If doable, as you grow to be experience, would you mind updating your weblog with extra particulars? It’s extremely useful for me. Massive thumb up for this weblog post!
Only a smiling visitant here to share the love (:, btw outstanding style. “Competition is a painful thing, but it produces great results.” by Jerry Flint.
Interesting read! The focus on RTP & fair gaming is crucial – players deserve transparency. Considering platforms like ninogaming slot download, easy access via app (Android 5.0+) seems key for the Philippine market. Good insights!
Very interesting topic, appreciate it for putting up.
I?¦ve read some just right stuff here. Definitely worth bookmarking for revisiting. I surprise how so much effort you set to create this sort of wonderful informative site.
You are my inspiration , I possess few web logs and infrequently run out from to post : (.
I believe this website contains some really good information for everyone : D.
Excellent blog here! Also your web site loads up very fast! What host are you using? Can I get your affiliate link to your host? I wish my site loaded up as fast as yours lol
I have been absent for some time, but now I remember why I used to love this blog. Thanks, I will try and check back more often. How frequently you update your web site?
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
What’s Happening i’m new to this, I stumbled upon this I have found It absolutely useful and it has aided me out loads. I hope to contribute & help other users like its helped me. Great job.
Way cool, some valid points! I appreciate you making this article available, the rest of the site is also high quality. Have a fun.
I?¦ve been exploring for a bit for any high quality articles or blog posts on this kind of house . Exploring in Yahoo I eventually stumbled upon this website. Studying this info So i?¦m happy to exhibit that I’ve an incredibly just right uncanny feeling I came upon exactly what I needed. I such a lot undoubtedly will make sure to do not disregard this site and provides it a glance on a continuing basis.
Loving the information on this site, you have done outstanding job on the articles.
hello there and thank you for your info – I have definitely picked up anything new from right here. I did however expertise several technical points using this website, since I experienced to reload the web site lots of times previous to I could get it to load correctly. I had been wondering if your hosting is OK? Not that I’m complaining, but slow loading instances times will sometimes affect your placement in google and could damage your high quality score if ads and marketing with Adwords. Anyway I am adding this RSS to my email and could look out for a lot more of your respective fascinating content. Make sure you update this again very soon..
My developer is trying to convince me to move to .net from PHP. I have always disliked the idea because of the costs. But he’s tryiong none the less. I’ve been using Movable-type on various websites for about a year and am anxious about switching to another platform. I have heard excellent things about blogengine.net. Is there a way I can import all my wordpress content into it? Any kind of help would be really appreciated!
Thank you for the sensible critique. Me & my neighbor were just preparing to do some research about this. We got a grab a book from our local library but I think I learned more clear from this post. I’m very glad to see such magnificent info being shared freely out there.
Pretty portion of content. I just stumbled upon your website and in accession capital to assert that I get actually loved account your weblog posts. Any way I’ll be subscribing to your feeds and even I fulfillment you access constantly quickly.
My spouse and i ended up being absolutely thankful that Michael could conclude his inquiry out of the precious recommendations he made out of the web pages. It is now and again perplexing to simply always be offering information and facts people have been trying to sell. We really keep in mind we have got you to appreciate for that. These explanations you made, the simple web site menu, the friendships you can help foster – it is mostly fabulous, and it’s really letting our son and our family feel that that situation is excellent, and that’s unbelievably mandatory. Thank you for everything!
I’ve recently started a website, the information you offer on this site has helped me tremendously. Thanks for all of your time & work.
Excellent web site. Lots of helpful information here. I’m sending it to several pals ans additionally sharing in delicious. And naturally, thank you on your effort!
I have been surfing online greater than 3 hours nowadays, but I never discovered any attention-grabbing article like yours. It is pretty value enough for me. In my opinion, if all site owners and bloggers made just right content as you probably did, the net will likely be much more useful than ever before.
I was just looking for this information for some time. After 6 hours of continuous Googleing, at last I got it in your web site. I wonder what’s the lack of Google strategy that don’t rank this kind of informative web sites in top of the list. Usually the top sites are full of garbage.
Hi there, I found your blog via Google while looking for a related topic, your site came up, it looks great. I’ve bookmarked it in my google bookmarks.
I truly appreciate this post. I have been looking everywhere for this! Thank goodness I found it on Bing. You have made my day! Thanks again!
There is visibly a bundle to identify about this. I consider you made various good points in features also.
Hello, Neat post. There’s an issue with your site in web explorer, might check this?K IE still is the marketplace leader and a big component to people will omit your wonderful writing due to this problem.
I couldn’t resist commenting
I?¦ll right away grasp your rss as I can not find your e-mail subscription link or newsletter service. Do you have any? Please let me realize in order that I could subscribe. Thanks.
With havin so much content and articles do you ever run into any issues of plagorism or copyright violation? My website has a lot of unique content I’ve either written myself or outsourced but it seems a lot of it is popping it up all over the internet without my permission. Do you know any techniques to help stop content from being stolen? I’d genuinely appreciate it.
Excellent post. I was checking constantly this weblog and I am inspired! Extremely helpful info specially the final part 🙂 I handle such info much. I used to be seeking this certain information for a long time. Thank you and best of luck.
I just couldn’t go away your website prior to suggesting that I extremely loved the standard information an individual supply on your visitors? Is going to be again regularly to inspect new posts.
This web site is really a walk-through for all of the info you wanted about this and didn’t know who to ask. Glimpse here, and you’ll definitely discover it.
obviously like your web-site but you have to test the spelling on quite a few of your posts. Several of them are rife with spelling problems and I in finding it very troublesome to tell the reality nevertheless I’ll certainly come again again.
Admiring the commitment you put into your blog and detailed information you provide. It’s good to come across a blog every once in a while that isn’t the same unwanted rehashed material. Great read! I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
Hey there just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same results.
A formidable share, I simply given this onto a colleague who was doing just a little evaluation on this. And he the truth is bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the deal with! But yeah Thnkx for spending the time to debate this, I really feel strongly about it and love studying extra on this topic. If potential, as you change into experience, would you thoughts updating your blog with extra details? It’s extremely helpful for me. Huge thumb up for this blog put up!
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
JLJL99AppLogin – Anything that makes logging in easier is a win in my book. Seriously, who has time to remember a million passwords? This app gets me straight to the games I want. Login faster: jljl99applogin
Pxxbetcom is alright! I like the selection of games they’ve got. The site runs smooth, which is a plus. Not my absolute fave, but decent for a quick play. Check it out for yourself at pxxbetcom!
Looking for some games to download? VipGameDownload has a few options, but do your research before downloading anything. Safety first, always! Check them out at vipgamedownload.
I am extremely impressed with your writing skills and also with the layout on your weblog. Is this a paid theme or did you modify it yourself? Anyway keep up the nice quality writing, it is rare to see a great blog like this one nowadays..
