
Logstash is an open-source data processing pipeline that ingests data from various sources, transforms it, and then sends it to a destination of your choice, typically Elasticsearch, for storage and analysis. Logstash is part of the Elastic Stack, along with Elasticsearch and Kibana, and is commonly used for log and event data collection and processing.
Capabilities of Logstash include:
• Data Ingestion: Logstash supports various input plugins to ingest data from different sources such as files, databases, message queues, and network protocols.
• Data Transformation: Logstash provides a wide range of filter plugins for transforming and enriching data. These filters can perform tasks like parsing, grokking, geoip lookup, anonymization, and more.
• Data Output: Logstash supports various output plugins to send processed data to different destinations such as Elasticsearch, Amazon S3, Kafka, and many others.
• Pipeline Processing: Logstash allows you to define complex data processing pipelines with multiple stages for ingestion, transformation, and output.
• Scalability: Logstash can be scaled horizontally to handle large volumes of data by distributing workload across multiple instances.
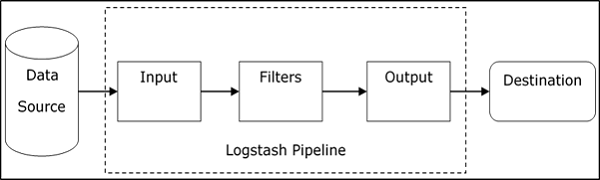
Logstash Service Architecture
Logstash processes logs from different servers and data sources and it behaves as the shipper. The shippers are used to collect the logs and these are installed in every input source. Brokers like Redis, Kafka or RabbitMQ are buffers to hold the data for indexers, there may be more than one broker as failed instances.
Indexers like Lucene are used to index the logs for better search performance and then the output is stored in Elasticsearch or other output destination. The data in output storage is available for Kibana and other visualization software.

Logstash Internal Architecture
The Logstash pipeline consists of three components Input, Filters and Output. The input part is responsible to specify and access the input data source such as the log folder of the Apache Tomcat Server.
Common Syntax
The Logstash configuration file just copies the data from the inlog.log file using the input plugin and flushes the log data to outlog.log file using the output plugin.
Syntax:
file {
path => "C:/tpwork/logstash/bin/log/inlog.log"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/outlog.log"
}
}
Cmd Run Logstash
Logstash uses –f option to specify the config file.

Problem Statement:
There was a need to synchronize various tables in Elasticsearch to enable search functionality. However, each time a new index had to be created, it required writing custom code, which was time-consuming and often tedious.
Solution:
Thanks to Logstash, this process can now be accomplished quickly and easily. Logstash allows us to sync multiple tables effortlessly through its pipeline configuration.
EXPLAINING SAMPLE CONFIG
Now let’s break down the provided Logstash configuration:
jdbc {
jdbc_driver_library => "\path\mysql-connector-j-8.1.0\mysql-connector-j-8.1.0.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/database"
jdbc_user => "root"
jdbc_password => "root"
schedule => "*/2 * * * *"
statement => "SELECT * FROM table_name
WHERE id > :sql_last_value limit 100; "
use_column_value => true
tracking_column => "id"
tracking_column_type => "numeric"
last_run_metadata_path => "\path\z_index_one.txt"
tags => ["table_name"]
jdbc_default_timezone => "UTC"
}
}
output {
if "table_name" in [tags] {
elasticsearch {
hosts => ["http://localhost:9200/"]
index => "index_name"
document_id => "%{id}"
}
}
}
Output:
Specifies the input source for Logstash. In this case, it’s using the jdbc input plugin, which allows Logstash to query a JDBC database.
- jdbc_driver_library: Path to the JDBC driver library.
- jdbc_driver_class: JDBC driver class name.
- jdbc_connection_string: JDBC connection string to the database.
- jdbc_user: Username for database authentication.
- jdbc_password: Password for database authentication.
- schedule: Cron expression defining how often the SQL query should be executed.
- statement: SQL query to execute. :sql_last_value is a Logstash parameter used for incremental fetching.
- use_column_value: Specifies whether to use the last value of the tracking column.
- tracking_column: Column used for tracking incremental changes.
- tracking_column_type: Data type of the tracking column.
- last_run_metadata_path: Path to the file where Logstash stores metadata about the last execution.
- tags: Additional metadata attached to events generated by this input.
Output: Specifies the destination for processed data. In this case, it’s using the Elasticsearch output plugin to send data to Elasticsearch.
- if: Conditional statement to filter events based on their tags.
- elasticsearch: Specifies Elasticsearch as the destination.
- hosts: Elasticsearch cluster URLs.
- index: Index name where data will be stored.
- document_id: Document ID to use when storing data. Here, it’s using the id field from the incoming data.











Hello. excellent job. I did not anticipate this. This is a excellent story. Thanks!
Heard a lot about w88asia and decided to check it out. Pretty good selection of Asian games and sports betting too. Seems like a decent platform so far. Check it out: w88asia
Alright, 88clbgame, heard some buzz ’round town. Gave it a whirl, pretty decent selection and the bonuses weren’t bad. Nothing crazy, but solid for a chill night in. Gonna check back later to see if they update the games. Check it out yourself: 88clbgame
Hello, you used to write excellent, but the last few posts have been kinda boring?K I miss your super writings. Past few posts are just a bit out of track! come on!
Hey all, Coin777 has been on my radar lately. I really like the platform. Definitely worth checking out for some casual fun. coin777
You can definitely see your enthusiasm in the work you write. The world hopes for even more passionate writers like you who are not afraid to say how they believe. Always follow your heart.
Thank you so much for giving everyone an extremely splendid possiblity to read in detail from here. It is usually very awesome and jam-packed with a good time for me and my office friends to visit your web site really thrice per week to learn the newest tips you will have. And definitely, I am also certainly astounded with the impressive guidelines you give. Selected 3 points on this page are certainly the most efficient we have ever had.
Thanks for the update, how can I make is so that I receive an email sent to me whenever you write a fresh post?
My spouse and i have been absolutely ecstatic that John managed to round up his analysis via the precious recommendations he made from your web pages. It’s not at all simplistic to just choose to be giving freely guidelines which often the others have been trying to sell. And we keep in mind we now have you to appreciate because of that. All of the explanations you’ve made, the straightforward blog menu, the friendships your site aid to instill – it’s got mostly incredible, and it’s really helping our son and the family know that this issue is exciting, which is certainly rather important. Thanks for everything!
Fantastic blog! Do you have any tips for aspiring writers? I’m planning to start my own website soon but I’m a little lost on everything. Would you advise starting with a free platform like WordPress or go for a paid option? There are so many options out there that I’m totally confused .. Any tips? Bless you!
It is appropriate time to make some plans for the future and it is time to be happy. I have read this post and if I could I wish to suggest you few interesting things or tips. Maybe you can write next articles referring to this article. I wish to read even more things about it!
I think you have remarked some very interesting details , regards for the post.
Perfectly indited written content, thank you for entropy. “In the fight between you and the world, back the world.” by Frank Zappa.
I have not checked in here for some time as I thought it was getting boring, but the last few posts are great quality so I guess I will add you back to my everyday bloglist. You deserve it my friend 🙂
You made certain good points there. I did a search on the subject and found most persons will consent with your blog.
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
Terrific paintings! That is the kind of info that are supposed to be shared across the web. Disgrace on the seek engines for no longer positioning this publish upper! Come on over and visit my web site . Thanks =)
You should take part in a contest for one of the best blogs on the web. I will recommend this site!
This is the proper blog for anyone who desires to find out about this topic. You understand a lot its almost laborious to argue with you (not that I really would need…HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great!
I¦ve read several just right stuff here. Definitely price bookmarking for revisiting. I wonder how much effort you set to make one of these great informative site.
Very clean web site, appreciate it for this post.
I reckon something truly special in this web site.
It is really a nice and helpful piece of information. I am glad that you shared this useful info with us. Please keep us up to date like this. Thank you for sharing.
Normally I do not read article on blogs, but I wish to say that this write-up very forced me to try and do so! Your writing style has been surprised me. Thank you, quite great article.
Hi! I just wanted to ask if you ever have any trouble with hackers? My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no back up. Do you have any solutions to stop hackers?
I haven?¦t checked in here for a while as I thought it was getting boring, but the last several posts are great quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
You made some nice points there. I did a search on the subject and found most guys will consent with your site.
I love your blog.. very nice colors & theme. Did you create this website yourself? Plz reply back as I’m looking to create my own blog and would like to know wheere u got this from. thanks
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
Hi there just wanted to give you a quick heads up. The words in your post seem to be running off the screen in Safari. I’m not sure if this is a format issue or something to do with internet browser compatibility but I thought I’d post to let you know. The style and design look great though! Hope you get the issue solved soon. Cheers
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out a lot. I’m hoping to offer one thing back and aid others like you helped me.
I’ve been browsing online more than three hours today, yet I never found any fascinating article like yours. It is pretty value sufficient for me. In my view, if all webmasters and bloggers made good content material as you did, the internet shall be much more useful than ever before. “Wherever they burn books, they will also, in the end, burn people.” by Heinrich Heine.
Hey, you used to write great, but the last few posts have been kinda boring… I miss your tremendous writings. Past few posts are just a little out of track! come on!
Hello! This post could not be written any better! Reading through this post reminds me of my good old room mate! He always kept chatting about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
I am not rattling good with English but I come up this real easy to translate.
There is noticeably a bundle to know about this. I assume you made certain nice points in features also.
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very web savvy so I’m not 100 sure. Any tips or advice would be greatly appreciated. Thanks
Rattling wonderful visual appeal on this internet site, I’d rate it 10 10.
Hello.This article was really remarkable, particularly because I was searching for thoughts on this subject last Monday.
This actually answered my drawback, thank you!
I have been browsing online greater than three hours these days, yet I by no means discovered any interesting article like yours. It is pretty worth enough for me. In my opinion, if all webmasters and bloggers made just right content as you probably did, the internet will probably be much more helpful than ever before.
Heya i am for the primary time here. I came across this board and I find It really useful & it helped me out a lot. I’m hoping to present one thing back and help others such as you helped me.
As I website owner I believe the content here is very superb, thanks for your efforts.
Way cool, some valid points! I appreciate you making this article available, the rest of the site is also high quality. Have a fun.
I’m very happy to read this. This is the type of manual that needs to be given and not the random misinformation that is at the other blogs. Appreciate your sharing this greatest doc.
Some truly interesting details you have written.Helped me a lot, just what I was searching for : D.
You made some decent points there. I looked on the internet for the subject matter and found most guys will consent with your blog.
I truly appreciate this post. I have been looking everywhere for this! Thank goodness I found it on Bing. You’ve made my day! Thank you again
Real clean web site, thankyou for this post.
You have noted very interesting details ! ps decent site.
With havin so much content and articles do you ever run into any problems of plagorism or copyright violation? My site has a lot of unique content I’ve either created myself or outsourced but it seems a lot of it is popping it up all over the web without my permission. Do you know any solutions to help stop content from being stolen? I’d definitely appreciate it.
Hey, you used to write excellent, but the last several posts have been kinda boringK I miss your great writings. Past several posts are just a little out of track! come on!
I have been surfing online more than three hours nowadays, but I never found any interesting article like yours. It is lovely price enough for me. Personally, if all website owners and bloggers made good content as you probably did, the web will probably be a lot more useful than ever before. “No nation was ever ruined by trade.” by Benjamin Franklin.
Wow! Thank you! I continuously wanted to write on my website something like that. Can I implement a portion of your post to my blog?
What i don’t understood is in reality how you’re not actually much more neatly-appreciated than you may be right now. You’re very intelligent. You recognize therefore considerably in relation to this matter, produced me individually imagine it from a lot of numerous angles. Its like women and men don’t seem to be involved except it’s one thing to do with Woman gaga! Your individual stuffs excellent. Always maintain it up!
I’m no longer positive where you’re getting your information, however great topic. I needs to spend a while finding out much more or understanding more. Thank you for excellent information I was looking for this info for my mission.
Great post and straight to the point. I don’t know if this is actually the best place to ask but do you people have any ideea where to hire some professional writers? Thanks in advance 🙂
My partner and I stumbled over here by a different web address and thought I may as well check things out. I like what I see so now i am following you. Look forward to looking into your web page repeatedly.
There are some attention-grabbing deadlines on this article but I don’t know if I see all of them center to heart. There’s some validity but I’ll take hold opinion till I look into it further. Good article , thanks and we want more! Added to FeedBurner as properly
Some truly interesting information, well written and broadly speaking user genial.
I have recently started a web site, the information you offer on this website has helped me tremendously. Thank you for all of your time & work.
I was recommended this website through my cousin. I’m now not sure whether or not this post is written by him as no one else recognize such particular approximately my trouble. You are amazing! Thank you!
I consider something really special in this web site.
We’re a group of volunteers and opening a new scheme in our community. Your site offered us with valuable info to work on. You have done an impressive job and our whole community will be thankful to you.
Interesting analysis! The psychology of choosing numbers is fascinating, mirroring how platforms like jl7777 apk offer diverse game choices. Secure registration & easy access are key for enjoyable play! 🤔
I would like to show appreciation to you just for rescuing me from this type of matter. As a result of researching throughout the search engines and finding solutions which are not beneficial, I assumed my life was over. Existing minus the solutions to the difficulties you have fixed through the guideline is a crucial case, as well as those that would have negatively damaged my entire career if I hadn’t come across your web page. That capability and kindness in controlling all the stuff was tremendous. I don’t know what I would’ve done if I had not come upon such a solution like this. I’m able to at this point look forward to my future. Thanks so much for the high quality and amazing guide. I won’t think twice to recommend your web blog to any individual who would need guide about this area.
Hello there, simply became aware of your weblog via Google, and found that it is truly informative. I’m going to watch out for brussels. I will be grateful if you happen to proceed this in future. Numerous other people will likely be benefited from your writing. Cheers!
Howdy! I simply wish to give an enormous thumbs up for the nice data you’ve got here on this post. I will be coming back to your weblog for extra soon.
I truly appreciate this post. I¦ve been looking everywhere for this! Thank goodness I found it on Bing. You’ve made my day! Thanks again
Awesome site you have here but I was curious if you knew of any community forums that cover the same topics talked about in this article? I’d really love to be a part of online community where I can get responses from other knowledgeable individuals that share the same interest. If you have any recommendations, please let me know. Appreciate it!
Alright, so I was trying wk7777 and lets just say you win some you loose some. Overall its good entertainment and keeps you on the edge of your seat. Take a look wk7777.
Heard about jili88phcomapp? Gave it a try, and it’s alright! The app runs smoothly, which is a huge plus. If you’re looking for convenience, this might be your spot. Learn more here: jili88phcomapp
id888casino, eh? Not bad! Decent selection, good user experience. Might be a good choice for your chill nights. Check it out for yourself: id888casino
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
whoah this blog is great i love reading your articles. Keep up the good work! You know, lots of people are hunting around for this information, you could aid them greatly.
What’s Going down i am new to this, I stumbled upon this I have discovered It absolutely helpful and it has helped me out loads. I’m hoping to give a contribution & assist other users like its aided me. Great job.
This is a topic close to my heart cheers, where are your contact details though?
I don’t ordinarily comment but I gotta state regards for the post on this one : D.
you have a great blog here! would you like to make some invite posts on my blog?
I’m often to running a blog and i really recognize your content. The article has really peaks my interest. I’m going to bookmark your website and keep checking for new information.
I like what you guys are up too. Such smart work and reporting! Keep up the excellent works guys I have incorporated you guys to my blogroll. I think it’ll improve the value of my site 🙂
Alright, 7e777game, you’ve got my attention. Let’s see if you can keep it. Exploring it now. Hoping for some epic gameplay! See what 7e777game is about 7e777game
Yo, getting hyped about y999apk. Downloading my games has never been easier. It’s quick, simple, just the way i like it. Download yours y999apk
Just stumbled upon x666game. Fingers crossed for some hidden gems in here! Can’t wait to start playing. Check them out x666game
I was reading through some of your content on this website and I conceive this internet site is very informative ! Keep on putting up.
Thanx for the effort, keep up the good work Great work, I am going to start a small Blog Engine course work using your site I hope you enjoy blogging with the popular BlogEngine.net.Thethoughts you express are really awesome. Hope you will right some more posts.
I gotta favorite this site it seems very useful very helpful
Woah! I’m really enjoying the template/theme of this site. It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between user friendliness and visual appearance. I must say you’ve done a very good job with this. Also, the blog loads extremely fast for me on Chrome. Excellent Blog!
I’m really enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit more often. Did you hire out a designer to create your theme? Great work!
Yay google is my world beater aided me to find this great website ! .
Hiya, I am really glad I’ve found this info. Today bloggers publish just about gossips and net and this is actually annoying. A good blog with interesting content, this is what I need. Thank you for keeping this website, I’ll be visiting it. Do you do newsletters? Cant find it.
Oh my goodness! an incredible article dude. Thanks However I am experiencing difficulty with ur rss . Don’t know why Unable to subscribe to it. Is there anyone getting similar rss downside? Anyone who knows kindly respond. Thnkx
Woah! I’m really digging the template/theme of this site. It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between superb usability and visual appeal. I must say you have done a very good job with this. Also, the blog loads super quick for me on Firefox. Outstanding Blog!
Some truly wondrous work on behalf of the owner of this web site, dead outstanding subject material.
There are actually a whole lot of details like that to take into consideration. That could be a nice point to convey up. I supply the ideas above as basic inspiration however clearly there are questions like the one you deliver up where the most important thing will likely be working in honest good faith. I don?t know if finest practices have emerged around issues like that, but I’m positive that your job is clearly recognized as a good game. Each boys and girls really feel the affect of just a second’s pleasure, for the remainder of their lives.
I have been checking out a few of your articles and it’s pretty nice stuff. I will definitely bookmark your site.
Please let me know if you’re looking for a author for your blog. You have some really good posts and I feel I would be a good asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to mine. Please blast me an e-mail if interested. Thanks!
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post…
Its fantastic as your other posts : D, thanks for posting.
I loved up to you will receive carried out proper here. The sketch is attractive, your authored subject matter stylish. however, you command get bought an nervousness over that you would like be turning in the following. sick undoubtedly come more until now once more as exactly the same just about a lot ceaselessly inside of case you protect this increase.
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out a lot. I hope to give something back and aid others like you aided me.
Sup people, quick shoutout to 92gamelogin. Getting logged into your games has never been easier. Check it out if you’re tired of forgetting passwords: 92gamelogin
Whats good, folks? Been messing around with mwingame and its not half bad. Gives you a few good hours of entertainment. Get it here: mwingame
Pakaviatorgame… flying high! This game is addictive, man. Waiting for that big multiplier! Worth a shot if you like quick games. pakaviatorgame.