Howdy would you mind letting me know which webhost you’re using? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot quicker then most. Can you suggest a good web hosting provider at a reasonable price? Thanks, I appreciate it!
Merely wanna comment on few general things, The website layout is perfect, the written content is very wonderful : D.
An interesting discussion is worth comment. I think that you should write more on this topic, it might not be a taboo subject but generally people are not enough to speak on such topics. To the next. Cheers
Great line up. We will be linking to this great article on our site. Keep up the good writing.
I conceive this internet site has got some really good info for everyone. “Few friendships would survive if each one knew what his friend says of him behind his back.” by Blaise Pascal.
I’ve been absent for some time, but now I remember why I used to love this site. Thanks , I will try and check back more frequently. How frequently you update your web site?
I enjoy you because of all of your labor on this web site. Betty takes pleasure in making time for research and it’s easy to see why. We all notice all concerning the powerful medium you give simple things on your web blog and in addition foster participation from the others on that subject matter and our favorite princess has always been understanding a great deal. Take pleasure in the remaining portion of the new year. You’re the one conducting a dazzling job.
My spouse and I stumbled over here from a different page and thought I may as well check things out. I like what I see so i am just following you. Look forward to looking over your web page yet again.
Hello! I’ve been following your web site for a long time now and finally got the bravery to go ahead and give you a shout out from Houston Texas! Just wanted to mention keep up the fantastic job!
Great write-up, I am normal visitor of one’s site, maintain up the excellent operate, and It’s going to be a regular visitor for a lengthy time.
I definitely wanted to make a quick word in order to appreciate you for all the awesome ideas you are showing here. My considerable internet investigation has now been rewarded with extremely good concept to talk about with my companions. I would state that that we readers actually are undoubtedly fortunate to dwell in a fine community with so many wonderful professionals with very helpful methods. I feel quite happy to have encountered your entire web site and look forward to so many more thrilling moments reading here. Thanks a lot again for everything.
After study just a few of the blog posts on your website now, and I really like your means of blogging. I bookmarked it to my bookmark web site list and will likely be checking back soon. Pls check out my site as effectively and let me know what you think.
Good day very cool web site!! Guy .. Beautiful .. Superb .. I will bookmark your web site and take the feeds additionally…I’m glad to find numerous useful info here within the submit, we want develop more techniques in this regard, thank you for sharing.
Hello, i think that i saw you visited my website so i came to “return the favor”.I’m attempting to find things to improve my website!I suppose its ok to use a few of your ideas!!
You are my inspiration , I possess few web logs and rarely run out from to post : (.
Everything is very open and very clear explanation of issues. was truly information. Your website is very useful. Thanks for sharing.
Some times its a pain in the ass to read what people wrote but this site is real user genial! .
888win10? Yo, it’s pretty clean-cut. Easy on the eyes. Definitely worth checking out if you’re tired of cluttered sites. Get your win on with 888win10.
Okay, 888jogobet… not bad, man. It’s alright, with a nice amount of games. See for yourself though with 888jogobet!
Roulette fans, assemble! Found Fourtuneroulettebetboom. The name is intriguing. Has anyone tried their roulette? Is it legit? Thinking of giving it a spin. Check it out here: fourtuneroulettebetboom
I conceive this site has some rattling good info for everyone : D.
I used to be very pleased to search out this net-site.I wished to thanks to your time for this glorious read!! I undoubtedly having fun with every little little bit of it and I have you bookmarked to take a look at new stuff you weblog post.
I am really impressed with your writing skills and also with the layout on your weblog. Is this a paid theme or did you customize it yourself? Anyway keep up the nice quality writing, it’s rare to see a nice blog like this one nowadays..
Very interesting info!Perfect just what I was looking for!
Really instructive and fantastic bodily structure of articles, now that’s user genial (:.
This blog is definitely rather handy since I’m at the moment creating an internet floral website – although I am only starting out therefore it’s really fairly small, nothing like this site. Can link to a few of the posts here as they are quite. Thanks much. Zoey Olsen
Loving the info on this internet site, you have done outstanding job on the content.
Hey all! Just wanted to share that I’ve been having some fun on ee11bet lately. Good selection of games and the odds seem fair enough. Worth a look! More info here: ee11bet
Yo, check out pkrvipgame! Just stumbled upon it and it’s pretty legit. Good variety of games, if you’re into that kinda thing. Hit it up here: pkrvipgame
Yo, just downloaded 92app and it’s actually pretty good. Smooth interface and gets the job done. Worth checking out if you’re in the market: 92app
You really make it seem so easy together with your presentation however I in finding this topic to be actually something that I believe I’d never understand. It seems too complicated and extremely huge for me. I’m taking a look forward to your subsequent put up, I will attempt to get the hang of it!
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
Real excellent visual appeal on this site, I’d rate it 10 10.
Thank you for helping out, excellent info. “A man will fight harder for his interests than for his rights.” by Napoleon Bonaparte.
You have remarked very interesting details! ps decent site.
I have been exploring for a little for any high quality articles or blog posts in this kind of area . Exploring in Yahoo I ultimately stumbled upon this site. Reading this info So i am glad to show that I’ve an incredibly good uncanny feeling I found out exactly what I needed. I such a lot indisputably will make certain to don¦t disregard this site and provides it a glance on a relentless basis.
Very interesting information!Perfect just what I was searching for!
I really enjoy studying on this web site, it contains good content. “Literature is the orchestration of platitudes.” by Thornton.
I want meeting utile info, this post has got me even more info! .
I don’t normally comment but I gotta admit thankyou for the post on this amazing one : D.
Thanks for the sensible critique. Me & my neighbor were just preparing to do some research about this. We got a grab a book from our local library but I think I learned more clear from this post. I am very glad to see such great info being shared freely out there.
Thank you for sharing superb informations. Your site is very cool. I am impressed by the details that you’ve on this site. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for extra articles. You, my pal, ROCK! I found simply the information I already searched all over the place and just couldn’t come across. What a perfect site.
This really answered my problem, thank you!
Unquestionably believe that which you said. Your favorite reason seemed to be on the internet the simplest thing to be aware of. I say to you, I certainly get irked while people think about worries that they plainly don’t know about. You managed to hit the nail upon the top and defined out the whole thing without having side-effects , people can take a signal. Will probably be back to get more. Thanks
Hello my family member! I want to say that this article is amazing, nice written and include approximately all vital infos. I’d like to look extra posts like this.
fantastic issues altogether, you just won a emblem new reader. What may you suggest about your submit that you simply made a few days ago? Any positive?
he blog was how do i say it… relevant, finally something that helped me. Thanks
Generally I do not read article on blogs, but I would like to say that this write-up very forced me to try and do so! Your writing style has been surprised me. Thanks, quite nice post.