I’ve been browsing on-line more than three hours nowadays, yet I by no means discovered any attention-grabbing article like yours. It¦s beautiful worth enough for me. Personally, if all site owners and bloggers made good content as you probably did, the internet will probably be much more helpful than ever before.
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.
You should take part in a contest for one of the best blogs on the web. I will recommend this site!
Yay google is my world beater assisted me to find this great website ! .
I love your writing style genuinely enjoying this internet site.
Some genuinely select posts on this internet site, saved to favorites.
I like what you guys are up too. Such clever work and reporting! Keep up the superb works guys I have incorporated you guys to my blogroll. I think it will improve the value of my website 🙂
It is truly a great and helpful piece of information. I am happy that you simply shared this helpful info with us. Please stay us up to date like this. Thanks for sharing.
You are my breathing in, I have few blogs and sometimes run out from brand :). “He who controls the past commands the future. He who commands the future conquers the past.” by George Orwell.
Nice blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple adjustements would really make my blog shine. Please let me know where you got your theme. Thanks
Your style is so unique compared to many other people. Thank you for publishing when you have the opportunity,Guess I will just make this bookmarked.2
Simply a smiling visitor here to share the love (:, btw great style. “Reading well is one of the great pleasures that solitude can afford you.” by Harold Bloom.
As I site possessor I believe the content matter here is rattling magnificent , appreciate it for your efforts. You should keep it up forever! Best of luck.
Hey very cool website!! Man .. Beautiful .. Amazing .. I’ll bookmark your site and take the feeds also…I am happy to find so many useful information here in the post, we need work out more strategies in this regard, thanks for sharing. . . . . .
I used to be more than happy to find this web-site.I needed to thanks in your time for this wonderful read!! I definitely having fun with every little bit of it and I’ve you bookmarked to check out new stuff you blog post.
What¦s Taking place i’m new to this, I stumbled upon this I’ve discovered It absolutely useful and it has helped me out loads. I hope to contribute & assist other customers like its helped me. Great job.
certainly like your web site however you need to check the spelling on several of your posts. Several of them are rife with spelling issues and I in finding it very bothersome to tell the truth nevertheless I?¦ll surely come again again.
I have been examinating out many of your stories and i can claim pretty nice stuff. I will surely bookmark your site.
Howdy, i read your blog from time to time and i own a similar one and i was just curious if you get a lot of spam comments? If so how do you reduce it, any plugin or anything you can advise? I get so much lately it’s driving me insane so any help is very much appreciated.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You definitely know what youre talking about, why waste your intelligence on just posting videos to your blog when you could be giving us something enlightening to read?
Absolutely written content material, Really enjoyed looking at.
Fantastic beat ! I wish to apprentice while you amend your website, how can i subscribe for a blog site? The account helped me a acceptable deal. I had been a little bit acquainted of this your broadcast provided bright clear idea
I’ve been surfing online more than 3 hours today, yet I never found any interesting article like yours. It’s pretty worth enough for me. In my view, if all web owners and bloggers made good content as you did, the internet will be much more useful than ever before.
Thanks for some other informative website. Where else may I get that kind of info written in such a perfect approach? I’ve a venture that I am simply now operating on, and I’ve been on the look out for such information.
I like this weblog very much, Its a very nice spot to read and get information. “The love of nature is consolation against failure.” by Berthe Morisot.
Hey There. I discovered your weblog the usage of msn. That is a really neatly written article. I’ll be sure to bookmark it and come back to learn more of your helpful info. Thank you for the post. I will definitely return.
Excellent blog here! Also your site loads up very fast! What host are you using? Can I get your affiliate link to your host? I wish my web site loaded up as fast as yours lol
Unquestionably believe that which you stated. Your favorite reason seemed to be at the internet the easiest thing to be aware of. I say to you, I certainly get irked while other people consider issues that they plainly do not realize about. You controlled to hit the nail upon the highest as well as outlined out the whole thing without having side effect , other people can take a signal. Will likely be again to get more. Thanks
Hmm is anyone else experiencing problems with the pictures on this blog loading? I’m trying to find out if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated.
Very efficiently written article. It will be supportive to anyone who usess it, as well as yours truly :). Keep doing what you are doing – looking forward to more posts.
Definitely, what a magnificent site and informative posts, I will bookmark your website.All the Best!
The next time I learn a blog, I hope that it doesnt disappoint me as much as this one. I mean, I know it was my choice to learn, however I truly thought youd have one thing fascinating to say. All I hear is a bunch of whining about one thing that you would repair in case you werent too busy on the lookout for attention.
Hi, Neat post. There’s an issue together with your web site in internet explorer, would check this?K IE still is the marketplace leader and a big component to people will miss your magnificent writing due to this problem.
Spot on with this write-up, I truly suppose this website needs much more consideration. I’ll probably be again to read much more, thanks for that info.
It’s best to participate in a contest for among the best blogs on the web. I will recommend this site!
you are really a good webmaster. The web site loading speed is incredible. It seems that you are doing any unique trick. Moreover, The contents are masterpiece. you have done a wonderful job on this topic!
I am really inspired along with your writing talents as well as with the format for your weblog. Is this a paid subject or did you customize it your self? Either way stay up the nice high quality writing, it’s rare to look a great weblog like this one these days..
I am extremely impressed with your writing skills and also with the layout on your blog. Is this a paid theme or did you customize it yourself? Anyway keep up the nice quality writing, it is rare to see a great blog like this one today..
It’s perfect time to make some plans for the longer term and it is time to be happy. I have learn this submit and if I may just I desire to suggest you few attention-grabbing things or advice. Maybe you could write subsequent articles relating to this article. I desire to read more issues approximately it!
You are my inhalation, I have few blogs and very sporadically run out from to brand.
USA Flights 24 — search engine helps you compare prices from hundreds of airlines and travel sites in seconds — so you can find cheap flights fast. Whether you’re planning a weekend getaway, a cross-country adventure, or an international vacation, we make it easy to fly for less.
It is in reality a nice and helpful piece of info. I?¦m happy that you simply shared this helpful information with us. Please stay us up to date like this. Thanks for sharing.
As soon as I noticed this internet site I went on reddit to share some of the love with them.
Some genuinely interesting points you have written.Helped me a lot, just what I was searching for : D.
I’m not sure exactly why but this website is loading very slow for me. Is anyone else having this problem or is it a issue on my end? I’ll check back later on and see if the problem still exists.
Hello there! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Awsome website! I am loving it!! Will come back again. I am taking your feeds also
I genuinely enjoy looking through on this website, it has got great posts. “Don’t put too fine a point to your wit for fear it should get blunted.” by Miguel de Cervantes.
I’ve been surfing online more than 3 hours today, yet I never found any interesting article like yours. It’s pretty worth enough for me. In my view, if all web owners and bloggers made good content as you did, the internet will be much more useful than ever before.
Merely wanna input on few general things, The website layout is perfect, the articles is real superb. “The reason there are two senators for each state is so that one can be the designated driver.” by Jay Leno.
I’ve recently started a web site, the info you offer on this site has helped me greatly. Thank you for all of your time & work.
I’d constantly want to be update on new blog posts on this site, bookmarked! .
Thanks for sharing superb informations. Your web site is very cool. I am impressed by the details that you have on this web site. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found simply the info I already searched everywhere and simply couldn’t come across. What an ideal website.
I as well as my friends ended up examining the good tricks found on the blog and so unexpectedly developed an awful suspicion I never expressed respect to the web site owner for those tips. My ladies had been consequently very interested to see all of them and have in effect seriously been loving these things. Appreciate your turning out to be quite accommodating and also for picking such perfect subject areas most people are really wanting to understand about. Our own sincere apologies for not saying thanks to you earlier.
I went over this site and I think you have a lot of fantastic information, saved to fav (:.
Hello there, just became alert to your blog through Google, and found that it is really informative. I am gonna watch out for brussels. I’ll appreciate if you continue this in future. Many people will be benefited from your writing. Cheers!
I like what you guys are up too. Such intelligent work and reporting! Keep up the superb works guys I’ve incorporated you guys to my blogroll. I think it will improve the value of my website :).
whoah this blog is excellent i really like reading your posts. Keep up the good work! You recognize, a lot of individuals are looking round for this information, you could help them greatly.
I have been absent for some time, but now I remember why I used to love this website. Thanks , I¦ll try and check back more frequently. How frequently you update your web site?
What i do not realize is actually how you are not actually much more well-liked than you might be right now. You are so intelligent. You realize therefore significantly relating to this subject, produced me personally consider it from numerous varied angles. Its like men and women aren’t fascinated unless it is one thing to accomplish with Lady gaga! Your own stuffs nice. Always maintain it up!
Thank you for sharing superb informations. Your web site is very cool. I am impressed by the details that you¦ve on this website. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for extra articles. You, my pal, ROCK! I found simply the info I already searched all over the place and just could not come across. What a great web site.
Good day! I could have sworn I’ve been to this site before but after checking through some of the post I realized it’s new to me. Anyways, I’m definitely glad I found it and I’ll be bookmarking and checking back frequently!
As a Newbie, I am constantly browsing online for articles that can benefit me. Thank you
Thank you for some other informative web site. Where else may just I get that type of information written in such an ideal manner? I’ve a challenge that I am just now operating on, and I’ve been on the glance out for such info.
Wow, marvelous weblog layout! How long have you ever been blogging for? you made blogging look easy. The total glance of your web site is great, as neatly as the content!
Great line up. We will be linking to this great article on our site. Keep up the good writing.
Greetings from Florida! I’m bored at work so I decided to check out your site on my iphone during lunch break. I enjoy the knowledge you provide here and can’t wait to take a look when I get home. I’m surprised at how fast your blog loaded on my phone .. I’m not even using WIFI, just 3G .. Anyways, very good blog!
Gotta say, ket qua 9.net is super reliable. All you need for finding the latest results. You won’t regret it. Go check it out: ket qua 9.net
Honestly, ket qua.net 9 is the only place I trust for my lottery results. Their site is always up-to-date, no fluff just straight to the facts! Take a look: ket qua.net 9
I love your blog.. very nice colors & theme. Did you create this website yourself? Plz reply back as I’m looking to create my own blog and would like to know wheere u got this from. thanks
Thank you for the auspicious writeup. It in reality was a leisure account it. Look complex to more delivered agreeable from you! However, how could we communicate?
I’m really impressed with your writing skills as well as with the layout on your weblog. Is this a paid theme or did you modify it yourself? Anyway keep up the nice quality writing, it is rare to see a nice blog like this one nowadays..
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
With havin so much written content do you ever run into any issues of plagorism or copyright infringement? My blog has a lot of completely unique content I’ve either created myself or outsourced but it seems a lot of it is popping it up all over the internet without my permission. Do you know any solutions to help prevent content from being stolen? I’d definitely appreciate it.
You are my aspiration, I own few web logs and rarely run out from to post .
Hey very nice blog!! Man .. Excellent .. Amazing .. I’ll bookmark your blog and take the feeds also…I’m happy to find numerous useful info here in the post, we need work out more strategies in this regard, thanks for sharing. . . . . .
F*ckin¦ awesome things here. I¦m very glad to see your article. Thanks a lot and i’m looking forward to touch you. Will you please drop me a e-mail?
I was suggested this website by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my problem. You’re wonderful! Thanks!
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
Keep functioning ,terrific job!
Hello there, simply become alert to your blog through Google, and located that it is truly informative. I’m going to be careful for brussels. I’ll appreciate in the event you continue this in future. A lot of other folks might be benefited out of your writing. Cheers!
You have remarked very interesting details ! ps nice internet site.
Hello there, just became alert to your blog through Google, and found that it’s truly informative. I’m gonna watch out for brussels. I’ll be grateful if you continue this in future. A lot of people will be benefited from your writing. Cheers!
I am always invstigating online for ideas that can benefit me. Thanks!
I have been absent for a while, but now I remember why I used to love this site. Thank you, I¦ll try and check back more frequently. How frequently you update your site?
Keep functioning ,fantastic job!
What¦s Taking place i’m new to this, I stumbled upon this I’ve discovered It absolutely useful and it has aided me out loads. I am hoping to give a contribution & aid different users like its aided me. Great job.
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
Woh I love your content, saved to my bookmarks! .
I like this blog very much so much superb information.
he blog was how do i say it… relevant, finally something that helped me. Thanks
Yo, gave Fun120 a shot. Pretty decent selection of games, and the site’s slick. Honestly, nothing majorly stands out, but it’s a solid option. If you’re bored, give it a whirl. fun120
Gave BJ888game a spin the other night. Found some cool slots I hadn’t seen before. The bonuses were decent too. Nothing to hate, really. Give it a shot if you are looking for different games. bj888game
Downloaded Verdecasinoapp last week. Mobile app plays smooth! Easy-to-use app and good slot games. I reckon you should check it out. verdecasinoapp
Hi would you mind stating which blog platform you’re working with? I’m going to start my own blog soon but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique. P.S My apologies for getting off-topic but I had to ask!
I was very happy to find this net-site.I needed to thanks on your time for this wonderful learn!! I positively enjoying every little little bit of it and I’ve you bookmarked to check out new stuff you weblog post.
Absolutely written subject matter, thankyou for entropy.
I have recently started a website, the info you offer on this website has helped me tremendously. Thanks for all of your time & work. “So full of artless jealousy is guilt, It spills itself in fearing to be spilt.” by William Shakespeare.
You should take part in a contest for one of the best blogs on the web. I will recommend this site!
bingoplus app is a search term used to describe the mobile application version of the Bingo Plus gaming platform.
Hi! I’ve been following your weblog for some time now and finally got the bravery to go ahead and give you a shout out from Houston Tx! Just wanted to say keep up the fantastic job!
Hi, Neat post. There is a problem with your site in internet explorer, may check this… IE nonetheless is the market chief and a good component of people will omit your magnificent writing because of this problem.
Utterly written content, Really enjoyed reading through.
Good post. I be taught something more difficult on completely different blogs everyday. It’ll at all times be stimulating to learn content from other writers and follow slightly one thing from their store. I’d desire to use some with the content on my blog whether or not you don’t mind. Natually I’ll give you a hyperlink in your web blog. Thanks for sharing.
You must participate in a contest for the most effective blogs on the web. I’ll suggest this website!
Utterly pent written content, Really enjoyed examining.
so much good info on here, : D.
I like the efforts you have put in this, appreciate it for all the great posts.
Just wish to say your article is as surprising. The clarity to your submit is simply excellent and i could think you’re a professional in this subject. Fine with your permission let me to grasp your feed to stay updated with drawing close post. Thanks 1,000,000 and please carry on the rewarding work.
Thanks for every other informative blog. The place else could I get that type of info written in such an ideal manner? I’ve a venture that I’m just now operating on, and I have been on the glance out for such info.
Real fantastic information can be found on blog. “You don’t get harmony when everybody sings the same note.” by Doug Floyd.
You actually make it seem so easy with your presentation however I in finding this topic to be actually something which I feel I would by no means understand. It seems too complex and very wide for me. I am having a look ahead on your next submit, I will attempt to get the hold of it!
Good day! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
I believe this website has some very good information for everyone :D. “The public will believe anything, so long as it is not founded on truth.” by Edith Sitwell.
Just what I was looking for, thanks for posting.
Would love to forever get updated great web site! .
I have been exploring for a bit for any high-quality articles or blog posts on this kind of area . Exploring in Yahoo I at last stumbled upon this site. Reading this information So i’m happy to convey that I’ve a very good uncanny feeling I discovered just what I needed. I most certainly will make sure to don’t forget this site and give it a glance regularly.
Good post. I learn something more difficult on different blogs everyday. It can all the time be stimulating to learn content material from different writers and observe just a little one thing from their store. I’d desire to use some with the content material on my blog whether or not you don’t mind. Natually I’ll give you a link on your web blog. Thanks for sharing.
Whats up very nice site!! Guy .. Beautiful .. Amazing .. I will bookmark your web site and take the feeds also?KI am happy to seek out numerous useful info right here within the put up, we need work out more strategies in this regard, thank you for sharing. . . . . .
I love the efforts you have put in this, thank you for all the great blog posts.
There may be noticeably a bundle to know about this. I assume you made sure nice factors in options also.
Keep up the good work, I read few blog posts on this internet site and I conceive that your blog is really interesting and has got circles of good information.
Your place is valueble for me. Thanks!…
Appreciate it for this wondrous post, I am glad I discovered this site on yahoo.
Heya i am for the first time here. I came across this board and I find It really useful & it helped me out a lot. I hope to give something back and aid others like you aided me.
Valuable info. Lucky me I found your web site by accident, and I’m shocked why this accident did not happened earlier! I bookmarked it.
I was recommended this web site by my cousin. I’m not sure whether this post is written by him as nobody else know such detailed about my difficulty. You’re incredible! Thanks!
I respect your piece of work, thankyou for all the interesting posts.
Valuable information. Lucky me I found your website by accident, and I’m shocked why this accident didn’t happened earlier! I bookmarked it.
I went over this website and I think you have a lot of good information, saved to favorites (:.
Nice blog here! Also your site loads up fast! What web host are you using? Can I get your affiliate link to your host? I wish my website loaded up as fast as yours lol
I truly treasure your work, Great post.
Very nice post. I just stumbled upon your blog and wished to say that I’ve really enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again soon!
I like this post, enjoyed this one appreciate it for putting up.
Valuable information. Lucky me I found your website by accident, and I’m shocked why this accident did not happened earlier! I bookmarked it.
Admiring the persistence you put into your blog and in depth information you present. It’s nice to come across a blog every once in a while that isn’t the same unwanted rehashed information. Excellent read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Valuable information. Fortunate me I discovered your website by accident, and I’m shocked why this coincidence did not took place earlier! I bookmarked it.
This web page is mostly a stroll-by means of for all of the information you wanted about this and didn’t know who to ask. Glimpse here, and also you’ll undoubtedly uncover it.
Hello my family member! I want to say that this article is amazing, great written and come with approximately all vital infos. I’d like to peer more posts like this .
you have a great blog here! would you like to make some invite posts on my blog?
Thanks for sharing superb informations. Your site is very cool. I am impressed by the details that you have on this web site. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found just the information I already searched all over the place and just couldn’t come across. What a perfect site.
Its superb as your other blog posts : D, regards for putting up. “The rewards for those who persevere far exceed the pain that must precede the victory.” by Ted W. Engstrom.
Hi my loved one! I want to say that this article is awesome, nice written and come with almost all vital infos. I would like to peer extra posts like this .
Thank you for any other wonderful post. The place else could anybody get that kind of info in such an ideal means of writing? I’ve a presentation subsequent week, and I’m on the search for such information.
Howdy very cool website!! Guy .. Excellent .. Superb .. I will bookmark your web site and take the feeds alsoKI am glad to find so many useful information here in the publish, we’d like work out extra strategies in this regard, thank you for sharing. . . . . .