You have brought up a very wonderful details, appreciate it for the post.
Hello. remarkable job. I did not expect this. This is a fantastic story. Thanks!
This blog is definitely rather handy since I’m at the moment creating an internet floral website – although I am only starting out therefore it’s really fairly small, nothing like this site. Can link to a few of the posts here as they are quite. Thanks much. Zoey Olsen
What’s Taking place i am new to this, I stumbled upon this I have found It positively helpful and it has helped me out loads. I’m hoping to contribute & aid different users like its aided me. Good job.
Fascinating blog! Is your theme custom made or did you download it from somewhere? A theme like yours with a few simple adjustements would really make my blog stand out. Please let me know where you got your theme. With thanks
This web site is my breathing in, rattling good design and perfect articles.
Only a smiling visitor here to share the love (:, btw great style.
I’ll immediately clutch your rss feed as I can not in finding your email subscription hyperlink or e-newsletter service. Do you have any? Please allow me know so that I may just subscribe. Thanks.
hey there and thank you for your information – I’ve definitely picked up something new from right here. I did however expertise some technical issues using this web site, since I experienced to reload the web site lots of times previous to I could get it to load properly. I had been wondering if your web hosting is OK? Not that I am complaining, but sluggish loading instances times will sometimes affect your placement in google and could damage your high-quality score if ads and marketing with Adwords. Well I am adding this RSS to my e-mail and could look out for a lot more of your respective interesting content. Ensure that you update this again very soon..
A lot of thanks for all of the effort on this blog. My niece really loves going through investigations and it’s really easy to see why. Most of us notice all about the dynamic manner you offer very important steps on this website and therefore increase contribution from other ones on the situation so our girl is now discovering so much. Take pleasure in the remaining portion of the new year. You’re conducting a great job.
Hiya, I’m really glad I have found this info. Nowadays bloggers publish only about gossips and net and this is actually annoying. A good blog with exciting content, this is what I need. Thank you for keeping this site, I’ll be visiting it. Do you do newsletters? Can’t find it.
I discovered your blog site on google and check a few of your early posts. Continue to keep up the very good operate. I just additional up your RSS feed to my MSN News Reader. Seeking forward to reading more from you later on!…
This is the right blog for anyone who wants to find out about this topic. You realize so much its almost hard to argue with you (not that I actually would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great!
I haven¦t checked in here for some time because I thought it was getting boring, but the last several posts are great quality so I guess I will add you back to my everyday bloglist. You deserve it my friend 🙂
You are my inhalation, I have few blogs and very sporadically run out from to brand.
wonderful post, very informative. I wonder why the other specialists of this sector don’t notice this. You must continue your writing. I am confident, you’ve a great readers’ base already!
Hi there, just was aware of your blog thru Google, and found that it’s truly informative. I am going to be careful for brussels. I’ll appreciate in case you continue this in future. Many folks will be benefited out of your writing. Cheers!
I’m now not positive where you’re getting your info, but great topic. I must spend some time finding out much more or working out more. Thanks for great information I used to be searching for this information for my mission.
Awsome site! I am loving it!! Will come back again. I am bookmarking your feeds also.
Great write-up, I¦m normal visitor of one¦s web site, maintain up the nice operate, and It’s going to be a regular visitor for a lengthy time.
Thanks for helping out, superb info .
Youre so cool! I dont suppose Ive learn something like this before. So good to seek out someone with some original ideas on this subject. realy thank you for starting this up. this web site is one thing that’s needed on the net, somebody with slightly originality. useful job for bringing one thing new to the internet!
Definitely believe that which you said. Your favorite reason appeared to be on the internet the easiest thing to be aware of. I say to you, I definitely get annoyed while people think about worries that they plainly do not know about. You managed to hit the nail upon the top and defined out the whole thing without having side effect , people could take a signal. Will likely be back to get more. Thanks
You are a very bright person!
I have recently started a blog, the information you provide on this website has helped me greatly. Thank you for all of your time & work.
I cherished as much as you’ll obtain performed proper here. The cartoon is attractive, your authored subject matter stylish. nonetheless, you command get bought an shakiness over that you want be turning in the following. in poor health certainly come more previously once more as precisely the same nearly very steadily within case you protect this hike.
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but other than that, this is wonderful blog. A great read. I will definitely be back.
hello!,I really like your writing very a lot! proportion we be in contact extra approximately your article on AOL? I require a specialist in this space to unravel my problem. Maybe that’s you! Having a look ahead to peer you.
I haven¦t checked in here for a while since I thought it was getting boring, but the last few posts are good quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
I like this blog very much, Its a rattling nice office to read and obtain information.
I’ll immediately take hold of your rss feed as I can not to find your e-mail subscription link or newsletter service. Do you have any? Please allow me recognize so that I could subscribe. Thanks.
Please let me know if you’re looking for a article writer for your blog. You have some really good articles and I feel I would be a good asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to mine. Please shoot me an email if interested. Many thanks!
you are really a good webmaster. The site loading speed is incredible. It seems that you’re doing any unique trick. Also, The contents are masterwork. you’ve done a magnificent job on this topic!
Hey there! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
I¦ve been exploring for a little for any high-quality articles or blog posts in this kind of space . Exploring in Yahoo I ultimately stumbled upon this site. Reading this information So i am satisfied to exhibit that I have an incredibly good uncanny feeling I came upon exactly what I needed. I such a lot definitely will make certain to don¦t put out of your mind this web site and provides it a glance on a constant basis.
Great site. A lot of useful information here. I am sending it to a few friends ans also sharing in delicious. And naturally, thanks for your sweat!
Do you have a spam issue on this website; I also am a blogger, and I was wondering your situation; many of us have created some nice methods and we are looking to trade solutions with others, be sure to shoot me an email if interested.
Great post. I was checking continuously this blog and I’m impressed! Very useful information specially the last part 🙂 I care for such information much. I was looking for this certain information for a very long time. Thank you and good luck.
Wow, wonderful blog layout! How lengthy have you ever been running a blog for? you make blogging look easy. The whole glance of your website is wonderful, let alone the content!
Thanks for helping out, superb information. “A man will fight harder for his interests than for his rights.” by Napoleon Bonaparte.
Hello very nice website!! Man .. Excellent .. Superb .. I will bookmark your site and take the feeds also…I’m satisfied to find numerous helpful info here within the put up, we want work out extra strategies in this regard, thank you for sharing. . . . . .
Keep working ,remarkable job!
Heya! I’m at work browsing your blog from my new iphone 3gs! Just wanted to say I love reading through your blog and look forward to all your posts! Keep up the outstanding work!