I have been exploring for a little bit for any high quality articles or weblog posts in this sort of area . Exploring in Yahoo I eventually stumbled upon this site. Studying this info So i’m happy to exhibit that I’ve a very excellent uncanny feeling I found out just what I needed. I most certainly will make certain to don’t put out of your mind this site and give it a look on a relentless basis.
You made some respectable points there. I seemed on the internet for the problem and located most individuals will associate with together with your website.
I am typically to running a blog and i really appreciate your content. The article has really peaks my interest. I’m going to bookmark your website and maintain checking for brand spanking new information.
I needed to put you this little word in order to thank you so much as before on your splendid knowledge you’ve shown on this site. It has been really strangely open-handed of you to give easily all a few people would have sold for an electronic book in order to make some profit for their own end, most importantly considering that you could have done it if you considered necessary. These tactics as well worked to provide a easy way to fully grasp the rest have similar interest really like my own to know more when considering this condition. I am certain there are several more pleasant periods ahead for individuals that scan through your blog post.
I like this blog so much, saved to fav. “Respect for the fragility and importance of an individual life is still the mark of an educated man.” by Norman Cousins.
It’s laborious to search out educated individuals on this matter, however you sound like you realize what you’re talking about! Thanks
I genuinely prize your piece of work, Great post.
My brother recommended I might like this blog. He was entirely right. This post actually made my day. You cann’t imagine simply how much time I had spent for this information! Thanks!
I appreciate, lead to I discovered exactly what I used to be taking a look for. You have ended my four day lengthy hunt! God Bless you man. Have a great day. Bye
Great post. I was checking continuously this weblog and I’m inspired! Extremely helpful information specially the last phase 🙂 I maintain such info much. I used to be seeking this certain info for a very long time. Thanks and best of luck.
Interesting points about responsible gaming frameworks! Seeing platforms like 8jl casino casino prioritize player security-especially with verification steps-is a good sign for the Philippine market. It’s crucial for new platforms to build trust!
Have you ever thought about creating an ebook or guest authoring on other websites? I have a blog based upon on the same information you discuss and would really like to have you share some stories/information. I know my readers would enjoy your work. If you’re even remotely interested, feel free to shoot me an email.
Today, while I was at work, my cousin stole my apple ipad and tested to see if it can survive a twenty five foot drop, just so she can be a youtube sensation. My apple ipad is now destroyed and she has 83 views. I know this is completely off topic but I had to share it with someone!
I love it when people come together and share opinions, great blog, keep it up.
Wow! Thank you! I always wanted to write on my website something like that. Can I take a portion of your post to my blog?
Some really superb info , Sword lily I detected this.
I got what you intend, regards for putting up.Woh I am happy to find this website through google. “Since the Exodus, freedom has always spoken with a Hebrew accent.” by Heinrich Heine.
Loving the info on this site, you have done great job on the posts.
I absolutely love your blog and find a lot of your post’s to be exactly I’m looking for. Does one offer guest writers to write content in your case? I wouldn’t mind producing a post or elaborating on some of the subjects you write concerning here. Again, awesome web site!
Nice read, I just passed this onto a friend who was doing a little research on that. And he actually bought me lunch as I found it for him smile Therefore let me rephrase that: Thanks for lunch!
Thank you, I’ve recently been looking for info approximately this topic for ages and yours is the greatest I’ve found out till now. But, what concerning the bottom line? Are you positive in regards to the source?
Spot on with this write-up, I truly suppose this web site needs rather more consideration. I’ll in all probability be again to learn far more, thanks for that info.
I dugg some of you post as I thought they were extremely helpful very beneficial
Very interesting info !Perfect just what I was looking for!
Spot on with this write-up, I actually suppose this web site needs way more consideration. I’ll most likely be once more to read way more, thanks for that info.
Howdy would you mind letting me know which web host you’re working with? I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot faster then most. Can you recommend a good web hosting provider at a honest price? Thanks, I appreciate it!
I like the helpful information you provide in your articles. I’ll bookmark your blog and take a look at once more here regularly. I’m moderately certain I’ll be informed many new stuff proper right here! Best of luck for the next!
Hi, Neat post. There’s a problem with your site in internet explorer, would test this… IE still is the market leader and a huge portion of people will miss your excellent writing because of this problem.
I’ll immediately seize your rss feed as I can’t to find your e-mail subscription link or e-newsletter service. Do you’ve any? Please allow me recognise in order that I may just subscribe. Thanks.
I’ve read a few excellent stuff here. Certainly value bookmarking for revisiting. I wonder how a lot attempt you place to make one of these fantastic informative site.
Glad to be one of the visitants on this awesome website : D.
I was looking at some of your blog posts on this website and I believe this web site is really instructive! Continue posting.
Really insightful article! Thinking about user experience is key – smooth registration (like with bw29 slot) & easy deposits make all the difference. Secure platforms are a must for peace of mind too! 👍
Really informative and excellent anatomical structure of subject material, now that’s user pleasant (:.
I’m really loving the theme/design of your site. Do you ever run into any internet browser compatibility problems? A few of my blog readers have complained about my website not working correctly in Explorer but looks great in Opera. Do you have any suggestions to help fix this issue?
Very interesting topic, regards for posting. “Wrinkles should merely indicate where smiles have been.” by Mark Twain.
Hey There. I found your blog using msn. This is an extremely well written article. I’ll make sure to bookmark it and return to read more of your useful info. Thanks for the post. I will certainly comeback.
This is very fascinating, You’re a very skilled blogger. I have joined your feed and stay up for looking for more of your wonderful post. Also, I have shared your web site in my social networks!
Great write-up, I’m normal visitor of one’s site, maintain up the excellent operate, and It is going to be a regular visitor for a lengthy time.
В сети можно скачать базу для хрумера https://www.olx.ua/d/uk/obyavlenie/progon-hrumerom-dr-50-po-ahrefs-uvelichu-reyting-domena-IDXnHrG.html, но важно проверить ее качество перед использованием.
I am thankful that I discovered this web site, precisely the right information that I was searching for! .
There are some interesting deadlines in this article but I don’t know if I see all of them heart to heart. There may be some validity but I will take hold opinion till I look into it further. Good article , thanks and we want more! Added to FeedBurner as well
Have you ever considered writing an ebook or guest authoring on other sites? I have a blog based on the same topics you discuss and would really like to have you share some stories/information. I know my visitors would enjoy your work. If you are even remotely interested, feel free to shoot me an e-mail.
I’m really loving the theme/design of your web site. Do you ever run into any browser compatibility problems? A couple of my blog readers have complained about my site not operating correctly in Explorer but looks great in Chrome. Do you have any suggestions to help fix this problem?
What i don’t understood is actually how you’re now not really a lot more well-appreciated than you might be now. You are very intelligent. You realize thus significantly on the subject of this subject, produced me in my opinion believe it from so many various angles. Its like women and men are not interested unless it is something to accomplish with Girl gaga! Your own stuffs excellent. At all times take care of it up!
I got good info from your blog
I will immediately grab your rss feed as I can not find your e-mail subscription link or newsletter service. Do you have any? Please let me know so that I could subscribe. Thanks.
Wow! This could be one particular of the most helpful blogs We have ever arrive across on this subject. Basically Fantastic. I’m also a specialist in this topic therefore I can understand your effort.
Good info. Lucky me I reach on your website by accident, I bookmarked it.
Thanks for sharing superb informations. Your web site is so cool. I am impressed by the details that you’ve on this site. It reveals how nicely you perceive this subject. Bookmarked this web page, will come back for extra articles. You, my friend, ROCK! I found just the information I already searched all over the place and just could not come across. What a great web-site.
Definitely, what a great website and enlightening posts, I definitely will bookmark your website.Have an awsome day!
Wow! Thank you! I permanently needed to write on my website something like that. Can I take a part of your post to my website?
Its like you read my mind! You seem to know a lot about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a little bit, but instead of that, this is great blog. A fantastic read. I will definitely be back.
What’s up, everyone? Gave vn58i a spin. It’s got a pretty interesting setup. Maybe not for everyone, but could be right up your alley. Check it out: vn58i
Alright, just had a go at j88abcvip. I must say it is more complicated than other website, but not difficult. Check it out: j88abcvip
Hey, I played the numbers, and now I´m here to speak about 51gamelottery! Nothing mind-blowing, but worth a look. I’d say give it a shot to find your lucky number here: 51gamelottery
I like this post, enjoyed this one regards for posting. “I would sooner fail than not be among the greatest.” by John Keats.
I was suggested this blog by my cousin. I’m not sure whether this post is written by him as nobody else know such detailed about my trouble. You’re incredible! Thanks!
Thank you, I have recently been searching for info approximately this topic for a while and yours is the best I have found out so far. But, what in regards to the conclusion? Are you certain concerning the supply?
A formidable share, I simply given this onto a colleague who was doing a bit of evaluation on this. And he actually purchased me breakfast as a result of I discovered it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I really feel strongly about it and love studying more on this topic. If doable, as you grow to be experience, would you thoughts updating your weblog with extra details? It’s extremely useful for me. Big thumb up for this weblog post!
you could have a terrific weblog right here! would you like to make some invite posts on my blog?
Lovely blog! I am loving it!! Will come back again. I am taking your feeds also.
Generally I don’t learn article on blogs, but I wish to say that this write-up very compelled me to check out and do so! Your writing taste has been surprised me. Thanks, very nice article.
I have recently started a website, the info you provide on this web site has helped me greatly. Thanks for all of your time & work.
Only a smiling visitant here to share the love (:, btw great style. “He profits most who serves best.” by Arthur F. Sheldon.
Enjoyed examining this, very good stuff, appreciate it. “It is in justice that the ordering of society is centered.” by Aristotle.
I went over this site and I believe you have a lot of wonderful info , bookmarked (:.
Thanks for the blog post, can I set it up so I get an alert email when you write a fresh update?
I truly appreciate this post. I have been looking everywhere for this! Thank goodness I found it on Bing. You have made my day! Thank you again
I just like the valuable info you provide on your articles. I will bookmark your weblog and take a look at once more here regularly. I am fairly sure I will be told lots of new stuff right right here! Best of luck for the following!
I like this web site because so much utile material on here :D.
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
Good day very nice blog!! Guy .. Beautiful .. Superb .. I’ll bookmark your site and take the feeds additionally…I’m happy to find so many useful info here within the submit, we’d like work out extra strategies on this regard, thank you for sharing.
Thanks – Enjoyed this update, is there any way I can receive an update sent in an email every time you make a new update?
Excellent weblog right here! Also your site quite a bit up fast! What web host are you the use of? Can I am getting your affiliate link for your host? I desire my website loaded up as quickly as yours lol
I would like to thnkx for the efforts you’ve put in writing this site. I’m hoping the same high-grade site post from you in the upcoming also. In fact your creative writing abilities has encouraged me to get my own blog now. Actually the blogging is spreading its wings quickly. Your write up is a good example of it.
It’s hard to search out educated folks on this matter, but you sound like you understand what you’re speaking about! Thanks
I genuinely treasure your work, Great post.
I truly appreciate this post. I’ve been looking everywhere for this! Thank goodness I found it on Bing. You have made my day! Thx again
Hello! This post could not be written any better! Reading this post reminds me of my previous room mate! He always kept talking about this. I will forward this page to him. Pretty sure he will have a good read. Many thanks for sharing!
Fascinating blog! Is your theme custom made or did you download it from somewhere? A theme like yours with a few simple tweeks would really make my blog stand out. Please let me know where you got your theme. Thank you
Your place is valueble for me. Thanks!…
Hi there, I found your website via Google while looking for a related topic, your web site came up, it looks good. I’ve bookmarked it in my google bookmarks.
Penjelasannya cukup jelas dan mudah dipahami bahkan untuk pembaca baru. Tidak heran kalau banyak juga yang akhirnya tertarik mencoba berbagai platform hiburan digital seperti theboatexchange
.
The very crux of your writing while appearing reasonable initially, did not really work properly with me after some time. Somewhere throughout the paragraphs you managed to make me a believer unfortunately only for a very short while. I however have got a problem with your leaps in assumptions and you might do well to help fill in all those breaks. When you can accomplish that, I will surely end up being impressed.
VN88 nhà cái Việt, giao diện thân thiện, dễ sử dụng. Chơi cá cược, casino online đều ổn áp. Vào vn88cuoc trải nghiệm ngay nhé!
Just checked out f8bet05, and hey, it’s not bad! Seems like a decent place to try my luck. I’ll def give it a shot. Check it out here: f8bet05
Alright, time to spin some reels at cashhoardslot.online! I’m feeling lucky. Wish me luck, guys! I hope to win big. You can find it here: cashhoardslot
Very good written post. It will be useful to everyone who employess it, as well as me. Keep doing what you are doing – looking forward to more posts.
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
It’s a shame you don’t have a donate button! I’d certainly donate to this excellent blog! I guess for now i’ll settle for bookmarking and adding your RSS feed to my Google account. I look forward to brand new updates and will talk about this website with my Facebook group. Talk soon!
Hey! This is my 1st comment here so I just wanted to give a quick shout out and say I genuinely enjoy reading through your articles. Can you suggest any other blogs/websites/forums that deal with the same topics? Thanks a ton!
Outstanding post, you have pointed out some fantastic details , I likewise think this s a very great website.
This web site is really a walk-through for all of the info you wanted about this and didn’t know who to ask. Glimpse here, and you’ll definitely discover it.
I like this post, enjoyed this one thanks for putting up.
I’ve recently started a blog, the info you provide on this website has helped me tremendously. Thank you for all of your time & work.
Hiya, I’m really glad I’ve found this info. Today bloggers publish just about gossips and net and this is really irritating. A good web site with interesting content, that is what I need. Thanks for keeping this site, I’ll be visiting it. Do you do newsletters? Cant find it.
I do agree with all of the ideas you have presented in your post. They are really convincing and will definitely work. Still, the posts are too short for novices. Could you please extend them a little from next time? Thanks for the post.
You have noted very interesting points! ps nice website . “What a grand thing, to be loved What a grander thing still, to love” by Victor Hugo.
I like this website very much, Its a really nice office to read and obtain information.
Saved as a favorite, I really like your blog!
I love your blog.. very nice colors & theme. Did you design this website yourself or did you hire someone to do it for you? Plz reply as I’m looking to create my own blog and would like to know where u got this from. kudos
Hi, I think your site might be having browser compatibility issues. When I look at your website in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, fantastic blog!
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
Just about all of the things you claim happens to be astonishingly accurate and it makes me ponder the reason why I had not looked at this in this light before. This particular article truly did switch the light on for me as far as this particular subject matter goes. Nevertheless there is one factor I am not necessarily too cozy with so while I attempt to reconcile that with the main theme of the position, let me observe what the rest of your readers have to point out.Well done.
so much good information on here, :D.
Hey, you used to write great, but the last few posts have been kinda boringK I miss your super writings. Past few posts are just a little bit out of track! come on!
I’m impressed, I must say. Actually not often do I encounter a weblog that’s each educative and entertaining, and let me inform you, you’ve hit the nail on the head. Your thought is excellent; the difficulty is one thing that not sufficient persons are talking intelligently about. I’m very completely happy that I stumbled throughout this in my search for something referring to this.
I like this blog very much so much great info .
I have been reading out many of your articles and i can state pretty clever stuff. I will make sure to bookmark your site.
It’s really a nice and helpful piece of information. I’m satisfied that you simply shared this helpful information with us. Please stay us informed like this. Thank you for sharing.
Some times its a pain in the ass to read what people wrote but this website is real user genial! .
Superb website you have here but I was wanting to know if you knew of any discussion boards that cover the same topics talked about in this article? I’d really like to be a part of online community where I can get advice from other experienced people that share the same interest. If you have any recommendations, please let me know. Appreciate it!
Olxtoto adalah agen terpercaya untuk situs toto dan bandar togel yang melayani pemain di Indonesia dengan komitmen tinggi terhadap kepuasan pelanggan.
Loving the info on this website , you have done great job on the blog posts.
Excellent post. I was checking continuously this blog and I’m impressed! Extremely useful information particularly the last part 🙂 I care for such information a lot. I was looking for this particular information for a long time. Thank you and good luck.
Wow, fantastic weblog layout! How lengthy have you ever been blogging for? you made running a blog glance easy. The total glance of your website is great, let alone the content!
I and also my pals have already been checking out the good tips found on your website then at once came up with a terrible feeling I had not thanked you for those secrets. Most of the young men happened to be for that reason stimulated to see them and have now unquestionably been taking pleasure in those things. Many thanks for getting really considerate and for obtaining this sort of decent resources most people are really desirous to know about. Our own sincere regret for not expressing gratitude to you sooner.
I believe this internet site has got very fantastic pent content articles.
I like this web site so much, bookmarked.
I’m not sure where you are getting your information, but good topic. I needs to spend some time learning more or understanding more. Thanks for wonderful information I was looking for this information for my mission.
Thanks for all of your labor on this website. My niece delights in getting into investigation and it is simple to grasp why. All of us notice all relating to the compelling medium you create very helpful guidance on this website and in addition welcome contribution from other individuals on this theme then our favorite simple princess is now discovering a lot of things. Have fun with the remaining portion of the new year. You are doing a stunning job.
I have been exploring for a little for any high-quality articles or blog posts on this sort of house . Exploring in Yahoo I finally stumbled upon this site. Studying this info So i am satisfied to convey that I have a very just right uncanny feeling I found out just what I needed. I so much indubitably will make certain to do not put out of your mind this web site and provides it a glance regularly.
hello!,I really like your writing very a lot! proportion we keep up a correspondence extra approximately your post on AOL? I need a specialist in this area to solve my problem. Maybe that is you! Having a look ahead to look you.
Glad to be one of many visitants on this awing internet site : D.
Some genuinely great info , Gladiolus I observed this. “The true republic men, their rights and nothing more women, their rights and nothing less.” by Franklin P. Adams.
I am lucky that I discovered this site, precisely the right information that I was searching for! .
The very core of your writing whilst appearing reasonable originally, did not really sit very well with me after some time. Somewhere within the sentences you managed to make me a believer but just for a very short while. I however have a problem with your jumps in assumptions and one might do well to help fill in all those breaks. If you can accomplish that, I would surely end up being fascinated.
I enjoy assembling utile info, this post has got me even more info! .
Very interesting subject , appreciate it for putting up.
With havin so much content do you ever run into any problems of plagorism or copyright violation? My blog has a lot of unique content I’ve either authored myself or outsourced but it appears a lot of it is popping it up all over the internet without my agreement. Do you know any techniques to help protect against content from being stolen? I’d genuinely appreciate it.
Thanks for your personal marvelous posting! I truly enjoyed reading it, you can be a great author.I will remember to bookmark your blog and may come back someday. I want to encourage you to definitely continue your great writing, have a nice morning!
whoah this blog is magnificent i love reading your posts. Keep up the great work! You know, many people are looking around for this information, you can aid them greatly.
As a Newbie, I am always browsing online for articles that can be of assistance to me. Thank you
This is a very good tips especially to those new to blogosphere, brief and accurate information… Thanks for sharing this one. A must read article.
Very well written post. It will be useful to anyone who employess it, including yours truly :). Keep up the good work – for sure i will check out more posts.
You must take part in a contest for among the finest blogs on the web. I’ll suggest this web site!
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across. It extremely helps make reading your blog significantly easier.
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
I like what you guys are up also. Such intelligent work and reporting! Carry on the excellent works guys I have incorporated you guys to my blogroll. I think it’ll improve the value of my website 🙂
You can certainly see your enthusiasm in the work you write. The arena hopes for more passionate writers like you who are not afraid to mention how they believe. At all times follow your heart. “The point of quotations is that one can use another’s words to be insulting.” by Amanda Cross.
I do accept as true with all the concepts you’ve offered on your post. They’re very convincing and can definitely work. Nonetheless, the posts are too brief for novices. Could you please prolong them a bit from next time? Thank you for the post.
I appreciate, cause I found exactly what I was looking for. You have ended my 4 day long hunt! God Bless you man. Have a nice day. Bye
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
Thanks for sharing excellent informations. Your web-site is so cool. I am impressed by the details that you’ve on this website. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for more articles. You, my pal, ROCK! I found simply the information I already searched everywhere and just couldn’t come across. What a perfect website.
Wow! This can be one particular of the most helpful blogs We have ever arrive across on this subject. Basically Fantastic. I am also a specialist in this topic therefore I can understand your effort.
I see something really special in this web site.
I’ve been surfing online more than three hours nowadays, but I never found any attention-grabbing article like yours. It is lovely price enough for me. Personally, if all web owners and bloggers made excellent content as you probably did, the net can be much more useful than ever before.
Keep functioning ,fantastic job!
Thank you for sharing excellent informations. Your web site is so cool. I am impressed by the details that you have on this web site. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for extra articles. You, my friend, ROCK! I found just the information I already searched all over the place and simply could not come across. What a great site.
Saya selamanya memikirkan hal ini, terimakasih telah memposting.
Great wordpress blog here.. It’s hard to find quality writing like yours these days. I really appreciate people like you! take care
Hello there! Would you mind if I share your blog with my twitter group? There’s a lot of folks that I think would really enjoy your content. Please let me know. Cheers
That is the correct blog for anyone who needs to find out about this topic. You notice so much its almost laborious to argue with you (not that I truly would need…HaHa). You undoubtedly put a brand new spin on a topic thats been written about for years. Nice stuff, simply nice!
I couldn’t resist commenting
I conceive you have noted some very interesting details, thankyou for the post.
I do agree with all of the ideas you have presented in your post. They’re really convincing and will definitely work. Still, the posts are very short for starters. Could you please extend them a little from next time? Thanks for the post.
I was examining some of your articles on this site and I conceive this web site is really informative! Continue posting.
I was just seeking this info for a while. After 6 hours of continuous Googleing, at last I got it in your site. I wonder what’s the lack of Google strategy that do not rank this kind of informative websites in top of the list. Normally the top websites are full of garbage.
Can I just say what a reduction to find somebody who really is aware of what theyre speaking about on the internet. You positively know tips on how to carry an issue to light and make it important. More people have to read this and perceive this aspect of the story. I cant imagine youre no more in style since you undoubtedly have the gift.
I’ll right away grasp your rss as I can not in finding your e-mail subscription link or e-newsletter service. Do you have any? Please let me recognize in order that I may subscribe. Thanks.
Some truly nice and useful info on this internet site, also I conceive the style and design holds fantastic features.
Some genuinely rattling work on behalf of the owner of this web site, absolutely outstanding content.
Merely wanna state that this is very beneficial, Thanks for taking your time to write this.
Simply a smiling visitant here to share the love (:, btw great layout.
Hello, Neat post. There’s an issue with your website in web explorer, might check thisK IE nonetheless is the market leader and a huge portion of people will miss your fantastic writing due to this problem.
Only a smiling visitor here to share the love (:, btw great style. “Individuals may form communities, but it is institutions alone that can create a nation.” by Benjamin Disraeli.
I’d perpetually want to be update on new content on this internet site, saved to favorites! .
you have a great blog here! would you like to make some invite posts on my blog?
very nice submit, i actually love this website, carry on it
I likewise believe thus, perfectly composed post! .
great post, very informative. I ponder why the opposite specialists of this sector don’t understand this. You should proceed your writing. I’m sure, you have a great readers’ base already!
Great blog here! Also your web site loads up very fast! What host are you using? Can I get your affiliate link to your host? I wish my web site loaded up as quickly as yours lol
Good day very cool website!! Guy .. Beautiful .. Superb .. I will bookmark your website and take the feeds additionally…I’m glad to seek out so many helpful information here within the put up, we want work out more techniques in this regard, thanks for sharing.
Thankyou for all your efforts that you have put in this. very interesting information.
You got a very excellent website, Gladiola I noticed it through yahoo.
Greetings from Ohio! I’m bored to death at work so I decided to check out your blog on my iphone during lunch break. I enjoy the knowledge you present here and can’t wait to take a look when I get home. I’m amazed at how quick your blog loaded on my cell phone .. I’m not even using WIFI, just 3G .. Anyhow, very good blog!
I have been exploring for a little bit for any high-quality articles or blog posts in this sort of space . Exploring in Yahoo I ultimately stumbled upon this website. Studying this info So i am happy to exhibit that I have a very excellent uncanny feeling I discovered just what I needed. I so much no doubt will make sure to don’t disregard this site and give it a glance regularly.
I have recently started a blog, the information you provide on this web site has helped me greatly. Thanks for all of your time & work.
Youre so cool! I dont suppose Ive read anything like this before. So nice to seek out any individual with some unique ideas on this subject. realy thank you for starting this up. this website is something that’s wanted on the net, somebody with just a little originality. useful job for bringing one thing new to the web!
Perfect piece of work you have done, this web site is really cool with fantastic info .
Thankyou for this post, I am a big big fan of this internet site would like to go along updated.
Hi, Neat post. There’s a problem with your web site in internet explorer, would test this… IE still is the market leader and a large portion of people will miss your magnificent writing due to this problem.
Pretty nice post. I just stumbled upon your blog and wanted to say that I’ve truly enjoyed surfing around your blog posts. After all I’ll be subscribing to your feed and I hope you write again very soon!
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four e-mails with the same comment. Is there any way you can remove people from that service? Thanks a lot!
I simply could not depart your site prior to suggesting that I actually loved the standard information a person provide to your visitors? Is going to be again continuously in order to inspect new posts.
I’ll right away grasp your rss feed as I can’t to find your e-mail subscription hyperlink or newsletter service. Do you have any? Please permit me recognise in order that I may just subscribe. Thanks.
Hi, i think that i saw you visited my weblog thus i got here to “return the choose”.I’m trying to find issues to improve my web site!I guess its good enough to make use of some of your concepts!!
Hey! Do you know if they make any plugins to assist with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains. If you know of any please share. Cheers!
I’m impressed, I have to say. Actually rarely do I encounter a weblog that’s each educative and entertaining, and let me let you know, you have got hit the nail on the head. Your idea is excellent; the problem is one thing that not sufficient persons are speaking intelligently about. I am very glad that I stumbled across this in my search for something regarding this.
wonderful points altogether, you simply gained a new reader. What would you suggest in regards to your post that you made a few days ago? Any positive?
Would love to incessantly get updated outstanding web site! .
I have been exploring for a little bit for any high-quality articles or blog posts on this kind of area . Exploring in Yahoo I at last stumbled upon this site. Reading this information So i’m happy to convey that I have an incredibly good uncanny feeling I discovered just what I needed. I most certainly will make sure to don’t forget this website and give it a glance on a constant basis.
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
You really make it seem really easy together with your presentation however I to find this matter to be really one thing that I think I’d never understand. It sort of feels too complicated and very extensive for me. I am having a look forward on your subsequent post, I’ll attempt to get the hang of it!
Regards for this howling post, I am glad I detected this site on yahoo.
Thank you for another great post. Where else could anybody get that kind of info in such an ideal way of writing? I’ve a presentation next week, and I am on the look for such information.
WONDERFUL Post.thanks for share..more wait .. …
Admiring the dedication you put into your website and in depth information you offer. It’s great to come across a blog every once in a while that isn’t the same old rehashed information. Wonderful read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
I’ll right away grab your rss as I can’t to find your e-mail subscription link or e-newsletter service. Do you have any? Please allow me understand in order that I may just subscribe. Thanks.
You have remarked very interesting points! ps decent internet site. “The empires of the future are the empires of the mind.” by Sir Winston Leonard Spenser Churchill.
Thank you for another informative website. Where else may just I am getting that kind of info written in such a perfect way? I have a mission that I’m just now running on, and I’ve been at the glance out for such information.
Hello! Would you mind if I share your blog with my facebook group? There’s a lot of folks that I think would really appreciate your content. Please let me know. Cheers
Great weblog here! Also your website lots up very fast! What host are you the usage of? Can I am getting your associate link for your host? I want my website loaded up as fast as yours lol
It’s actually a cool and helpful piece of info. I’m happy that you just shared this helpful info with us. Please stay us up to date like this. Thanks for sharing.
I like this web blog very much, Its a rattling nice place to read and find info . “Reason is not measured by size or height, but by principle.” by Epictetus.
Magnificent items from you, man. I have understand your stuff previous to and you are just too magnificent. I really like what you’ve got here, certainly like what you’re saying and the way through which you say it. You are making it entertaining and you continue to care for to stay it sensible. I can not wait to read far more from you. This is really a great web site.
Whats Happening i’m new to this, I stumbled upon this I have found It positively useful and it has helped me out loads. I hope to give a contribution & aid different users like its aided me. Good job.
Greetings! I know this is kinda off topic but I was wondering if you knew where I could locate a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having problems finding one? Thanks a lot!
Very nice post and straight to the point. I am not sure if this is truly the best place to ask but do you guys have any thoughts on where to hire some professional writers? Thanks 🙂
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
Good, I should definitely pronounce, impressed with your website. I had no trouble navigating through all the tabs and related info ended up being truly simple to do to access. I recently found what I hoped for before you know it in the least. Reasonably unusual. Is likely to appreciate it for those who add forums or something, site theme . a tones way for your customer to communicate. Nice task.
I got what you mean , thankyou for posting.Woh I am happy to find this website through google.
I am pleased that I found this site, exactly the right information that I was looking for! .
Hello! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
I am not really superb with English but I find this real easygoing to interpret.
hi!,I like your writing very much! share we communicate more about your article on AOL? I require a specialist on this area to solve my problem. May be that’s you! Looking forward to see you.
Heya! I’m at work surfing around your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the superb work!
It’s laborious to find knowledgeable individuals on this subject, but you sound like you understand what you’re speaking about! Thanks
Does your website have a contact page? I’m having problems locating it but, I’d like to shoot you an email. I’ve got some ideas for your blog you might be interested in hearing. Either way, great site and I look forward to seeing it improve over time.
I gotta bookmark this site it seems very helpful extremely helpful
I as well as my guys were looking through the good guides on the website and so immediately got an awful feeling I had not expressed respect to the site owner for those secrets. All the boys had been consequently passionate to study them and have honestly been using them. We appreciate you simply being quite helpful as well as for deciding on this form of very good subject matter millions of individuals are really needing to be informed on. Our sincere regret for not saying thanks to you earlier.
I used to be very pleased to find this internet-site.I wanted to thanks for your time for this wonderful read!! I positively enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
hello!,I like your writing so a lot! percentage we communicate extra approximately your post on AOL? I require a specialist in this house to resolve my problem. May be that’s you! Taking a look forward to look you.
I have not checked in here for a while because I thought it was getting boring, but the last several posts are great quality so I guess I’ll add you back to my daily bloglist. You deserve it my friend 🙂
Very interesting information!Perfect just what I was looking for! “The only gift is a portion of thyself.” by Ralph Waldo Emerson.
I do love the way you have framed this particular situation plus it does indeed present me some fodder for consideration. On the other hand, from what precisely I have witnessed, I really hope as the opinions pile on that folks remain on point and in no way get started upon a soap box associated with some other news of the day. Anyway, thank you for this superb piece and while I do not necessarily go along with the idea in totality, I value the point of view.
Rattling superb visual appeal on this internet site, I’d rate it 10 10.
I have read several good stuff here. Certainly worth bookmarking for revisiting. I surprise how much effort you put to create such a magnificent informative web site.
I have been exploring for a little bit for any high quality articles or blog posts on this sort of area . Exploring in Yahoo I eventually stumbled upon this web site. Reading this info So i am glad to show that I have an incredibly excellent uncanny feeling I found out just what I needed. I such a lot undoubtedly will make certain to do not disregard this web site and provides it a glance regularly.
Thank you a lot for sharing this with all of us you actually understand what you’re speaking about! Bookmarked. Kindly additionally discuss with my web site =). We could have a hyperlink alternate agreement among us!
Excellent web site. Plenty of helpful information here. I am sending it to several friends ans additionally sharing in delicious. And naturally, thanks on your effort!
Thanks , I’ve just been searching for info about this topic for a while and yours is the best I’ve found out till now. However, what concerning the conclusion? Are you sure in regards to the source?
I appreciate, cause I found exactly what I was looking for. You have ended my four day long hunt! God Bless you man. Have a great day. Bye
Hi there! Someone in my Facebook group shared this site with us so I came to look it over. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers! Wonderful blog and terrific design.
Thanks for helping out, superb info. “Whoever obeys the gods, to him they particularly listen.” by Homer.
I like this site because so much useful stuff on here :D.
I see something truly special in this website.
Hmm is anyone else encountering problems with the images on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any responses would be greatly appreciated.
Some really nice and utilitarian info on this web site, besides I think the pattern holds great features.
I like what you guys are up too. Such smart work and reporting! Carry on the superb works guys I have incorporated you guys to my blogroll. I think it’ll improve the value of my web site 🙂
Your place is valueble for me. Thanks!…
Rattling fantastic info can be found on website.
You made some good points there. I looked on the internet for the subject and found most persons will go along with with your blog.
I used to be recommended this website by my cousin. I am now not positive whether or not this publish is written by way of him as no one else know such unique about my difficulty. You’re wonderful! Thank you!
Fantastic website. Lots of useful information here. I’m sending it to several friends ans also sharing in delicious. And naturally, thanks for your effort!
I reckon something really special in this web site.
I’ve been exploring for a bit for any high quality articles or blog posts in this sort of area . Exploring in Yahoo I at last stumbled upon this website. Studying this information So i’m satisfied to convey that I’ve an incredibly just right uncanny feeling I found out exactly what I needed. I such a lot certainly will make certain to don’t put out of your mind this site and give it a glance regularly.
Very interesting topic, thankyou for posting.
You actually make it seem so easy with your presentation but I find this topic to be really something which I think I would never understand. It seems too complicated and very broad for me. I am looking forward for your next post, I will try to get the hang of it!
A formidable share, I just given this onto a colleague who was doing a bit evaluation on this. And he in truth purchased me breakfast because I discovered it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I really feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you thoughts updating your weblog with extra particulars? It is extremely useful for me. Large thumb up for this weblog put up!
I truly prize your work, Great post.
Its like you learn my thoughts! You seem to know a lot approximately this, like you wrote the book in it or something. I feel that you just can do with a few p.c. to pressure the message home a little bit, but other than that, this is fantastic blog. A fantastic read. I’ll certainly be back.
You are my inspiration , I possess few web logs and occasionally run out from to brand.
I have read several excellent stuff here. Certainly worth bookmarking for revisiting. I surprise how so much attempt you set to make such a fantastic informative website.
I will right away grab your rss feed as I can’t find your e-mail subscription link or newsletter service. Do you have any? Kindly let me know so that I could subscribe. Thanks.
I truly treasure your piece of work, Great post.
Whats up this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding skills so I wanted to get advice from someone with experience. Any help would be enormously appreciated!
I believe this internet site has some really superb information for everyone :D.
I beloved as much as you will receive performed proper here. The caricature is tasteful, your authored subject matter stylish. nonetheless, you command get bought an shakiness over that you would like be turning in the following. sick unquestionably come more before once more as exactly the same nearly very ceaselessly inside of case you protect this increase.
Can I simply say what a reduction to seek out somebody who truly knows what theyre speaking about on the internet. You positively know methods to deliver an issue to gentle and make it important. More individuals have to read this and understand this facet of the story. I cant consider youre no more in style since you definitely have the gift.
Wow! This can be one particular of the most beneficial blogs We have ever arrive across on this subject. Actually Great. I am also a specialist in this topic so I can understand your hard work.
Hello there, You have done an excellent job. I will certainly digg it and personally recommend to my friends. I am confident they’ll be benefited from this web site.
Only wanna state that this is very helpful, Thanks for taking your time to write this.
Hi there, simply became alert to your weblog thru Google, and located that it is really informative. I’m gonna watch out for brussels. I’ll appreciate should you proceed this in future. Many folks shall be benefited out of your writing. Cheers!
Very interesting topic, regards for putting up.
Thank you for any other fantastic article. Where else may just anyone get that type of info in such a perfect means of writing? I’ve a presentation subsequent week, and I am on the search for such information.
I really like your writing style, good information, appreciate it for putting up :D. “Inquiry is fatal to certainty.” by Will Durant.
Currently it looks like WordPress is the best blogging platform out there right now. (from what I’ve read) Is that what you are using on your blog?
I like what you guys are up too. Such intelligent work and reporting! Carry on the excellent works guys I’ve incorporated you guys to my blogroll. I think it’ll improve the value of my web site 🙂
9080, just browsed through it. Deffo got potential. Might throw down some cash and see what happens. Explore it all at 9080.
AAAbet1, had a gander. Not bad, pretty straightforward. Thinking about placing a bet or two. Check ’em out at aaabet1.
bg678gamedownloadapk! Downloaded the APK, game looks killer. Time to level up my entertainment. Get your game on at bg678gamedownloadapk.
I am really loving the theme/design of your web site. Do you ever run into any web browser compatibility issues? A couple of my blog readers have complained about my blog not working correctly in Explorer but looks great in Firefox. Do you have any ideas to help fix this issue?
I wish to express some thanks to this writer for bailing me out of this particular scenario. Right after looking throughout the world wide web and seeing advice which are not helpful, I was thinking my life was done. Living minus the approaches to the problems you have sorted out by means of the website is a crucial case, and the kind that could have negatively damaged my entire career if I had not encountered your blog post. Your main understanding and kindness in taking care of almost everything was invaluable. I am not sure what I would have done if I hadn’t come upon such a step like this. It’s possible to at this time look forward to my future. Thanks very much for this high quality and results-oriented guide. I won’t be reluctant to refer your web page to anyone who would need guidelines about this problem.