Love the convenience of k8app. Everything I need right on my phone. Get the app here: k8app
Anyone know if the Royal Win game download takes up a ton of space on your phone Space is tight so I’m trying to figure out if it’s worth it. royal win game download
luk.88, yeah I’ve seen that one around! It just takes you to the main site so why not pop over and see what’s going down. You may be pleasantly surprised. Browse it at luk.88
Exceptional post however I was wanting to know if you could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit more. Appreciate it!
I think this web site has got very good indited content posts.
Wow! Thank you! I continually wanted to write on my website something like that. Can I include a part of your post to my site?
We absolutely love your blog and find a lot of your post’s to be just what I’m looking for. can you offer guest writers to write content for yourself? I wouldn’t mind publishing a post or elaborating on a lot of the subjects you write regarding here. Again, awesome site!
Yay google is my world beater assisted me to find this outstanding web site! .
Hi there! I know this is kinda off topic nevertheless I’d figured I’d ask. Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa? My blog covers a lot of the same subjects as yours and I think we could greatly benefit from each other. If you are interested feel free to send me an email. I look forward to hearing from you! Terrific blog by the way!
I like what you guys are up also. Such clever work and reporting! Carry on the excellent works guys I?¦ve incorporated you guys to my blogroll. I think it’ll improve the value of my site 🙂
Valuable info. Lucky me I found your web site unintentionally, and I am surprised why this coincidence did not took place earlier! I bookmarked it.
Hello very cool site!! Man .. Excellent .. Wonderful .. I’ll bookmark your web site and take the feeds additionally…I am satisfied to seek out so many helpful information right here within the post, we’d like work out more strategies in this regard, thank you for sharing.
You should take part in a contest for one of the best blogs on the web. I will suggest this website!
At this time it seems like WordPress is the preferred blogging platform out there right now. (from what I’ve read) Is that what you are using on your blog?
I’m not that much of a online reader to be honest but your sites really nice, keep it up! I’ll go ahead and bookmark your site to come back down the road. Cheers
It’s a shame you don’t have a donate button! I’d certainly donate to this superb blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account. I look forward to new updates and will share this site with my Facebook group. Chat soon!
My coder is trying to persuade me to move to .net from PHP. I have always disliked the idea because of the costs. But he’s tryiong none the less. I’ve been using WordPress on a number of websites for about a year and am nervous about switching to another platform. I have heard fantastic things about blogengine.net. Is there a way I can transfer all my wordpress content into it? Any help would be greatly appreciated!
What up 68win1? Not bad. Not bad at all. Pretty good fun. 68win1
Looking for a solid ‘Bet Esporte’ platform? I’ve been having a good run here. Good odds and a variety of sports to choose from. Check it out bet esporte!
Hi365bet, hmm… Trying out new platforms now, checking the payout odds now! Let’s see where this takes me… Learn more clicking here: hi365bet
I’ve read several just right stuff here. Definitely price bookmarking for revisiting. I surprise how a lot effort you place to make this sort of wonderful informative web site.
It’s in point of fact a great and useful piece of info. I am glad that you simply shared this helpful information with us. Please stay us informed like this. Thanks for sharing.
Thank you, I’ve recently been searching for info approximately this topic for ages and yours is the greatest I’ve found out so far. But, what concerning the conclusion? Are you sure in regards to the supply?
Oh my goodness! an incredible article dude. Thanks Nonetheless I am experiencing problem with ur rss . Don’t know why Unable to subscribe to it. Is there anybody getting an identical rss problem? Anybody who is aware of kindly respond. Thnkx
Hello there! I know this is kind of off topic but I was wondering which blog platform are you using for this site? I’m getting sick and tired of WordPress because I’ve had problems with hackers and I’m looking at options for another platform. I would be fantastic if you could point me in the direction of a good platform.
Thanks for another informative website. Where else could I get that type of information written in such an ideal way? I have a project that I am just now working on, and I’ve been on the look out for such information.
Normally I do not read article on blogs, but I wish to say that this write-up very forced me to try and do so! Your writing style has been amazed me. Thanks, very nice post.
I believe you have mentioned some very interesting details , appreciate it for the post.
It’s hard to find knowledgeable people on this topic, but you sound like you know what you’re talking about! Thanks
Simply a smiling visitor here to share the love (:, btw outstanding layout.
The next time I read a weblog, I hope that it doesnt disappoint me as a lot as this one. I mean, I know it was my option to learn, however I truly thought youd have something fascinating to say. All I hear is a bunch of whining about something that you could possibly fix should you werent too busy on the lookout for attention.
I like this post, enjoyed this one regards for posting.
Enjoyed looking through this, very good stuff, appreciate it. “All of our dreams can come true — if we have the courage to pursue them.” by Walt Disney.
F*ckin¦ amazing issues here. I¦m very glad to look your article. Thank you so much and i’m taking a look forward to touch you. Will you please drop me a mail?
Thanks, I’ve recently been searching for information approximately this subject for ages and yours is the greatest I have found out so far. But, what in regards to the bottom line? Are you sure about the source?
I believe you have noted some very interesting points, thankyou for the post.
I haven’t checked in here for a while since I thought it was getting boring, but the last few posts are great quality so I guess I’ll add you back to my everyday bloglist. You deserve it my friend 🙂
I was recommended this web site through my cousin. I’m not sure whether this submit is written by him as nobody else understand such particular about my trouble. You are amazing! Thanks!
I am curious to find out what blog system you happen to be utilizing? I’m having some small security problems with my latest blog and I would like to find something more safeguarded. Do you have any recommendations?
Very interesting topic, regards for posting.
Nice post. I was checking constantly this blog and I am impressed! Extremely useful info specially the last part 🙂 I care for such info a lot. I was looking for this certain info for a very long time. Thank you and best of luck.
I just couldn’t depart your website prior to suggesting that I really enjoyed the standard info a person provide for your visitors? Is going to be back often to check up on new posts
Would you be excited by exchanging links?
This is very attention-grabbing, You are a very professional blogger. I’ve joined your rss feed and sit up for in search of extra of your fantastic post. Additionally, I have shared your site in my social networks!
Wow! Thank you! I constantly needed to write on my website something like that. Can I implement a fragment of your post to my site?
Utterly pent content material, Really enjoyed examining.
I don’t even know how I ended up here, but I thought this post was great. I do not know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
Just wish to say your article is as amazing. The clarity in your publish is simply cool and that i can think you are a professional on this subject. Well along with your permission let me to grasp your RSS feed to keep updated with forthcoming post. Thanks one million and please continue the gratifying work.
I¦ve been exploring for a little bit for any high quality articles or weblog posts in this kind of area . Exploring in Yahoo I at last stumbled upon this website. Reading this info So i am happy to show that I have a very just right uncanny feeling I found out just what I needed. I so much undoubtedly will make sure to do not overlook this site and give it a glance on a constant basis.