I’m impressed, I have to say. Really not often do I encounter a blog that’s each educative and entertaining, and let me let you know, you’ve got hit the nail on the head. Your concept is excellent; the difficulty is one thing that not sufficient people are talking intelligently about. I’m very happy that I stumbled across this in my seek for something referring to this.
Some really fantastic work on behalf of the owner of this site, utterly outstanding written content.
Hello, i think that i saw you visited my weblog thus i came to “return the favor”.I am attempting to find things to enhance my site!I suppose its ok to use a few of your ideas!!
I went over this web site and I think you have a lot of fantastic info, saved to fav (:.
Hmm it appears like your site ate my first comment (it was super long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog. I too am an aspiring blog blogger but I’m still new to the whole thing. Do you have any helpful hints for newbie blog writers? I’d definitely appreciate it.
I’ve been exploring for a bit for any high quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this website. Reading this info So i am happy to convey that I’ve a very good uncanny feeling I discovered just what I needed. I most certainly will make sure to do not forget this website and give it a glance regularly.
I was suggested this web site by my cousin. I’m not sure whether this post is written by him as nobody else know such detailed about my problem. You are incredible! Thanks!
Would you be concerned with exchanging links?
This is a very good tips especially to those new to blogosphere, brief and accurate information… Thanks for sharing this one. A must read article.
I am constantly thought about this, thanks for putting up.
I do agree with all of the concepts you’ve presented for your post. They’re very convincing and can certainly work. Still, the posts are too quick for novices. May you please prolong them a bit from subsequent time? Thank you for the post.
Hi my loved one! I wish to say that this post is awesome, great written and come with almost all significant infos. I would like to see extra posts like this .
Hello There. I found your blog using msn. This is a very well written article. I will make sure to bookmark it and come back to read more of your useful information. Thanks for the post. I will definitely return.
Merely wanna comment on few general things, The website pattern is perfect, the articles is really wonderful. “To imagine is everything, to know is nothing at all.” by Anatole France.
Awesome blog you have here but I was wanting to know if you knew of any message boards that cover the same topics discussed here? I’d really love to be a part of online community where I can get opinions from other knowledgeable people that share the same interest. If you have any suggestions, please let me know. Thanks!
I like this post, enjoyed this one thankyou for posting.
I am glad to be one of several visitors on this great internet site (:, appreciate it for putting up.
I’m still learning from you, but I’m trying to reach my goals. I certainly enjoy reading everything that is posted on your blog.Keep the tips coming. I enjoyed it!
Hola! I’ve been reading your blog for some time now and finally got the bravery to go ahead and give you a shout out from Huffman Tx! Just wanted to tell you keep up the good job!
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
Great post, you have pointed out some superb details , I besides think this s a very excellent website.
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across. It extremely helps make reading your blog significantly easier.
Hello there! Would you mind if I share your blog with my zynga group? There’s a lot of folks that I think would really appreciate your content. Please let me know. Thank you
Merely a smiling visitant here to share the love (:, btw outstanding style and design. “He profits most who serves best.” by Arthur F. Sheldon.
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a little bit, but other than that, this is magnificent blog. A great read. I’ll definitely be back.
I’ve read several good stuff here. Certainly worth bookmarking for revisiting. I wonder how much effort you put to create such a great informative site.
It is really a great and helpful piece of info. I am glad that you shared this helpful info with us. Please keep us informed like this. Thanks for sharing.
Spot on with this write-up, I actually assume this website needs much more consideration. I’ll in all probability be once more to read way more, thanks for that info.
You have brought up a very great points, appreciate it for the post.
It’s actually a great and helpful piece of info. I am happy that you shared this helpful information with us. Please keep us up to date like this. Thank you for sharing.
Good day! This is my first comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading your articles. Can you recommend any other blogs/websites/forums that cover the same topics? Many thanks!
Very interesting subject, thank you for putting up.
I do not even know the way I finished up here, but I believed this put up was great. I do not know who you might be but certainly you are going to a well-known blogger if you are not already 😉 Cheers!
I am no longer sure where you’re getting your information, but great topic. I must spend some time studying much more or figuring out more. Thanks for fantastic information I used to be on the lookout for this info for my mission.
Hmm is anyone else having problems with the pictures on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any feedback would be greatly appreciated.
Howdy would you mind letting me know which web host you’re utilizing? I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot quicker then most. Can you recommend a good internet hosting provider at a fair price? Thanks, I appreciate it!
I was just looking for this info for some time. After 6 hours of continuous Googleing, at last I got it in your web site. I wonder what’s the lack of Google strategy that don’t rank this type of informative web sites in top of the list. Normally the top sites are full of garbage.
Regards for this post, I am a big fan of this internet site would like to go along updated.
Yeah bookmaking this wasn’t a risky decision great post! .
I conceive this website has got very fantastic composed written content content.
As I web-site possessor I believe the content matter here is rattling wonderful , appreciate it for your efforts. You should keep it up forever! Good Luck.
Great post. I am facing a couple of these problems.
Wow that was odd. I just wrote an really long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyways, just wanted to say great blog!
I’ve recently started a site, the info you offer on this web site has helped me greatly. Thanks for all of your time & work.
Great tremendous issues here. I’m very satisfied to look your post. Thank you a lot and i’m looking forward to contact you. Will you please drop me a e-mail?
After study a number of of the blog posts in your web site now, and I actually like your approach of blogging. I bookmarked it to my bookmark website checklist and can be checking back soon. Pls try my web page as effectively and let me know what you think.
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your site? My blog site is in the very same area of interest as yours and my visitors would definitely benefit from a lot of the information you provide here. Please let me know if this alright with you. Regards!
I enjoy the efforts you have put in this, thankyou for all the great content.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You obviously know what youre talking about, why waste your intelligence on just posting videos to your site when you could be giving us something informative to read?
My brother recommended I might like this website. He used to be entirely right. This submit actually made my day. You can not imagine just how so much time I had spent for this info! Thank you!
I really like your writing style, good information, appreciate it for putting up :D. “Silence is more musical than any song.” by Christina G. Rossetti.
You have brought up a very fantastic points, regards for the post.
I’ve been exploring for a little for any high quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this website. Reading this information So i’m happy to convey that I’ve a very good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to don’t forget this web site and give it a look regularly.
Hey there! I just wanted to ask if you ever have any problems with hackers? My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to no data backup. Do you have any solutions to protect against hackers?
Sweet internet site, super design, really clean and apply pleasant.
Some really tremendous work on behalf of the owner of this internet site, utterly great subject matter.
I’ve been exploring for a bit for any high quality articles or blog posts on this sort of house . Exploring in Yahoo I eventually stumbled upon this site. Studying this info So i am happy to express that I’ve an incredibly excellent uncanny feeling I came upon just what I needed. I such a lot definitely will make sure to don’t omit this web site and provides it a glance regularly.
I just like the valuable info you supply in your articles. I’ll bookmark your weblog and test once more here frequently. I am reasonably certain I’ll learn many new stuff right here! Best of luck for the next!
Hi there! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a community in the same niche. Your blog provided us valuable information to work on. You have done a wonderful job!
This is a topic close to my heart cheers, where are your contact details though?
I simply could not depart your web site before suggesting that I actually loved the standard info an individual provide to your guests? Is going to be again regularly to investigate cross-check new posts
I got what you mean , regards for posting.Woh I am lucky to find this website through google. “Success is dependent on effort.” by Sophocles.
Thanks for some other informative web site. The place else may just I get that type of info written in such a perfect manner? I’ve a mission that I’m just now running on, and I have been on the look out for such information.
Dead written subject material, Really enjoyed examining.
Your style is so unique compared to many other people. Thank you for publishing when you have the opportunity,Guess I will just make this bookmarked.
Just wanna remark that you have a very decent website , I love the style it actually stands out.
Hello, Neat post. There’s a problem together with your web site in internet explorer, may check thisK IE still is the marketplace chief and a good element of other people will pass over your fantastic writing because of this problem.
I’m now not positive the place you are getting your information, but great topic. I must spend a while studying much more or working out more. Thank you for magnificent information I used to be in search of this info for my mission.
I’d have to verify with you here. Which isn’t one thing I normally do! I get pleasure from reading a publish that may make people think. Also, thanks for permitting me to comment!
Does your website have a contact page? I’m having problems locating it but, I’d like to send you an e-mail. I’ve got some recommendations for your blog you might be interested in hearing. Either way, great site and I look forward to seeing it develop over time.
Unquestionably believe that which you said. Your favorite reason appeared to be on the internet the easiest thing to be aware of. I say to you, I certainly get annoyed while people consider worries that they just do not know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people could take a signal. Will likely be back to get more. Thanks
Would you be taken with exchanging hyperlinks?
Very interesting topic, appreciate it for posting.
Howdy! I just wish to give an enormous thumbs up for the nice info you’ve here on this post. I shall be coming back to your blog for more soon.
I and also my buddies were found to be viewing the best suggestions on the blog and so then came up with a terrible suspicion I had not thanked the blog owner for those strategies. All of the guys became as a result excited to read through all of them and have certainly been taking pleasure in them. Thanks for simply being so thoughtful as well as for deciding upon variety of exceptional things millions of individuals are really eager to understand about. My very own sincere regret for not saying thanks to you sooner.
I like what you guys are up too. Such smart work and reporting! Keep up the superb works guys I have incorporated you guys to my blogroll. I think it will improve the value of my website :).
The subsequent time I read a weblog, I hope that it doesnt disappoint me as much as this one. I imply, I do know it was my option to learn, but I actually thought youd have something fascinating to say. All I hear is a bunch of whining about one thing that you may fix should you werent too busy in search of attention.
I like this post, enjoyed this one appreciate it for putting up. “Good communication is as stimulating as black coffee and just as hard to sleep after.” by Anne Morrow Lindbergh.
I must convey my respect for your generosity giving support to persons that really need help with this one issue. Your real commitment to passing the message up and down had become surprisingly productive and have constantly allowed some individuals like me to realize their ambitions. Your new interesting tips and hints denotes a whole lot to me and extremely more to my colleagues. Thank you; from all of us.
There are some fascinating time limits on this article however I don’t know if I see all of them heart to heart. There is some validity however I’ll take hold opinion until I look into it further. Good article , thanks and we want more! Added to FeedBurner as effectively
I believe this web site contains some rattling fantastic information for everyone. “The expert at anything was once a beginner.” by Hayes.
Hi would you mind sharing which blog platform you’re working with? I’m looking to start my own blog in the near future but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your layout seems different then most blogs and I’m looking for something completely unique. P.S My apologies for being off-topic but I had to ask!
Unquestionably believe that which you said. Your favorite reason seemed to be on the net the simplest thing to be aware of. I say to you, I definitely get annoyed while people consider worries that they plainly don’t know about. You managed to hit the nail upon the top and also defined out the whole thing without having side effect , people can take a signal. Will probably be back to get more. Thanks
Merely wanna input that you have a very nice web site, I enjoy the style and design it really stands out.
Hello my loved one! I want to say that this post is amazing, nice written and come with almost all vital infos. I would like to look extra posts like this.
I went over this web site and I think you have a lot of excellent info , bookmarked (:.
Hello my loved one! I wish to say that this article is awesome, great written and include approximately all vital infos. I’d like to look more posts like this.
I was reading through some of your posts on this website and I think this internet site is very informative ! Keep on posting.
You got a very wonderful website, Gladiolus I detected it through yahoo.
Thank you for the good writeup. It in fact was a amusement account it. Look advanced to more added agreeable from you! By the way, how can we communicate?
I used to be suggested this website by my cousin. I’m no longer positive whether this submit is written by way of him as no one else know such designated about my trouble. You are wonderful! Thanks!
I was reading through some of your content on this internet site and I think this website is rattling instructive! Retain putting up.
I have been examinating out many of your posts and i must say pretty nice stuff. I will make sure to bookmark your blog.
I appreciate, cause I found just what I was looking for. You’ve ended my four day long hunt! God Bless you man. Have a great day. Bye
Enjoyed studying this, very good stuff, thankyou. “While thou livest keep a good tongue in thy head.” by William Shakespeare.
Some genuinely interesting details you have written.Helped me a lot, just what I was searching for :D.
Hello my family member! I wish to say that this article is awesome, great written and include almost all vital infos. I would like to look extra posts like this .
It’s a pity you don’t have a donate button! I’d most certainly donate to this outstanding blog! I guess for now i’ll settle for bookmarking and adding your RSS feed to my Google account. I look forward to brand new updates and will share this site with my Facebook group. Talk soon!
Nice post. I learn something more challenging on different blogs everyday. It will always be stimulating to read content from other writers and practice a little something from their store. I’d prefer to use some with the content on my blog whether you don’t mind. Natually I’ll give you a link on your web blog. Thanks for sharing.
I really like your writing style, wonderful information, regards for putting up :D.
I’ve learn a few good stuff here. Certainly worth bookmarking for revisiting. I wonder how a lot effort you place to create such a wonderful informative site.
A person essentially help to make seriously posts I would state. This is the first time I frequented your web page and thus far? I surprised with the research you made to create this particular publish amazing. Wonderful job!
Thank you for the sensible critique. Me and my neighbor were just preparing to do some research about this. We got a grab a book from our local library but I think I learned more from this post. I’m very glad to see such fantastic info being shared freely out there.
I think this is among the most vital information for me. And i’m glad reading your article. But wanna remark on few general things, The web site style is ideal, the articles is really excellent :D. Good job, cheers
Some genuinely excellent content on this web site, regards for contribution. “Gratitude is merely the secret hope of further favors.” by La Rochefoucauld.
What i don’t understood is in fact how you are no longer actually much more well-appreciated than you may be now. You’re very intelligent. You realize thus significantly on the subject of this matter, produced me personally imagine it from a lot of various angles. Its like women and men don’t seem to be interested unless it is one thing to do with Girl gaga! Your individual stuffs outstanding. At all times handle it up!
You have observed very interesting details ! ps decent site.
I admire your piece of work, regards for all the great content.
As I web-site possessor I believe the content matter here is rattling great , appreciate it for your hard work. You should keep it up forever! Best of luck.
Some genuinely interesting points you have written.Assisted me a lot, just what I was searching for :D.
Very interesting subject , thanks for putting up.
The other day, while I was at work, my cousin stole my apple ipad and tested to see if it can survive a 25 foot drop, just so she can be a youtube sensation. My apple ipad is now broken and she has 83 views. I know this is entirely off topic but I had to share it with someone!
I will immediately clutch your rss as I can’t find your e-mail subscription hyperlink or newsletter service. Do you have any? Please let me understand in order that I may subscribe. Thanks.
Utterly indited subject matter, regards for selective information.
Only wanna comment on few general things, The website style is perfect, the subject matter is real superb. “Some for renown, on scraps of learning dote, And think they grow immortal as they quote.” by Edward Young.
you will have a great weblog right here! would you prefer to make some invite posts on my blog?
Been playing with okaywing and it’s okay you know. Nothing mind-blowing, but a good place to kill some time and try your luck. Give it a shot if you got some time to spare. Visitokaywing, you might like it.
Just signed up for plataformabrwin and it looks promising so far. Wide variety of games and a pretty user-friendly interface. Let’s see if I can win anything! Head over to plataformabrwin
Heard some buzz about pp88vn, supposedly they got some decent bonuses and the game selection is pretty diverse. Thinking about giving them a spin. Why not give her a try and checkout pp88vn
I have learn a few just right stuff here. Certainly price bookmarking for revisiting. I wonder how much effort you place to create such a excellent informative web site.
I was looking through some of your posts on this internet site and I conceive this website is very informative ! Retain putting up.
Good day very nice web site!! Guy .. Beautiful .. Superb .. I will bookmark your blog and take the feeds also…I’m glad to seek out so many useful information here within the submit, we need develop extra techniques in this regard, thank you for sharing. . . . . .
Very clean web site, thanks for this post.
Woah! I’m really enjoying the template/theme of this website. It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between user friendliness and visual appearance. I must say that you’ve done a great job with this. Also, the blog loads very quick for me on Safari. Excellent Blog!
Regards for helping out, superb information.
You have brought up a very wonderful points, thankyou for the post.
I’m extremely inspired together with your writing talents as neatly as with the structure for your blog. Is this a paid subject or did you modify it your self? Anyway stay up the excellent high quality writing, it’s rare to see a nice weblog like this one these days..
Just wanna comment on few general things, The website design is perfect, the subject material is very fantastic : D.
A person essentially help to make significantly posts I would state. This is the first time I frequented your website page and thus far? I surprised with the research you made to create this actual submit extraordinary. Wonderful job!
I have read a few good stuff here. Certainly value bookmarking for revisiting. I surprise how so much attempt you set to make this sort of excellent informative web site.
I am only commenting to let you know of the notable encounter my cousin’s child enjoyed reading your web site. She came to find so many things, which include what it is like to possess an incredible coaching style to let other people without problems know precisely some impossible subject areas. You actually surpassed our own expectations. Many thanks for producing those important, dependable, edifying and in addition fun tips about this topic to Ethel.
I am not sure where you are getting your information, but good topic. I needs to spend some time learning more or understanding more. Thanks for magnificent information I was looking for this information for my mission.
Today, I went to the beach front with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
I will immediately clutch your rss as I can’t to find your e-mail subscription link or e-newsletter service. Do you’ve any? Kindly permit me recognize so that I could subscribe. Thanks.
Definitely, what a great site and illuminating posts, I surely will bookmark your site.Best Regards!
I don’t even know the way I finished up right here, however I assumed this post used to be great. I don’t understand who you might be however certainly you are going to a famous blogger for those who aren’t already 😉 Cheers!
I wanted to send a small note so as to appreciate you for all of the wonderful hints you are sharing at this website. My time consuming internet lookup has at the end of the day been compensated with sensible insight to talk about with my colleagues. I would state that that we visitors actually are undeniably fortunate to live in a fantastic place with many wonderful people with beneficial methods. I feel pretty blessed to have seen your site and look forward to some more exciting minutes reading here. Thank you again for a lot of things.
Its like you read my mind! You seem to understand a lot approximately this, like you wrote the ebook in it or something. I believe that you could do with some percent to pressure the message home a little bit, however instead of that, this is wonderful blog. A fantastic read. I will certainly be back.
You can definitely see your enthusiasm within the paintings you write. The sector hopes for more passionate writers such as you who are not afraid to say how they believe. All the time follow your heart.
With havin so much written content do you ever run into any issues of plagorism or copyright violation? My website has a lot of completely unique content I’ve either created myself or outsourced but it seems a lot of it is popping it up all over the internet without my agreement. Do you know any ways to help stop content from being ripped off? I’d truly appreciate it.