Well I really enjoyed studying it. This tip provided by you is very practical for correct planning.
I genuinely treasure your piece of work, Great post.
Greetings! I know this is somewhat off topic but I was wondering which blog platform are you using for this site? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform. I would be awesome if you could point me in the direction of a good platform.
Thank you for the sensible critique. Me and my neighbor were just preparing to do a little research about this. We got a grab a book from our local library but I think I learned more from this post. I’m very glad to see such excellent information being shared freely out there.
Very well written story. It will be useful to everyone who employess it, including me. Keep up the good work – looking forward to more posts.
This blog is definitely rather handy since I’m at the moment creating an internet floral website – although I am only starting out therefore it’s really fairly small, nothing like this site. Can link to a few of the posts here as they are quite. Thanks much. Zoey Olsen
What i do not realize is in fact how you are not actually a lot more smartly-appreciated than you might be right now. You’re so intelligent. You recognize therefore considerably on the subject of this topic, made me in my opinion consider it from a lot of numerous angles. Its like women and men don’t seem to be interested until it¦s one thing to accomplish with Girl gaga! Your individual stuffs excellent. Always maintain it up!
Great paintings! This is the type of information that should be shared around the web. Shame on the seek engines for now not positioning this publish upper! Come on over and consult with my web site . Thank you =)
Great write-up, I am normal visitor of one¦s blog, maintain up the excellent operate, and It’s going to be a regular visitor for a long time.
Hello there, You’ve performed an incredible job. I will definitely digg it and individually suggest to my friends. I’m sure they will be benefited from this website.
Thank you for every other wonderful post. The place else may just anyone get that type of information in such an ideal approach of writing? I’ve a presentation subsequent week, and I am at the search for such info.
Yeah bookmaking this wasn’t a risky decision great post! .
Way cool, some valid points! I appreciate you making this article available, the rest of the site is also high quality. Have a fun.
I¦ve recently started a web site, the information you offer on this site has helped me greatly. Thank you for all of your time & work.
Hello.This article was extremely motivating, particularly because I was searching for thoughts on this matter last couple of days.
Okay, getting into gbet777 is easy peasy. The gbet777 login process is straightforward and I’ve had zero issues. Jump in and hit that login button at gbet777 login
Alright, ph789…heard whispers…Gave it a shot and it wasn’t bad. Some okay games and a decent vibe. Worth a look if you’re bored. Just sayin’! ph789
Playcity Casino is a solid choice for online gaming. Loads of different games to check out and a generally good vibe. Give it a spin! You might just get lucky. playcity casino
Just a smiling visitor here to share the love (:, btw great design and style. “Better by far you should forget and smile than that you should remember and be sad.” by Christina Georgina Rossetti.
hi!,I like your writing so a lot! percentage we be in contact more approximately your post on AOL? I need a specialist on this house to resolve my problem. May be that’s you! Taking a look forward to see you.
I reckon something really special in this website.
I’ve read a few good stuff here. Certainly price bookmarking for revisiting. I wonder how a lot effort you put to create the sort of magnificent informative web site.
This is very interesting, You are a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your great post. Also, I have shared your website in my social networks!
My brother recommended I might like this website. He was totally right. This post truly made my day. You cann’t imagine simply how much time I had spent for this information! Thanks!
Nice post. I was checking continuously this blog and I’m inspired! Very helpful info specifically the last phase 🙂 I maintain such info a lot. I was seeking this particular info for a very lengthy time. Thanks and best of luck.
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
I genuinely enjoy looking at on this site, it holds fantastic content. “Heavier-than-air flying machines are impossible.” by Lord Kelvin.
Woh I enjoy your content, saved to fav! .
Whats up! I simply wish to give an enormous thumbs up for the good data you’ve here on this post. I will likely be coming back to your blog for extra soon.
Enjoyed examining this, very good stuff, regards. “Golf isn’t a game, it’s a choice that one makes with one’s life.” by Charles Rosin.
In this awesome pattern of things you secure a B+ just for effort. Where exactly you lost me was in the facts. You know, it is said, the devil is in the details… And that couldn’t be more correct in this article. Having said that, allow me reveal to you precisely what did give good results. The article (parts of it) is really persuasive and that is possibly why I am taking an effort in order to opine. I do not make it a regular habit of doing that. 2nd, despite the fact that I can certainly notice a leaps in logic you make, I am not necessarily convinced of exactly how you appear to connect your ideas which inturn make the actual conclusion. For right now I will yield to your position but hope in the foreseeable future you actually connect the facts better.
I just could not leave your web site before suggesting that I actually enjoyed the standard information a person provide in your guests? Is going to be again continuously in order to inspect new posts
I really appreciate this post. I have been looking all over for this! Thank goodness I found it on Bing. You have made my day! Thank you again
Woah! I’m really enjoying the template/theme of this website. It’s simple, yet effective. A lot of times it’s challenging to get that “perfect balance” between usability and appearance. I must say you’ve done a very good job with this. In addition, the blog loads super quick for me on Firefox. Exceptional Blog!
he blog was how do i say it… relevant, finally something that helped me. Thanks
Greetings! Very helpful advice on this article! It is the little changes that make the biggest changes. Thanks a lot for sharing!
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and create my own. Do you require any html coding expertise to make your own blog? Any help would be really appreciated!
I’m still learning from you, but I’m making my way to the top as well. I definitely liked reading all that is written on your website.Keep the aarticles coming. I loved it!
so much excellent information on here, :D.
You have brought up a very fantastic details, thankyou for the post.
Wow, superb weblog format! How lengthy have you ever been blogging for? you make running a blog look easy. The overall look of your website is excellent, let alone the content!
I am lucky that I noticed this web site, exactly the right information that I was searching for! .
Well I truly enjoyed reading it. This tip procured by you is very helpful for good planning.
I like this web site very much, Its a really nice berth to read and obtain information. “There are two ways of spreading light to be the candle or the mirror that reflects it.” by Edith Newbold Jones Wharton.
Hiya very nice blog!! Guy .. Beautiful .. Amazing .. I will bookmark your blog and take the feeds also…I am satisfied to find so many useful info here in the post, we’d like develop more strategies in this regard, thank you for sharing. . . . . .
Thanks a bunch for sharing this with all of us you really know what you are talking about! Bookmarked. Please also visit my web site =). We could have a link exchange arrangement between us!
Howdy very cool website!! Guy .. Excellent .. Superb .. I will bookmark your website and take the feeds additionally…I am happy to find numerous useful info here within the publish, we’d like develop more strategies on this regard, thanks for sharing. . . . . .
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
I real thankful to find this website on bing, just what I was searching for : D besides saved to my bookmarks.
Very interesting subject , regards for putting up.
Great amazing issues here. I’m very glad to peer your post. Thanks a lot and i am looking forward to touch you. Will you kindly drop me a e-mail?
Thank you, I’ve recently been looking for information about this topic for ages and yours is the greatest I’ve discovered so far. But, what about the conclusion? Are you sure about the source?
I conceive you have noted some very interesting points, thankyou for the post.
The subsequent time I learn a weblog, I hope that it doesnt disappoint me as a lot as this one. I mean, I know it was my choice to learn, but I truly thought youd have something attention-grabbing to say. All I hear is a bunch of whining about one thing that you may repair if you happen to werent too busy on the lookout for attention.
Its great as your other posts : D, regards for posting. “Reason is the substance of the universe. The design of the world is absolutely rational.” by Georg Wilhelm Friedrich Hegel.
Alright, giving 25phwinvip.net a shot. Hoping for that VIP treatment! Seems promising so far. Wish me luck! You can try too : 25phwinvip
Popped over to phwin25.net to see what’s up. It’s alright! Maybe it’ll be your lucky day. You can win here: phwin25
Just used okebet4login.com to sign in. Super simple! Ready to play. Maybe you wanna give it a whirl?: okebet4login
Some truly prize articles on this website , saved to fav.
I got good info from your blog
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post…
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
My wife and i were so excited Albert managed to finish up his reports out of the precious recommendations he received out of the weblog. It’s not at all simplistic to just always be offering hints which usually many others might have been making money from. We recognize we have the writer to appreciate because of that. The type of illustrations you’ve made, the easy site menu, the friendships you aid to foster – it’s mostly wonderful, and it is leading our son and us believe that the topic is enjoyable, which is incredibly vital. Thanks for everything!
Glad to be one of several visitors on this awing website : D.
It’s a shame you don’t have a donate button! I’d certainly donate to this outstanding blog! I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account. I look forward to brand new updates and will talk about this site with my Facebook group. Chat soon!
Wow, wonderful blog layout! How long have you been blogging for? you make blogging look easy. The overall look of your website is fantastic, as well as the content!
hi!,I like your writing very a lot! proportion we keep in touch extra approximately your post on AOL? I need an expert in this area to resolve my problem. May be that is you! Looking ahead to look you.
I was just searching for this info for a while. After 6 hours of continuous Googleing, finally I got it in your web site. I wonder what is the lack of Google strategy that do not rank this kind of informative websites in top of the list. Generally the top web sites are full of garbage.
Wow! This can be one particular of the most helpful blogs We have ever arrive across on this subject. Basically Magnificent. I’m also an expert in this topic therefore I can understand your effort.
I really wanted to type a small remark so as to express gratitude to you for all the splendid points you are sharing on this site. My time-consuming internet search has at the end been recognized with reasonable points to share with my friends and family. I would assume that most of us website visitors actually are definitely lucky to live in a perfect website with very many brilliant people with useful tips. I feel extremely fortunate to have seen the webpage and look forward to many more thrilling times reading here. Thanks once again for a lot of things.
I was reading some of your articles on this site and I think this site is very informative! Continue putting up.
Fantastic web site. Plenty of useful info here. I’m sending it to some friends ans additionally sharing in delicious. And naturally, thanks in your sweat!
Hey very cool web site!! Guy .. Excellent .. Wonderful .. I will bookmark your site and take the feeds additionally…I am happy to search out a lot of helpful info right here in the publish, we’d like develop more techniques on this regard, thank you for sharing.
I haven’t checked in here for a while since I thought it was getting boring, but the last few posts are good quality so I guess I’ll add you back to my daily bloglist. You deserve it my friend 🙂
You are my inspiration , I have few blogs and rarely run out from to brand : (.
I visited a lot of website but I conceive this one has something extra in it in it
I have been surfing online more than three hours today, yet I never found any interesting article like yours. It’s pretty worth enough for me. Personally, if all web owners and bloggers made good content as you did, the web will be a lot more useful than ever before.
Hmm is anyone else experiencing problems with the pictures on this blog loading? I’m trying to find out if its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
I was recommended this web site by my cousin. I’m not sure whether this post is written by him as nobody else know such detailed about my difficulty. You are wonderful! Thanks!
Interesting read! Seeing consistent patterns is key in baccarat, much like a solid platform is essential for play. I’ve been checking out bw29 legit – seems legit & user-friendly, especially with their verification process. Good stuff!
Does your site have a contact page? I’m having a tough time locating it but, I’d like to send you an email. I’ve got some creative ideas for your blog you might be interested in hearing. Either way, great website and I look forward to seeing it grow over time.
As a Newbie, I am permanently browsing online for articles that can aid me. Thank you
Hmm is anyone else having problems with the pictures on this blog loading? I’m trying to find out if its a problem on my end or if it’s the blog. Any responses would be greatly appreciated.
Hi my family member! I want to say that this article is awesome, great written and come with almost all vital infos. I’d like to see more posts like this.
Merely wanna tell that this is very useful, Thanks for taking your time to write this.
Hi there, I discovered your web site by means of Google even as looking for a similar subject, your web site came up, it seems great. I’ve bookmarked it in my google bookmarks.
I conceive you have observed some very interesting points, appreciate it for the post.
You made some clear points there. I did a search on the subject and found most individuals will approve with your website.
Well I sincerely enjoyed studying it. This tip provided by you is very effective for proper planning.
Do you have a spam issue on this blog; I also am a blogger, and I was curious about your situation; we have created some nice procedures and we are looking to trade solutions with other folks, please shoot me an e-mail if interested.
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
Wow that was odd. I just wrote an incredibly long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Regardless, just wanted to say superb blog!
Hi! Someone in my Facebook group shared this site with us so I came to look it over. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers! Wonderful blog and brilliant style and design.
Hi there, i read your blog from time to time and i own a similar one and i was just curious if you get a lot of spam feedback? If so how do you prevent it, any plugin or anything you can recommend? I get so much lately it’s driving me mad so any help is very much appreciated.
It’s really a nice and helpful piece of information. I’m glad that you shared this helpful info with us. Please keep us informed like this. Thanks for sharing.
Outstanding post however , I was wanting to know if you could write a litte more on this subject? I’d be very thankful if you could elaborate a little bit more. Thanks!
I love the efforts you have put in this, thankyou for all the great posts.
Interesting points about maintaining player trust – crucial in online gaming! Seeing platforms like bigbunny apk slot prioritize RNG verification (96.8% RTP!) and uptime is a good sign for a stable experience. It’s all about the tech foundation!
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four e-mails with the same comment. Is there any way you can remove me from that service? Thanks!
Thanks for the good writeup. It in fact used to be a enjoyment account it. Glance advanced to more added agreeable from you! However, how could we keep in touch?