You made some clear points there. I looked on the internet for the topic and found most guys will consent with your site.
Hello, you used to write great, but the last few posts have been kinda boringK I miss your tremendous writings. Past few posts are just a little bit out of track! come on!
I believe you have noted some very interesting details , regards for the post.
Together with the whole thing that appears to be building inside this particular area, many of your points of view happen to be somewhat stimulating. Even so, I am sorry, because I can not subscribe to your whole idea, all be it stimulating none the less. It appears to us that your commentary are generally not entirely rationalized and in fact you are yourself not really entirely convinced of the assertion. In any case I did enjoy reading through it.
It’s truly a nice and useful piece of information. I am happy that you just shared this useful info with us. Please stay us informed like this. Thank you for sharing.
I genuinely appreciate your piece of work, Great post.
You can certainly see your expertise in the work you write. The world hopes for more passionate writers like you who are not afraid to say how they believe. Always follow your heart.
I am also commenting to make you understand what a beneficial discovery my wife’s princess had checking your web page. She mastered a lot of issues, not to mention what it’s like to possess a marvelous helping character to make many others without difficulty know chosen advanced subject areas. You truly did more than our expectations. Many thanks for rendering those helpful, dependable, revealing and also easy tips about the topic to Janet.
Well I truly liked reading it. This article procured by you is very helpful for accurate planning.
You made some nice points there. I did a search on the issue and found most guys will agree with your website.
You are my intake, I possess few blogs and occasionally run out from to brand : (.
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
obviously like your web site but you have to check the spelling on quite a few of your posts. Several of them are rife with spelling issues and I find it very troublesome to tell the truth nevertheless I will surely come back again.
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
Hey! I could have sworn I’ve been to this website before but after reading through some of the post I realized it’s new to me. Anyhow, I’m definitely delighted I found it and I’ll be book-marking and checking back frequently!
I am not sure where you’re getting your information, but good topic. I needs to spend some time learning much more or understanding more. Thanks for wonderful information I was looking for this information for my mission.
whoah this weblog is magnificent i like studying your posts. Stay up the good work! You understand, a lot of people are searching round for this info, you can aid them greatly.
Sweet site, super pattern, real clean and employ pleasant.
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across. It extremely helps make reading your blog significantly easier.
I like this website very much so much excellent info .
You made some nice points there. I looked on the internet for the subject matter and found most guys will approve with your site.
Most of whatever you mention happens to be supprisingly accurate and it makes me wonder why I had not looked at this in this light before. Your piece truly did switch the light on for me personally as far as this specific subject matter goes. But at this time there is actually one particular issue I am not too comfy with and while I make an effort to reconcile that with the central theme of your position, let me see just what all the rest of your readers have to point out.Very well done.
Thank you a lot for providing individuals with remarkably wonderful possiblity to discover important secrets from this site. It really is so pleasing and as well , packed with a good time for me and my office acquaintances to search your site a minimum of 3 times in one week to study the new things you have. And indeed, I am usually impressed considering the great concepts served by you. Certain 3 points in this posting are particularly the simplest we’ve had.
I went over this website and I believe you have a lot of superb info, saved to my bookmarks (:.
Very interesting info !Perfect just what I was looking for!
It’s actually a nice and useful piece of information. I’m satisfied that you shared this helpful information with us. Please stay us up to date like this. Thanks for sharing.
Superb blog you have here but I was wanting to know if you knew of any community forums that cover the same topics discussed in this article? I’d really like to be a part of group where I can get opinions from other experienced people that share the same interest. If you have any recommendations, please let me know. Bless you!
Great goods from you, man. I have understand your stuff previous to and you are just extremely magnificent. I really like what you’ve acquired here, really like what you are stating and the way in which you say it. You make it enjoyable and you still care for to keep it smart. I can’t wait to read much more from you. This is really a wonderful website.
magnificent post, very informative. I wonder why the other experts of this sector do not notice this. You must continue your writing. I am confident, you have a great readers’ base already!
Greetings! I know this is kinda off topic but I was wondering which blog platform are you using for this website? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform. I would be awesome if you could point me in the direction of a good platform.
You can certainly see your expertise within the work you write. The sector hopes for even more passionate writers such as you who aren’t afraid to say how they believe. Always follow your heart. “A second wife is hateful to the children of the first a viper is not more hateful.” by Euripides.
Thanks a lot for sharing this with all of us you actually know what you’re talking about! Bookmarked. Kindly also visit my site =). We could have a link exchange contract between us!
I’ve been exploring for a little bit for any high-quality articles or weblog posts in this kind of space . Exploring in Yahoo I eventually stumbled upon this site. Reading this info So i am glad to exhibit that I have a very just right uncanny feeling I came upon exactly what I needed. I so much certainly will make certain to do not overlook this web site and provides it a glance on a constant basis.
so much fantastic info on here, :D.
Thanks for sharing superb informations. Your site is so cool. I am impressed by the details that you have on this blog. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for more articles. You, my friend, ROCK! I found simply the info I already searched all over the place and just could not come across. What a great web-site.
Hey there, You have done a fantastic job. I’ll definitely digg it and personally recommend to my friends. I am confident they will be benefited from this site.
I was just looking for this information for some time. After 6 hours of continuous Googleing, finally I got it in your website. I wonder what’s the lack of Google strategy that do not rank this type of informative web sites in top of the list. Usually the top sites are full of garbage.
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something. I think that you can do with a few pics to drive the message home a little bit, but other than that, this is fantastic blog. A fantastic read. I’ll definitely be back.
Great work! This is the type of information that should be shared around the net. Shame on the search engines for not positioning this post higher! Come on over and visit my website . Thanks =)
Simply a smiling visitor here to share the love (:, btw outstanding style.
I as well conceive so , perfectly composed post! .
Just wanna input on few general things, The website style and design is perfect, the content is real excellent : D.
Real wonderful visual appeal on this internet site, I’d rate it 10 10.
I am not really excellent with English but I line up this really easy to translate.
I respect your piece of work, thanks for all the good posts.
Thanks for another fantastic article. The place else may anyone get that type of information in such a perfect method of writing? I’ve a presentation subsequent week, and I’m on the search for such info.
Some really nice stuff on this web site, I like it.
It’s actually a great and useful piece of information. I am satisfied that you shared this helpful info with us. Please stay us up to date like this. Thank you for sharing.
I think other web site proprietors should take this website as an model, very clean and magnificent user genial style and design, as well as the content. You are an expert in this topic!
Great line up. We will be linking to this great article on our site. Keep up the good writing.
Thank you, I have recently been looking for information approximately this topic for a while and yours is the best I have came upon till now. However, what in regards to the conclusion? Are you positive about the source?
Perfect work you have done, this site is really cool with good info .
I’m no longer certain the place you’re getting your information, but good topic. I must spend some time finding out more or figuring out more. Thank you for magnificent information I was searching for this information for my mission.
This site is my inhalation, very good style and design and perfect articles.
Use um formatador ABNT online para organizar TCC, artigo e monografia com mais rapidez, menos erro manual e estrutura acadêmica correta.
I know this if off topic but I’m looking into starting my own weblog and was curious what all is required to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very web smart so I’m not 100 sure. Any suggestions or advice would be greatly appreciated. Kudos
Rattling instructive and great bodily structure of content material, now that’s user friendly (:.
Use um formatador ABNT online para organizar TCC, artigo e monografia com mais rapidez, menos erro manual e estrutura acadêmica correta.
This is a topic close to my heart cheers, where are your contact details though?
Its good as your other posts : D, thanks for posting. “Before borrowing money from a friend it’s best to decide which you need most.” by Joe Moore.
Heya i am for the first time here. I came across this board and I find It really helpful & it helped me out much. I hope to provide one thing again and help others such as you helped me.
I enjoy your writing style genuinely loving this website .
Great post. I am facing a couple of these problems.
I’m not sure where you are getting your information, but great topic. I needs to spend some time learning much more or working out more. Thank you for fantastic information I used to be searching for this information for my mission.
I will right away grab your rss as I can’t in finding your email subscription hyperlink or e-newsletter service. Do you’ve any? Kindly allow me know so that I could subscribe. Thanks.
That is very interesting, You’re a very skilled blogger. I have joined your feed and stay up for in the hunt for more of your fantastic post. Also, I’ve shared your web site in my social networks!
I’ve been exploring for a little for any high-quality articles or blog posts on this kind of area . Exploring in Yahoo I at last stumbled upon this web site. Reading this information So i am happy to convey that I have an incredibly good uncanny feeling I discovered just what I needed. I most certainly will make sure to don’t forget this website and give it a glance on a constant basis.
There are definitely loads of details like that to take into consideration. That could be a nice level to deliver up. I provide the thoughts above as basic inspiration however clearly there are questions like the one you bring up the place a very powerful thing will be working in honest good faith. I don?t know if best practices have emerged around issues like that, however I am sure that your job is clearly identified as a fair game. Both boys and girls feel the influence of only a second’s pleasure, for the remainder of their lives.
It’s in reality a nice and useful piece of info. I am glad that you simply shared this helpful information with us. Please keep us up to date like this. Thanks for sharing.
I would like to thnkx for the efforts you have put in writing this blog. I am hoping the same high-grade blog post from you in the upcoming as well. In fact your creative writing abilities has inspired me to get my own blog now. Really the blogging is spreading its wings quickly. Your write up is a good example of it.
Having read this I thought it was very informative. I appreciate you taking the time and effort to put this article together. I once again find myself spending way to much time both reading and commenting. But so what, it was still worth it!
Greetings! I know this is somewhat off topic but I was wondering if you knew where I could get a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having trouble finding one? Thanks a lot!
It’s a shame you don’t have a donate button! I’d most certainly donate to this brilliant blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account. I look forward to new updates and will share this website with my Facebook group. Chat soon!
Hello there, I discovered your web site via Google at the same time as looking for a related subject, your site got here up, it seems to be great. I have bookmarked it in my google bookmarks.
Its great as your other posts : D, thankyou for putting up. “A lost battle is a battle one thinks one has lost.” by Ferdinand Foch.
My brother suggested I might like this blog. He was entirely right. This post truly made my day. You cann’t imagine just how much time I had spent for this info! Thanks!
It’s really a great and helpful piece of info. I’m glad that you shared this useful info with us. Please keep us informed like this. Thanks for sharing.
I like this post, enjoyed this one appreciate it for putting up. “What is a thousand years Time is short for one who thinks, endless for one who yearns.” by Alain.
Usually I don’t read article on blogs, but I wish to say that this write-up very forced me to check out and do it! Your writing style has been surprised me. Thanks, very nice article.
I discovered your blog site on google and check a few of your early posts. Continue to keep up the very good operate. I just additional up your RSS feed to my MSN News Reader. Seeking forward to reading more from you later on!…
We are a group of volunteers and starting a new scheme in our community. Your web site offered us with useful information to paintings on. You’ve performed an impressive task and our entire community can be grateful to you.
An interesting discussion is worth comment. I think that you should write more on this topic, it might not be a taboo subject but generally people are not enough to speak on such topics. To the next. Cheers
Hi there! Do you use Twitter? I’d like to follow you if that would be ok. I’m absolutely enjoying your blog and look forward to new posts.
I liked as much as you will receive performed right here. The caricature is tasteful, your authored material stylish. however, you command get bought an edginess over that you wish be handing over the following. in poor health surely come more formerly again as exactly the similar just about very incessantly inside of case you defend this increase.
so much superb info on here, :D.
I am really inspired together with your writing talents and also with the format in your weblog. Is that this a paid subject or did you customize it yourself? Anyway keep up the excellent high quality writing, it’s uncommon to peer a great weblog like this one nowadays..
I believe this web site contains some really good information for everyone :D. “Calamity is the test of integrity.” by Samuel Richardson.
I’d must verify with you here. Which is not one thing I usually do! I get pleasure from reading a submit that will make individuals think. Also, thanks for allowing me to remark!
You have mentioned very interesting details ! ps nice site.
Would you be desirous about exchanging hyperlinks?
Hola! I’ve been following your website for a long time now and finally got the courage to go ahead and give you a shout out from Lubbock Tx! Just wanted to tell you keep up the excellent job!
You really make it appear really easy together with your presentation however I to find this matter to be actually one thing which I think I would never understand. It seems too complex and very vast for me. I’m looking ahead for your next publish, I will try to get the grasp of it!
Fascinating blog! Is your theme custom made or did you download it from somewhere? A theme like yours with a few simple adjustements would really make my blog stand out. Please let me know where you got your design. Cheers
Some genuinely prime articles on this site, saved to fav.
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.
I went over this web site and I believe you have a lot of excellent info, saved to favorites (:.
Sweet internet site, super design, very clean and employ pleasant.
I was wondering if you ever considered changing the layout of your blog? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having 1 or two images. Maybe you could space it out better?
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept chatting about this. I will forward this article to him. Pretty sure he will have a good read. Many thanks for sharing!
Hi there, You have done an excellent job. I’ll certainly digg it and personally suggest to my friends. I am confident they will be benefited from this website.
I together with my pals were following the nice pointers found on your website and then immediately got a horrible feeling I had not expressed respect to you for those secrets. The young men were definitely so stimulated to study them and now have unquestionably been making the most of these things. Appreciate your being well accommodating and also for choosing some remarkable topics most people are really needing to understand about. Our own sincere apologies for not expressing appreciation to sooner.
Some truly wonderful posts on this website, regards for contribution. “Give me the splendid silent sun with all his beams full-dazzling.” by Walt Whitman.
I like this site very much, Its a very nice berth to read and find info . “The superior man is modest in his speech, but exceeds in his actions.” by Confucius.
Hi, Neat post. There is a problem along with your web site in web explorer, would test this?K IE nonetheless is the marketplace leader and a huge element of folks will omit your excellent writing due to this problem.
I was reading through some of your articles on this site and I conceive this website is very informative! Keep on posting.
You could certainly see your skills in the paintings you write. The sector hopes for even more passionate writers like you who are not afraid to say how they believe. All the time follow your heart. “If you feel yourself falling, let go and glide.” by Steffen Francisco.
I truly appreciate your work, Great post.
I like this site very much, Its a rattling nice office to read and obtain information. “You can never learn less, you can only learn more.” by Richard Buckminster Fuller.
Excellent read, I just passed this onto a colleague who was doing some research on that. And he actually bought me lunch as I found it for him smile Therefore let me rephrase that: Thanks for lunch! “The capacity to care is what gives life its most deepest significance.” by Pablo Casals.
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
I am glad to be a visitor of this double dyed blog! , appreciate it for this rare information! .
Wow! Thank you! I continually needed to write on my website something like that. Can I take a part of your post to my website?
Very interesting information!Perfect just what I was looking for!
Wow! Thank you! I constantly wanted to write on my blog something like that. Can I implement a fragment of your post to my blog?
Some really wonderful work on behalf of the owner of this website , absolutely outstanding written content.
excellent post.Never knew this, appreciate it for letting me know.
Hi there! I simply wish to give a huge thumbs up for the nice data you might have right here on this post. I will likely be coming back to your blog for more soon.
Yay google is my world beater aided me to find this outstanding site! .
Woh I like your articles, bookmarked! .
Hi there would you mind sharing which blog platform you’re using? I’m going to start my own blog soon but I’m having a hard time choosing between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your layout seems different then most blogs and I’m looking for something unique. P.S My apologies for being off-topic but I had to ask!
Great goods from you, man. I’ve understand your stuff prior to and you are simply extremely magnificent. I actually like what you have obtained right here, certainly like what you’re stating and the way through which you are saying it. You are making it enjoyable and you still care for to keep it smart. I cant wait to read much more from you. This is actually a wonderful website.
Good info. Lucky me I reach on your website by accident, I bookmarked it.
I really like your writing style, excellent info , thankyou for putting up :D.
I haven’t checked in here for a while as I thought it was getting boring, but the last several posts are good quality so I guess I will add you back to my everyday bloglist. You deserve it my friend 🙂
Lovely just what I was searching for.Thanks to the author for taking his clock time on this one.
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
fantastic post, very informative. I ponder why the opposite specialists of this sector do not realize this. You should proceed your writing. I’m confident, you have a great readers’ base already!
Thanks , I have recently been searching for info about this topic for ages and yours is the greatest I’ve discovered so far. But, what about the bottom line? Are you sure about the source?
Aw, this was a really nice post. In thought I wish to put in writing like this additionally – taking time and precise effort to make an excellent article… however what can I say… I procrastinate alot and by no means seem to get something done.
Hey There. I found your weblog the use of msn. This is a really well written article. I’ll be sure to bookmark it and return to learn more of your useful info. Thank you for the post. I’ll definitely comeback.
magnificent issues altogether, you simply won a new reader. What may you suggest about your submit that you simply made some days in the past? Any certain?
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something. I think that you could do with a few pics to drive the message home a little bit, but other than that, this is great blog. A great read. I will certainly be back.
Very interesting subject, thanks for putting up. “Men who never get carried away should be.” by Malcolm Forbes.
Very clean web site, thankyou for this post.
I have read several just right stuff here. Certainly value bookmarking for revisiting. I wonder how so much attempt you put to create this sort of great informative web site.
you are truly a good webmaster. The site loading velocity is incredible. It sort of feels that you’re doing any unique trick. Moreover, The contents are masterwork. you have performed a excellent activity in this subject!
great post.Ne’er knew this, regards for letting me know.
Very excellent visual appeal on this web site, I’d rate it 10 10.
Awesome website you have here but I was curious about if you knew of any community forums that cover the same topics talked about here? I’d really like to be a part of group where I can get opinions from other experienced individuals that share the same interest. If you have any recommendations, please let me know. Kudos!
naturally like your website but you have to take a look at the spelling on several of your posts. Many of them are rife with spelling problems and I in finding it very troublesome to inform the truth however I’ll definitely come back again.
I like what you guys are up also. Such clever work and reporting! Keep up the excellent works guys I’ve incorporated you guys to my blogroll. I think it’ll improve the value of my web site 🙂
Hi! I could have sworn I’ve been to this site before but after checking through some of the post I realized it’s new to me. Anyways, I’m definitely delighted I found it and I’ll be bookmarking and checking back frequently!
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across. It extremely helps make reading your blog significantly easier.
With havin so much written content do you ever run into any issues of plagorism or copyright infringement? My website has a lot of exclusive content I’ve either authored myself or outsourced but it looks like a lot of it is popping it up all over the internet without my agreement. Do you know any techniques to help stop content from being ripped off? I’d truly appreciate it.
Greetings! Very helpful advice on this article! It is the little changes that make the biggest changes. Thanks a lot for sharing!
I’ve recently started a site, the info you offer on this site has helped me tremendously. Thanks for all of your time & work.
you have a great blog here! would you like to make some invite posts on my blog?