Thanks for helping out, fantastic info. “Our individual lives cannot, generally, be works of art unless the social order is also.” by Charles Horton Cooley.
I’ll immediately clutch your rss feed as I can’t to find your email subscription hyperlink or e-newsletter service. Do you’ve any? Kindly let me recognise in order that I may subscribe. Thanks.
I was very pleased to find this web-site.I wanted to thanks for your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
Magnificent beat ! I would like to apprentice while you amend your website, how can i subscribe for a weblog web site? The account aided me a applicable deal. I had been tiny bit acquainted of this your broadcast provided bright clear idea
I do trust all of the ideas you have presented to your post. They’re very convincing and can certainly work. Still, the posts are too quick for newbies. May you please prolong them a little from subsequent time? Thank you for the post.
Hi! I’m at work browsing your blog from my new iphone 3gs! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the great work!
Hello.This post was extremely interesting, particularly since I was browsing for thoughts on this matter last week.
What i don’t realize is in reality how you’re no longer actually a lot more neatly-preferred than you might be now. You’re so intelligent. You understand thus considerably relating to this matter, produced me personally believe it from so many various angles. Its like women and men are not involved except it is something to accomplish with Lady gaga! Your personal stuffs outstanding. Always deal with it up!
Together with every thing which appears to be building within this particular subject matter, your points of view are generally rather radical. Having said that, I appologize, but I can not subscribe to your entire idea, all be it exciting none the less. It appears to us that your remarks are actually not completely rationalized and in actuality you are generally yourself not entirely confident of your argument. In any case I did enjoy reading through it.
Hiya very cool blog!! Man .. Beautiful .. Superb .. I will bookmark your blog and take the feeds additionallyKI am happy to seek out numerous useful info here within the post, we need work out more strategies in this regard, thank you for sharing. . . . . .
After examine just a few of the weblog posts in your website now, and I truly like your approach of blogging. I bookmarked it to my bookmark web site list and shall be checking again soon. Pls take a look at my site as nicely and let me know what you think.
I have not checked in here for a while since I thought it was getting boring, but the last several posts are great quality so I guess I’ll add you back to my everyday bloglist. You deserve it my friend 🙂
Hi, Neat post. There’s an issue with your web site in web explorer, could test this?K IE still is the market leader and a huge section of other folks will miss your fantastic writing because of this problem.
This web site is really a walk-through for all of the info you wanted about this and didn’t know who to ask. Glimpse here, and you’ll definitely discover it.
Hello, you used to write wonderful, but the last few posts have been kinda boringK I miss your great writings. Past few posts are just a little bit out of track! come on!
I gotta bookmark this site it seems very beneficial very beneficial
Hey very cool web site!! Man .. Excellent .. Amazing .. I will bookmark your blog and take the feeds also…I’m happy to find a lot of useful information here in the post, we need work out more techniques in this regard, thanks for sharing. . . . . .
Hi, I think your site might be having browser compatibility issues. When I look at your website in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, fantastic blog!
Good info. Lucky me I reach on your website by accident, I bookmarked it.
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
Appreciate it for this post, I am a big fan of this site would like to proceed updated.
Alright, so I gave Win888xsmb a whirl. Interface is clean and easy to navigate, which is a big plus for me. The games were fun and I actually managed to win a few bucks. See for yourself: win888xsmb
Alright gamers, anyone tried in7apkgame yet? Snagged a few games from there, pretty smooth experience. Check it out for yourself here: in7apkgame
Logging into my777 is a breeze thanks to my777login. Saved myself a headache. Definitely worth bookmarking: my777login
This is really interesting, You are a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your excellent post. Also, I have shared your site in my social networks!
Good, I should certainly pronounce, impressed with your website. I had no trouble navigating through all the tabs and related info ended up being truly simple to do to access. I recently found what I hoped for before you know it at all. Reasonably unusual. Is likely to appreciate it for those who add forums or anything, website theme . a tones way for your client to communicate. Excellent task.
Good info. Lucky me I reach on your website by accident, I bookmarked it.
Hello, Neat post. There’s a problem together with your web site in web explorer, would check this?K IE still is the marketplace leader and a huge section of other people will miss your wonderful writing due to this problem.
We are a group of volunteers and starting a new scheme in our community. Your site offered us with valuable info to work on. You’ve performed an impressive activity and our whole group will likely be grateful to you.
Absolutely composed content, Really enjoyed reading through.
I enjoy the efforts you have put in this, thanks for all the great posts.
The very heart of your writing while sounding agreeable at first, did not really work perfectly with me personally after some time. Someplace within the paragraphs you actually managed to make me a believer unfortunately only for a short while. I still have got a problem with your jumps in logic and you might do well to fill in all those breaks. If you can accomplish that, I will undoubtedly be impressed.
naturally like your web site but you need to take a look at the spelling on quite a few of your posts. Several of them are rife with spelling issues and I to find it very troublesome to tell the truth however I will surely come back again.
I’ve recently started a site, the info you offer on this site has helped me tremendously. Thank you for all of your time & work. “Cultivation to the mind is as necessary as food to the body.” by Marcus Tullius Cicero.
Hello very nice blog!! Guy .. Beautiful .. Wonderful .. I’ll bookmark your web site and take the feeds additionally?KI’m glad to find so many useful info here in the publish, we’d like develop extra strategies in this regard, thanks for sharing. . . . . .
Hi my friend! I want to say that this post is amazing, great written and include almost all significant infos. I’d like to look extra posts like this .
I am glad to be one of several visitants on this outstanding website (:, thankyou for posting.
I discovered your blog website on google and examine a couple of of your early posts. Continue to maintain up the excellent operate. I simply extra up your RSS feed to my MSN News Reader. Seeking ahead to reading more from you later on!…
Some really wondrous work on behalf of the owner of this internet site, perfectly outstanding content.
I really like assembling useful info, this post has got me even more info! .
I couldn’t resist commenting
I carry on listening to the newscast lecture about receiving free online grant applications so I have been looking around for the finest site to get one. Could you advise me please, where could i acquire some?
Thanks a bunch for sharing this with all people you really recognize what you are talking about! Bookmarked. Kindly also talk over with my website =). We will have a link change agreement among us!
You actually make it seem so easy with your presentation but I find this topic to be actually something which I think I would never understand. It seems too complex and very broad for me. I am looking forward for your next post, I’ll try to get the hang of it!
Some really nice and useful info on this website, likewise I think the design has got good features.
Deference to post author, some superb information .
My brother recommended I might like this website. He was totally right. This post actually made my day. You can not imagine just how much time I had spent for this info! Thanks!
You have brought up a very wonderful details, regards for the post.