Saved as a favorite, I really like your blog!
Oh my goodness! a tremendous article dude. Thanks Nonetheless I’m experiencing issue with ur rss . Don’t know why Unable to subscribe to it. Is there anybody getting equivalent rss drawback? Anyone who is aware of kindly respond. Thnkx
you are really a good webmaster. The web site loading speed is incredible. It seems that you are doing any unique trick. In addition, The contents are masterpiece. you have done a excellent job on this topic!
Perfectly indited content material, Really enjoyed looking at.
Your place is valueble for me. Thanks!…
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but other than that, this is fantastic blog. A fantastic read. I’ll certainly be back.
Loving the info on this web site, you have done great job on the blog posts.
Thanks for sharing excellent informations. Your website is very cool. I am impressed by the details that you’ve on this site. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found simply the information I already searched all over the place and simply couldn’t come across. What a great web-site.
Merely wanna tell that this is invaluable, Thanks for taking your time to write this.
I loved as much as you’ll receive carried out right here. The sketch is attractive, your authored material stylish. nonetheless, you command get bought an shakiness over that you wish be delivering the following. unwell unquestionably come further formerly again since exactly the same nearly very often inside case you shield this increase.
Great blog! Do you have any tips and hints for aspiring writers? I’m hoping to start my own website soon but I’m a little lost on everything. Would you recommend starting with a free platform like WordPress or go for a paid option? There are so many options out there that I’m totally confused .. Any recommendations? Thanks!
Hello.This article was really interesting, especially since I was searching for thoughts on this subject last couple of days.
You could definitely see your expertise within the work you write. The world hopes for even more passionate writers like you who aren’t afraid to say how they believe. At all times go after your heart. “Experience is a good school, but the fees are high.” by Heinrich Heine.
Everything is very open and very clear explanation of issues. was truly information. Your website is very useful. Thanks for sharing.
Only a smiling visitant here to share the love (:, btw outstanding style. “Reading well is one of the great pleasures that solitude can afford you.” by Harold Bloom.
I’m now not positive where you’re getting your information, however good topic. I needs to spend a while finding out much more or working out more. Thanks for wonderful information I was in search of this info for my mission.
I like this web blog so much, bookmarked.
What i don’t realize is if truth be told how you are not really much more neatly-preferred than you might be right now. You are so intelligent. You know thus considerably with regards to this subject, produced me in my opinion consider it from numerous various angles. Its like men and women are not fascinated except it’s one thing to do with Lady gaga! Your own stuffs nice. At all times handle it up!
Wonderful website. Plenty of useful info here. I am sending it to several buddies ans additionally sharing in delicious. And of course, thanks for your sweat!
Youre so cool! I dont suppose Ive read anything like this before. So good to find any individual with some authentic ideas on this subject. realy thank you for starting this up. this website is one thing that is wanted on the internet, someone with slightly originality. useful job for bringing something new to the web!
The next time I learn a blog, I hope that it doesnt disappoint me as a lot as this one. I mean, I know it was my option to learn, however I really thought youd have one thing attention-grabbing to say. All I hear is a bunch of whining about something that you possibly can fix in case you werent too busy searching for attention.
Hello, Neat post. There’s a problem along with your site in web explorer, might check this… IE nonetheless is the marketplace leader and a good section of other people will miss your magnificent writing because of this problem.
I will immediately grab your rss feed as I can not find your e-mail subscription link or e-newsletter service. Do you’ve any? Kindly let me know in order that I could subscribe. Thanks.
This website is my inhalation, really wonderful design and perfect subject material.
Hi my loved one! I want to say that this article is awesome, nice written and include approximately all significant infos. I’d like to look extra posts like this.
You have brought up a very great points, appreciate it for the post.
Keep up the good piece of work, I read few posts on this internet site and I believe that your weblog is rattling interesting and holds circles of good info .
You are my aspiration, I own few blogs and occasionally run out from to post : (.
Do you have a spam issue on this blog; I also am a blogger, and I was wondering your situation; many of us have created some nice methods and we are looking to exchange techniques with others, be sure to shoot me an email if interested.
We stumbled over here different web page and thought I should check things out. I like what I see so now i am following you. Look forward to finding out about your web page repeatedly.
I got what you mean ,saved to fav, very nice internet site.
I love it when people come together and share opinions, great blog, keep it up.
I’m usually to blogging and i actually respect your content. The article has really peaks my interest. I am going to bookmark your site and hold checking for new information.
I liked up to you will obtain performed right here. The sketch is tasteful, your authored subject matter stylish. nonetheless, you command get bought an nervousness over that you would like be handing over the following. unwell unquestionably come further until now again as precisely the similar just about a lot steadily inside case you shield this increase.
I went over this internet site and I think you have a lot of fantastic info , saved to favorites (:.
Some really interesting information, well written and broadly speaking user friendly.
Thank you for any other informative site. Where else may just I am getting that kind of info written in such a perfect way? I’ve a challenge that I’m simply now working on, and I’ve been at the glance out for such info.
I wish to show my gratitude for your kindness in support of people that need help on your concern. Your personal commitment to passing the message up and down became astonishingly interesting and has continuously encouraged workers just like me to arrive at their goals. The warm and helpful tips and hints implies a whole lot to me and still more to my peers. Many thanks; from everyone of us.
I like this site because so much useful stuff on here :D.
certainly like your web-site but you need to check the spelling on quite a few of your posts. Many of them are rife with spelling problems and I find it very bothersome to inform the reality on the other hand I’ll certainly come again again.
I am not real superb with English but I find this rattling leisurely to interpret.
Nice read, I just passed this onto a colleague who was doing some research on that. And he just bought me lunch because I found it for him smile Therefore let me rephrase that: Thank you for lunch! “By nature, men are nearly alike by practice, they get to be wide apart.” by Confucius.
I just couldn’t leave your website before suggesting that I really enjoyed the standard info an individual supply for your visitors? Is going to be again steadily to check out new posts
I like this post, enjoyed this one thankyou for posting.
great post.Ne’er knew this, thankyou for letting me know.
I’m extremely inspired with your writing talents as neatly as with the layout for your weblog. Is this a paid subject or did you customize it your self? Anyway stay up the nice quality writing, it’s rare to see a great weblog like this one today..
Thank you for sharing superb informations. Your web-site is very cool. I am impressed by the details that you have on this blog. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for extra articles. You, my pal, ROCK! I found just the info I already searched everywhere and simply couldn’t come across. What a perfect web-site.
I do not even know how I ended up here, but I thought this post was good. I don’t know who you are but definitely you’re going to a famous blogger if you are not already 😉 Cheers!
I’ve learn several just right stuff here. Definitely price bookmarking for revisiting. I wonder how much effort you place to create the sort of great informative web site.
We’re a bunch of volunteers and opening a new scheme in our community. Your website provided us with helpful info to paintings on. You’ve performed a formidable process and our entire neighborhood will probably be thankful to you.
Very interesting topic, appreciate it for posting.
Some really tremendous work on behalf of the owner of this website , dead outstanding subject material.
You completed various fine points there. I did a search on the matter and found the majority of folks will agree with your blog.
Nice post. I study something tougher on totally different blogs everyday. It would at all times be stimulating to learn content material from different writers and apply a little something from their store. I’d prefer to use some with the content on my weblog whether you don’t mind. Natually I’ll provide you with a link in your internet blog. Thanks for sharing.
I have been exploring for a little bit for any high-quality articles or weblog posts in this kind of space . Exploring in Yahoo I at last stumbled upon this web site. Studying this info So i am satisfied to convey that I have a very just right uncanny feeling I found out just what I needed. I such a lot definitely will make certain to don’t fail to remember this website and give it a look on a constant basis.
Yeah bookmaking this wasn’t a high risk conclusion outstanding post! .
Amazing blog! Is your theme custom made or did you download it from somewhere? A theme like yours with a few simple adjustements would really make my blog shine. Please let me know where you got your theme. Thank you
I believe you have remarked some very interesting points, regards for the post.
I’m not sure exactly why but this weblog is loading very slow for me. Is anyone else having this problem or is it a issue on my end? I’ll check back later on and see if the problem still exists.
I think this is one of the most significant info for me. And i’m glad reading your article. But should remark on some general things, The website style is wonderful, the articles is really excellent :D. Good job, cheers
Lovely just what I was looking for.Thanks to the author for taking his time on this one.
What i don’t understood is in truth how you are now not actually a lot more well-preferred than you might be now. You’re very intelligent. You recognize thus considerably with regards to this topic, made me in my view imagine it from numerous various angles. Its like women and men are not involved until it’s something to accomplish with Girl gaga! Your individual stuffs nice. Always care for it up!
Keep functioning ,remarkable job!
Spot on with this write-up, I truly think this web site needs rather more consideration. I’ll in all probability be once more to learn rather more, thanks for that info.
WONDERFUL Post.thanks for share..extra wait .. …
It is perfect time to make some plans for the future and it’s time to be happy. I’ve read this post and if I could I wish to suggest you some interesting things or advice. Maybe you could write next articles referring to this article. I desire to read more things about it!
I just couldn’t depart your web site before suggesting that I really enjoyed the standard information a person provide for your visitors? Is going to be back often in order to check up on new posts
With havin so much content and articles do you ever run into any issues of plagorism or copyright violation? My site has a lot of exclusive content I’ve either created myself or outsourced but it appears a lot of it is popping it up all over the internet without my authorization. Do you know any methods to help prevent content from being stolen? I’d definitely appreciate it.
My programmer is trying to persuade me to move to .net from PHP. I have always disliked the idea because of the expenses. But he’s tryiong none the less. I’ve been using Movable-type on numerous websites for about a year and am anxious about switching to another platform. I have heard excellent things about blogengine.net. Is there a way I can import all my wordpress content into it? Any kind of help would be really appreciated!
Good day! This is kind of off topic but I need some help from an established blog. Is it tough to set up your own blog? I’m not very techincal but I can figure things out pretty quick. I’m thinking about creating my own but I’m not sure where to begin. Do you have any tips or suggestions? With thanks
This web site is really a walk-through for all of the info you wanted about this and didn’t know who to ask. Glimpse here, and you’ll definitely discover it.
This web page is mostly a stroll-by way of for all the info you wished about this and didn’t know who to ask. Glimpse right here, and you’ll definitely uncover it.
Have you ever considered about adding a little bit more than just your articles? I mean, what you say is fundamental and all. However think of if you added some great pictures or video clips to give your posts more, “pop”! Your content is excellent but with pics and videos, this website could definitely be one of the greatest in its niche. Good blog!
I have learn a few good stuff here. Definitely price bookmarking for revisiting. I wonder how so much attempt you set to make such a magnificent informative web site.
Hello, you used to write magnificent, but the last several posts have been kinda boring?K I miss your tremendous writings. Past few posts are just a little bit out of track! come on!
Hiya! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly? My blog looks weird when browsing from my iphone 4. I’m trying to find a theme or plugin that might be able to fix this problem. If you have any recommendations, please share. Appreciate it!
Your home is valueble for me. Thanks!…
Glad to be one of the visitors on this awing web site : D.
It is appropriate time to make a few plans for the future and it’s time to be happy. I have read this submit and if I could I wish to counsel you some interesting issues or tips. Perhaps you can write next articles regarding this article. I want to read more issues about it!
Thanks for the auspicious writeup. It in reality was a leisure account it. Glance complex to far added agreeable from you! However, how could we keep in touch?
I am not really good with English but I find this rattling easy to interpret.
I would like to thank you for the efforts you’ve put in writing this blog. I am hoping the same high-grade website post from you in the upcoming as well. Actually your creative writing skills has inspired me to get my own website now. Actually the blogging is spreading its wings fast. Your write up is a great example of it.
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
Terrific work! That is the type of information that should be shared around the net. Disgrace on Google for not positioning this publish higher! Come on over and talk over with my web site . Thanks =)
I just could not go away your website before suggesting that I really enjoyed the usual information a person provide for your visitors? Is gonna be again often in order to check up on new posts.
I’m still learning from you, as I’m trying to achieve my goals. I definitely love reading all that is posted on your site.Keep the posts coming. I loved it!
It’s onerous to seek out educated individuals on this matter, but you sound like you understand what you’re talking about! Thanks
Great remarkable things here. I am very satisfied to look your post. Thank you so much and i’m looking forward to contact you. Will you kindly drop me a mail?
There’s noticeably a bundle to know about this. I assume you made sure nice points in options also.
I’m truly enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a developer to create your theme? Exceptional work!
I appreciate, cause I found exactly what I was looking for. You’ve ended my four day long hunt! God Bless you man. Have a nice day. Bye
Hi there this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding experience so I wanted to get guidance from someone with experience. Any help would be enormously appreciated!
Woah! I’m really digging the template/theme of this site. It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between superb usability and appearance. I must say you have done a great job with this. In addition, the blog loads super fast for me on Internet explorer. Outstanding Blog!
There is clearly a bundle to know about this. I consider you made various good points in features also.
I have recently started a site, the info you provide on this web site has helped me greatly. Thanks for all of your time & work.
I saw a lot of website but I conceive this one has something extra in it in it
Just what I was looking for, regards for putting up.
I gotta favorite this site it seems invaluable very beneficial
I was very pleased to find this web-site.I wanted to thanks for your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
I’ve read some excellent stuff here. Certainly worth bookmarking for revisiting. I wonder how so much effort you put to create this sort of great informative site.
I conceive you have mentioned some very interesting points, thanks for the post.
What’s Going down i am new to this, I stumbled upon this I’ve found It positively useful and it has aided me out loads. I hope to give a contribution & aid other customers like its helped me. Good job.
Thanks a bunch for sharing this with all of us you really know what you’re talking about! Bookmarked. Please also visit my site =). We could have a link exchange contract between us!
As I website possessor I think the subject material here is real wonderful, appreciate it for your efforts.
I conceive this website has got some rattling superb information for everyone :D.
Thank you for another great post. Where else could anyone get that kind of information in such an ideal way of writing? I have a presentation next week, and I’m on the look for such information.
Hiya very nice blog!! Man .. Excellent .. Amazing .. I’ll bookmark your site and take the feeds also…I am glad to seek out so many useful info here in the put up, we want work out more techniques on this regard, thank you for sharing. . . . . .
Everything is very open and very clear explanation of issues. was truly information. Your website is very useful. Thanks for sharing.
Hi! I’m at work browsing your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the superb work!
I’ve been exploring for a little for any high quality articles or blog posts on this kind of area . Exploring in Yahoo I eventually stumbled upon this site. Studying this info So i am glad to show that I have an incredibly just right uncanny feeling I discovered just what I needed. I most unquestionably will make certain to do not put out of your mind this website and provides it a glance on a relentless basis.
Great post however , I was wanting to know if you could write a litte more on this topic? I’d be very thankful if you could elaborate a little bit further. Cheers!
I love the efforts you have put in this, thankyou for all the great posts.
Excellent read, I just passed this onto a friend who was doing a little research on that. And he actually bought me lunch because I found it for him smile Therefore let me rephrase that: Thanks for lunch! “Dreams are real while they last. Can we say more of life” by Henry Havelock Ellis.
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
certainly like your web-site but you need to check the spelling on quite a few of your posts. Many of them are rife with spelling issues and I find it very bothersome to tell the truth nevertheless I’ll certainly come back again.
Hello there! This is my first comment here so I just wanted to give a quick shout out and say I genuinely enjoy reading through your blog posts. Can you suggest any other blogs/websites/forums that deal with the same topics? Thank you so much!
This is a topic close to my heart cheers, where are your contact details though?
I have learn several excellent stuff here. Definitely price bookmarking for revisiting. I wonder how so much effort you place to make any such wonderful informative site.
Please let me know if you’re looking for a author for your blog. You have some really great posts and I feel I would be a good asset. If you ever want to take some of the load off, I’d really like to write some material for your blog in exchange for a link back to mine. Please send me an e-mail if interested. Many thanks!
Very interesting information!Perfect just what I was searching for!
Wow! This can be one particular of the most beneficial blogs We have ever arrive across on this subject. Basically Excellent. I am also a specialist in this topic so I can understand your effort.
Aw, this was a very nice post. In thought I want to put in writing like this additionally – taking time and actual effort to make an excellent article… but what can I say… I procrastinate alot and by no means appear to get something done.
Real informative and great complex body part of written content, now that’s user friendly (:.
I rattling pleased to find this web site on bing, just what I was searching for : D also bookmarked.
I am constantly browsing online for articles that can help me. Thx!
Woah! I’m really loving the template/theme of this website. It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between usability and appearance. I must say you have done a excellent job with this. In addition, the blog loads extremely quick for me on Firefox. Outstanding Blog!
Hey very cool blog!! Man .. Excellent .. Amazing .. I’ll bookmark your website and take the feeds also…I’m happy to find numerous useful information here in the post, we need work out more techniques in this regard, thanks for sharing. . . . . .
you’re actually a excellent webmaster. The website loading velocity is incredible. It kind of feels that you are doing any unique trick. In addition, The contents are masterwork. you’ve done a excellent activity on this matter!
An attention-grabbing dialogue is price comment. I feel that it’s best to write extra on this subject, it may not be a taboo subject however generally individuals are not sufficient to speak on such topics. To the next. Cheers
Whats Going down i’m new to this, I stumbled upon this I have discovered It positively useful and it has helped me out loads. I’m hoping to contribute & help other customers like its aided me. Good job.
This web site is really a walk-through for all of the info you wanted about this and didn’t know who to ask. Glimpse here, and you’ll definitely discover it.
I was curious if you ever considered changing the structure of your blog? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or 2 images. Maybe you could space it out better?
Great line up. We will be linking to this great article on our site. Keep up the good writing.
I was just looking for this info for some time. After six hours of continuous Googleing, finally I got it in your site. I wonder what’s the lack of Google strategy that don’t rank this type of informative sites in top of the list. Generally the top websites are full of garbage.
Its wonderful as your other articles : D, regards for posting.
I and my pals appeared to be analyzing the good tactics from your web page and then all of a sudden came up with a horrible suspicion I had not thanked you for those secrets. The young men were definitely certainly joyful to read through them and have in effect quite simply been loving those things. We appreciate you simply being quite thoughtful as well as for going for certain fabulous subject areas most people are really desperate to understand about. My personal sincere apologies for not saying thanks to sooner.
I like this post, enjoyed this one thanks for posting. “The difference between stupidity and genius is that genius has its limits.” by Albert Einstein.
Hi there, I found your website by means of Google whilst looking for a related topic, your site got here up, it looks great. I’ve bookmarked it in my google bookmarks.
This design is steller! You certainly know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job. I really enjoyed what you had to say, and more than that, how you presented it. Too cool!
you’re in point of fact a good webmaster. The web site loading speed is amazing. It seems that you are doing any distinctive trick. Furthermore, The contents are masterpiece. you have done a magnificent job in this subject!