I rattling lucky to find this site on bing, just what I was looking for : D as well bookmarked.
Having read this I thought it was very informative. I appreciate you taking the time and effort to put this article together. I once again find myself spending way to much time both reading and commenting. But so what, it was still worth it!
Thanks for ones marvelous posting! I certainly enjoyed reading it, you will be a great author.I will remember to bookmark your blog and will eventually come back at some point. I want to encourage yourself to continue your great writing, have a nice holiday weekend!
you have a great blog here! would you like to make some invite posts on my blog?
Hello, you used to write excellent, but the last several posts have been kinda boringK I miss your great writings. Past several posts are just a little out of track! come on!
Lovely website! I am loving it!! Will be back later to read some more. I am taking your feeds also
I think this website has some very great info for everyone :D.
Hi my loved one! I want to say that this article is amazing, nice written and come with almost all significant infos. I’d like to peer more posts like this .
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
Hello! Would you mind if I share your blog with my twitter group? There’s a lot of people that I think would really appreciate your content. Please let me know. Thanks
hey there and thank you for your information – I have definitely picked up anything new from proper here. I did however experience some technical issues the use of this website, as I experienced to reload the website many times prior to I may just get it to load properly. I have been pondering if your web hosting is OK? Now not that I am complaining, but sluggish loading instances times will often have an effect on your placement in google and could harm your high-quality score if advertising and ***********|advertising|advertising|advertising and *********** with Adwords. Anyway I’m adding this RSS to my e-mail and can glance out for a lot more of your respective interesting content. Ensure that you update this once more very soon..
Dead indited subject matter, Really enjoyed looking at.
Hmm is anyone else encountering problems with the pictures on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated.
hello!,I like your writing very much! share we keep in touch more about your article on AOL? I require a specialist on this area to solve my problem. Maybe that is you! Having a look ahead to look you.
Today, I went to the beach with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
Real great info can be found on web blog.
I used to be very happy to search out this web-site.I wanted to thanks for your time for this wonderful learn!! I undoubtedly having fun with each little little bit of it and I’ve you bookmarked to take a look at new stuff you weblog post.
Some really interesting info , well written and broadly speaking user friendly.
I don’t commonly comment but I gotta tell thanks for the post on this amazing one :D.
The next time I read a blog, I hope that it doesnt disappoint me as much as this one. I mean, I know it was my choice to read, but I actually thought youd have something interesting to say. All I hear is a bunch of whining about something that you could fix if you werent too busy looking for attention.
I don’t even know the way I stopped up here, but I thought this submit used to be good. I do not recognise who you might be however definitely you are going to a well-known blogger if you happen to are not already 😉 Cheers!
Really superb visual appeal on this web site, I’d value it 10 10.
I want to show my respect for your kind-heartedness for folks that require guidance on this important study. Your very own dedication to passing the message throughout was astonishingly effective and have all the time made regular people much like me to arrive at their aims. Your entire useful guideline implies a great deal to me and somewhat more to my office workers. Thanks a ton; from all of us.
When I originally commented I clicked the -Notify me when new comments are added- checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Thanks!
There is clearly a bunch to realize about this. I consider you made various good points in features also.
Hi my friend! I want to say that this article is amazing, nice written and include approximately all important infos. I would like to see more posts like this.
Its fantastic as your other content : D, regards for putting up. “Talent does what it can genius does what it must.” by Edward George Bulwer-Lytton.
I think this website has some really good info for everyone. “I prefer the wicked rather than the foolish. The wicked sometimes rest.” by Alexandre Dumas.
I do like the manner in which you have presented this challenge and it does offer us a lot of fodder for consideration. On the other hand, because of what precisely I have personally seen, I really wish when the responses stack on that people keep on issue and in no way embark upon a tirade of some other news of the day. Anyway, thank you for this excellent point and while I do not necessarily go along with it in totality, I regard the perspective.
Very nice post. I just stumbled upon your blog and wanted to say that I have really enjoyed surfing around your blog posts. After all I’ll be subscribing to your feed and I hope you write again very soon!
You are my aspiration, I own few blogs and rarely run out from to brand : (.
Very good written information. It will be supportive to anybody who employess it, as well as yours truly :). Keep up the good work – looking forward to more posts.
An interesting discussion is worth comment. I think that you should write more on this topic, it might not be a taboo subject but generally people are not enough to speak on such topics. To the next. Cheers
It’s really a cool and useful piece of information. I am glad that you shared this helpful information with us. Please keep us up to date like this. Thanks for sharing.
Hello, I think your blog might be having browser compatibility issues. When I look at your website in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, great blog!
Very interesting information!Perfect just what I was searching for!
Some really excellent info , Glad I noticed this.
WONDERFUL Post.thanks for share..more wait .. …
Howdy! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
My brother suggested I might like this web site. He was entirely right. This post truly made my day. You cann’t imagine just how much time I had spent for this info! Thanks!
My developer is trying to convince me to move to .net from PHP. I have always disliked the idea because of the expenses. But he’s tryiong none the less. I’ve been using Movable-type on a number of websites for about a year and am anxious about switching to another platform. I have heard good things about blogengine.net. Is there a way I can transfer all my wordpress posts into it? Any help would be really appreciated!
I like what you guys are up too. Such smart work and reporting! Carry on the superb works guys I’ve incorporated you guys to my blogroll. I think it’ll improve the value of my website :).
This is the right blog for anyone who wants to find out about this topic. You realize so much its almost hard to argue with you (not that I actually would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great!
Rattling nice design and style and fantastic written content, absolutely nothing else we require :D.
Hello, you used to write wonderful, but the last several posts have been kinda boring… I miss your super writings. Past few posts are just a bit out of track! come on!
An impressive share, I just given this onto a colleague who was doing slightly analysis on this. And he in reality bought me breakfast as a result of I found it for him.. smile. So let me reword that: Thnx for the treat! However yeah Thnkx for spending the time to discuss this, I really feel strongly about it and love reading extra on this topic. If doable, as you become experience, would you mind updating your blog with extra particulars? It’s highly helpful for me. Huge thumb up for this weblog put up!
Youre so cool! I dont suppose Ive learn anything like this before. So good to find someone with some original ideas on this subject. realy thanks for starting this up. this website is one thing that’s needed on the web, somebody with a bit of originality. useful job for bringing something new to the internet!
I have not checked in here for some time because I thought it was getting boring, but the last few posts are great quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
I really value your piece of work, Great post.
Good write-up, I’m normal visitor of one’s blog, maintain up the excellent operate, and It is going to be a regular visitor for a long time.
I am glad to be one of the visitants on this outstanding internet site (:, thankyou for putting up.
I am typically to blogging and i really admire your content. The article has actually peaks my interest. I am going to bookmark your website and keep checking for brand spanking new information.