You made certain nice points there. I did a search on the theme and found the majority of folks will agree with your blog.
Pretty nice post. I simply stumbled upon your blog and wished to mention that I’ve really enjoyed browsing your weblog posts. After all I will be subscribing for your rss feed and I am hoping you write again very soon!
I went over this website and I think you have a lot of superb info, bookmarked (:.
You have brought up a very superb points, thanks for the post.
Simply wish to say your article is as astounding. The clearness in your post is just cool and i could assume you’re an expert on this subject. Fine with your permission allow me to grab your RSS feed to keep updated with forthcoming post. Thanks a million and please continue the gratifying work.
Thanks for any other excellent article. The place else may anyone get that kind of info in such a perfect method of writing? I’ve a presentation subsequent week, and I am on the search for such info.
At this time it sounds like WordPress is the top blogging platform out there right now. (from what I’ve read) Is that what you’re using on your blog?
hello there and thanks on your information – I’ve definitely picked up anything new from right here. I did then again experience some technical issues the usage of this web site, as I skilled to reload the website many times previous to I could get it to load properly. I were wondering in case your web host is OK? No longer that I’m complaining, but sluggish loading circumstances occasions will often affect your placement in google and could harm your quality ranking if ads and ***********|advertising|advertising|advertising and *********** with Adwords. Well I am adding this RSS to my e-mail and could glance out for much extra of your respective interesting content. Ensure that you replace this again soon..
I truly value your work, Great post.
Enjoyed examining this, very good stuff, regards.
I was wondering if you ever considered changing the page layout of your site? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having 1 or two images. Maybe you could space it out better?
I haven’t checked in here for a while because I thought it was getting boring, but the last several posts are good quality so I guess I’ll add you back to my daily bloglist. You deserve it my friend 🙂
Hi there, I discovered your website by the use of Google at the same time as searching for a similar topic, your website came up, it looks great. I have bookmarked it in my google bookmarks.
Hello, i think that i saw you visited my web site so i came to “return the favor”.I’m trying to find things to enhance my website!I suppose its ok to use a few of your ideas!!
Thanks a lot for giving everyone an extraordinarily marvellous chance to read articles and blog posts from this website. It really is so great and packed with a lot of fun for me and my office mates to search your website more than thrice every week to learn the new secrets you have got. Not to mention, I am just always motivated considering the tremendous principles served by you. Certain 4 ideas in this post are really the most effective I have ever had.
I regard something truly interesting about your website so I saved to bookmarks.
You made some first rate points there. I looked on the internet for the difficulty and located most individuals will associate with along with your website.
You have brought up a very great points, appreciate it for the post.
Greetings! Very helpful advice on this article! It is the little changes that make the biggest changes. Thanks a lot for sharing!
Precisely what I was looking for, appreciate it for posting.
You have brought up a very great details , regards for the post.
Thank you a bunch for sharing this with all people you really recognize what you’re talking approximately! Bookmarked. Kindly additionally seek advice from my web site =). We can have a link change contract among us!
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You definitely know what youre talking about, why throw away your intelligence on just posting videos to your site when you could be giving us something enlightening to read?
It’s hard to find knowledgeable people on this topic, but you sound like you know what you’re talking about! Thanks
Good day! I simply wish to give an enormous thumbs up for the great information you have right here on this post. I can be coming again to your weblog for more soon.
I’ve been browsing on-line greater than three hours nowadays, yet I never discovered any attention-grabbing article like yours. It’s pretty price sufficient for me. In my view, if all web owners and bloggers made good content as you probably did, the net will be much more helpful than ever before.
Howdy would you mind stating which blog platform you’re using? I’m planning to start my own blog soon but I’m having a hard time selecting between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something unique. P.S My apologies for getting off-topic but I had to ask!
It is appropriate time to make some plans for the future and it’s time to be happy. I’ve read this post and if I could I want to suggest you some interesting things or tips. Maybe you could write next articles referring to this article. I wish to read more things about it!
Very interesting information!Perfect just what I was searching for!
Absolutely pent written content, Really enjoyed reading.
Howdy just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading properly. I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same outcome.
Very good written story. It will be helpful to everyone who employess it, including yours truly :). Keep doing what you are doing – looking forward to more posts.
Woh I love your posts, saved to favorites! .
Howdy very nice website!! Guy .. Beautiful .. Amazing .. I will bookmark your website and take the feeds additionally…I am glad to find a lot of helpful information here in the publish, we need work out more techniques on this regard, thanks for sharing. . . . . .
Keep working ,splendid job!
This deep dive into data pipelines is fascinating. Logstash highlights how crucial the transformation layer is-it’s not enough just to collect data; it must be enriched and structured. This principle of seamless, multi-stage flow is key in any high-volume system, whether it’s processing logs or ensuring a smooth user experience, like accessing a dedicated platform via a jl11 app download. Excellent overview!
An attention-grabbing dialogue is value comment. I feel that you must write extra on this subject, it might not be a taboo subject but generally individuals are not enough to speak on such topics. To the next. Cheers
Pretty! This was a really wonderful post. Thank you for your provided information.
Would you be involved in exchanging hyperlinks?
It’s appropriate time to make some plans for the future and it is time to be happy. I’ve learn this publish and if I may I desire to suggest you few attention-grabbing issues or suggestions. Perhaps you could write subsequent articles regarding this article. I desire to learn more things approximately it!
Wow! Thank you! I permanently needed to write on my website something like that. Can I take a fragment of your post to my site?
You are my breathing in, I possess few web logs and sometimes run out from post :). “Fiat justitia et pereat mundus.Let justice be done, though the world perish.” by Ferdinand I.
Hello there! Do you use Twitter? I’d like to follow you if that would be okay. I’m absolutely enjoying your blog and look forward to new updates.
Wow that was odd. I just wrote an extremely long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say superb blog!
Aavant produces the best photography, event and theatre backdrops in the world and works for almost all the biggest players in the world. Being in backdrops industry for last two decades it is the largest player in the world, providing highest quality backdrops to every buyer from USA to Australia.
Aavant produces the best photography, event and theatre backdrops in the world and works for almost all the biggest players in the world. Being in backdrops industry for last two decades it is the largest player in the world, providing highest quality backdrops to every buyer from USA to Australia.
Aavant produces the best photography, event and theatre backdrops in the world and works for almost all the biggest players in the world. Being in backdrops industry for last two decades it is the largest player in the world, providing highest quality backdrops to every buyer from USA to Australia.
I simply couldn’t depart your website prior to suggesting that I really loved the usual information a person provide for your visitors? Is gonna be back ceaselessly in order to inspect new posts.
I really like your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you? Plz answer back as I’m looking to create my own blog and would like to find out where u got this from. thanks
A lot of of the things you state is supprisingly appropriate and it makes me wonder why I hadn’t looked at this in this light previously. This piece really did turn the light on for me personally as far as this issue goes. Nonetheless at this time there is actually one point I am not too comfy with and whilst I attempt to reconcile that with the core idea of the point, permit me observe exactly what the rest of your subscribers have to say.Very well done.
Hmm it appears like your blog ate my first comment (it was super long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog writer but I’m still new to the whole thing. Do you have any recommendations for beginner blog writers? I’d genuinely appreciate it.
I have recently started a web site, the info you offer on this website has helped me greatly. Thank you for all of your time & work.
Please let me know if you’re looking for a writer for your weblog. You have some really good posts and I feel I would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some content for your blog in exchange for a link back to mine. Please blast me an e-mail if interested. Thanks!
whoah this weblog is fantastic i really like reading your articles. Keep up the good paintings! You realize, many individuals are searching around for this information, you can help them greatly.
I was looking through some of your posts on this website and I think this internet site is really informative! Retain putting up.
Hey I am so thrilled I found your weblog, I really found you by accident, while I was looking on Aol for something else, Anyways I am here now and would just like to say thanks for a fantastic post and a all round exciting blog (I also love the theme/design), I don’t have time to read through it all at the minute but I have saved it and also added in your RSS feeds, so when I have time I will be back to read more, Please do keep up the fantastic job.
Great wordpress blog here.. It’s hard to find quality writing like yours these days. I really appreciate people like you! take care
Thanks for another informative site. Where else could I get that type of info written in such an ideal way? I have a project that I’m just now working on, and I’ve been on the look out for such information.
I’ll immediately take hold of your rss as I can’t to find your email subscription link or newsletter service. Do you have any? Kindly let me understand so that I may subscribe. Thanks.
My coder is trying to convince me to move to .net from PHP. I have always disliked the idea because of the costs. But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about a year and am worried about switching to another platform. I have heard great things about blogengine.net. Is there a way I can import all my wordpress content into it? Any kind of help would be really appreciated!
Would love to perpetually get updated outstanding site! .
Nice post. I used to be checking constantly this weblog and I’m inspired! Extremely helpful information particularly the remaining part 🙂 I take care of such info a lot. I used to be looking for this certain information for a very lengthy time. Thank you and best of luck.
Whoa! This blog looks just like my old one! It’s on a entirely different subject but it has pretty much the same layout and design. Superb choice of colors!
Hey! Someone in my Myspace group shared this site with us so I came to take a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers! Exceptional blog and outstanding design and style.
Nice post. I learn something more challenging on different blogs everyday. It will always be stimulating to read content from other writers and practice a little something from their store. I’d prefer to use some with the content on my blog whether you don’t mind. Natually I’ll give you a link on your web blog. Thanks for sharing.
Nearly all of whatever you assert happens to be astonishingly accurate and that makes me ponder why I had not looked at this in this light before. This article really did turn the light on for me as far as this particular issue goes. Nonetheless there is one particular issue I am not really too cozy with and while I try to reconcile that with the core idea of the position, permit me see exactly what all the rest of the subscribers have to say.Well done.
Have you ever considered about adding a little bit more than just your articles? I mean, what you say is fundamental and everything. However think of if you added some great graphics or video clips to give your posts more, “pop”! Your content is excellent but with pics and video clips, this website could definitely be one of the best in its niche. Excellent blog!
It’s a shame you don’t have a donate button! I’d definitely donate to this outstanding blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account. I look forward to new updates and will share this blog with my Facebook group. Chat soon!
TURMERIC TRICK RECIPE
I was wondering if you ever thought of changing the structure of your blog? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or two images. Maybe you could space it out better?
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
TURMERIC TRICK FOR MEN
Very interesting info !Perfect just what I was looking for!
It is really a nice and useful piece of info. I’m satisfied that you simply shared this useful information with us. Please keep us up to date like this. Thank you for sharing.
I’m so happy to read this. This is the kind of manual that needs to be given and not the random misinformation that’s at the other blogs. Appreciate your sharing this best doc.
Hmm is anyone else experiencing problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
Thanks for this fantastic post, I am glad I found this site on yahoo.
I believe this internet site has some real wonderful information for everyone :D. “Do not go where the path may lead, go instead where there is no path and leave a trail.” by Ralph Waldo Emerson.
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! However, how can we communicate?
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You obviously know what youre talking about, why waste your intelligence on just posting videos to your site when you could be giving us something informative to read?
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
What’s Going down i am new to this, I stumbled upon this I’ve discovered It positively helpful and it has aided me out loads. I’m hoping to contribute & aid different users like its aided me. Good job.
Hi, Neat post. There is a problem with your site in internet explorer, would test this… IE still is the market leader and a good portion of people will miss your great writing because of this problem.
Very interesting info!Perfect just what I was searching for!
Very interesting points you have mentioned, regards for putting up.
hello there and thank you in your information – I have certainly picked up something new from proper here. I did alternatively expertise several technical points the usage of this web site, since I skilled to reload the website many instances prior to I could get it to load correctly. I have been pondering if your web host is OK? Not that I am complaining, however slow loading instances instances will often have an effect on your placement in google and can injury your quality rating if advertising and ***********|advertising|advertising|advertising and *********** with Adwords. Well I am including this RSS to my e-mail and can glance out for much extra of your respective intriguing content. Ensure that you replace this once more very soon..
Hydrogen Peroxide Trick
Hydrogen Peroxide Trick
I like the helpful information you provide in your articles. I’ll bookmark your weblog and check again here frequently. I am quite sure I’ll learn a lot of new stuff right here! Best of luck for the next!
I gotta favorite this internet site it seems invaluable invaluable
Horse Gelatin for men
Horse Gelatin Trick Recipe for Men
You can certainly see your expertise in the work you write. The sector hopes for even more passionate writers such as you who are not afraid to say how they believe. At all times follow your heart.
I like this post, enjoyed this one regards for posting.
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
Thank you for sharing excellent informations. Your web site is very cool. I’m impressed by the details that you’ve on this website. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for extra articles. You, my pal, ROCK! I found simply the information I already searched everywhere and simply could not come across. What an ideal site.
I have learn several excellent stuff here. Definitely value bookmarking for revisiting. I wonder how much effort you put to create this sort of magnificent informative site.
Thank you so much for giving everyone such a superb opportunity to read critical reviews from here. It is often very fantastic and packed with a great time for me personally and my office friends to visit the blog at the least thrice in one week to read the new tips you will have. And definitely, I am usually astounded with all the beautiful tips served by you. Certain 2 facts in this post are unquestionably the simplest I’ve ever had.
I am always thought about this, thanks for putting up.
Thanx for the effort, keep up the good work Great work, I am going to start a small Blog Engine course work using your site I hope you enjoy blogging with the popular BlogEngine.net.Thethoughts you express are really awesome. Hope you will right some more posts.
I have recently started a web site, the information you offer on this website has helped me greatly. Thanks for all of your time & work.
We are a group of volunteers and opening a new scheme in our community. Your web site offered us with valuable info to work on. You have done an impressive job and our whole community will be thankful to you.
Wohh precisely what I was searching for, thankyou for posting.
Unquestionably believe that which you said. Your favourite reason seemed to be at the web the simplest thing to consider of. I say to you, I definitely get irked while other people think about concerns that they just do not realize about. You controlled to hit the nail upon the top and also outlined out the entire thing without having side effect , other folks could take a signal. Will probably be back to get more. Thanks
This website is mostly a walk-by way of for all of the information you wished about this and didn’t know who to ask. Glimpse right here, and also you’ll definitely discover it.
I’ll immediately grab your rss as I can’t find your e-mail subscription link or e-newsletter service. Do you’ve any? Please let me know so that I may just subscribe. Thanks.
What i don’t understood is in truth how you are no longer really a lot more well-liked than you may be right now. You are so intelligent. You understand thus significantly on the subject of this subject, produced me individually believe it from a lot of varied angles. Its like men and women don’t seem to be interested except it’s something to accomplish with Girl gaga! Your individual stuffs great. All the time deal with it up!
Hey, you used to write fantastic, but the last several posts have been kinda boring?K I miss your great writings. Past few posts are just a little out of track! come on!
Lovely just what I was looking for.Thanks to the author for taking his time on this one.
Hello, Neat post. There’s an issue along with your website in web explorer, might check thisK IE still is the market chief and a good component of other people will miss your great writing because of this problem.
I really prize your piece of work, Great post.
hey there and thank you for your information – I’ve certainly picked up something new from right here. I did however expertise some technical points using this web site, since I experienced to reload the web site lots of times previous to I could get it to load correctly. I had been wondering if your web host is OK? Not that I am complaining, but sluggish loading instances times will often affect your placement in google and could damage your quality score if advertising and marketing with Adwords. Anyway I’m adding this RSS to my e-mail and can look out for a lot more of your respective fascinating content. Ensure that you update this again soon..
This is the best blog for anyone who needs to seek out out about this topic. You notice a lot its virtually laborious to argue with you (not that I really would want…HaHa). You definitely put a brand new spin on a subject thats been written about for years. Great stuff, simply great!
jellyfil
jellyfil reviews
slimtide reviews and complaints
slim tide reviews
There are some fascinating closing dates on this article but I don’t know if I see all of them middle to heart. There is some validity however I’ll take maintain opinion till I look into it further. Good article , thanks and we would like more! Added to FeedBurner as properly
Yay google is my king assisted me to find this outstanding internet site! .
Normally I do not read article on blogs, but I wish to say that this write-up very forced me to try and do it! Your writing style has been surprised me. Thanks, very nice article.
Yay google is my world beater helped me to find this outstanding internet site! .
Trick
Thanks , I’ve recently been searching for information about this topic for a while and yours is the greatest I’ve discovered so far. However, what concerning the conclusion? Are you sure concerning the supply?
This is really interesting, You’re a very skilled blogger. I have joined your feed and look forward to seeking more of your wonderful post. Also, I have shared your web site in my social networks!
I am glad to be one of several visitors on this great internet site (:, thankyou for posting.
Thank you for sharing superb informations. Your web site is very cool. I am impressed by the details that you have on this website. It reveals how nicely you perceive this subject. Bookmarked this web page, will come back for extra articles. You, my pal, ROCK! I found just the info I already searched all over the place and just could not come across. What a great site.
Definitely consider that which you stated. Your favorite reason appeared to be on the web the simplest thing to understand of. I say to you, I certainly get annoyed while other people consider concerns that they just don’t recognise about. You managed to hit the nail upon the top as smartly as outlined out the entire thing with no need side effect , folks can take a signal. Will probably be again to get more. Thank you
Real excellent visual appeal on this website , I’d value it 10 10.
horse gelatin
I am constantly invstigating online for articles that can assist me. Thx!
Hey, you used to write excellent, but the last few posts have been kinda boringK I miss your great writings. Past few posts are just a little bit out of track! come on!
Enjoyed reading this, very good stuff, thankyou.
Your home is valueble for me. Thanks!…
This site is really a walk-via for all of the info you wished about this and didn’t know who to ask. Glimpse here, and you’ll positively uncover it.
I got good info from your blog
Greetings! Quick question that’s totally off topic. Do you know how to make your site mobile friendly? My website looks weird when viewing from my iphone. I’m trying to find a template or plugin that might be able to resolve this problem. If you have any recommendations, please share. Cheers!
I have been surfing on-line more than three hours today, but I never discovered any fascinating article like yours. It’s beautiful price enough for me. In my opinion, if all site owners and bloggers made good content material as you did, the web might be a lot more useful than ever before.
I’m impressed, I have to say. Actually hardly ever do I encounter a weblog that’s each educative and entertaining, and let me let you know, you’ve gotten hit the nail on the head. Your idea is excellent; the issue is one thing that not sufficient people are speaking intelligently about. I’m very blissful that I stumbled across this in my seek for something regarding this.
Hello, Neat post. There’s an issue together with your site in internet explorer, would check thisK IE nonetheless is the market chief and a big part of people will leave out your excellent writing because of this problem.
Would love to constantly get updated outstanding web site! .
With havin so much written content do you ever run into any problems of plagorism or copyright infringement? My website has a lot of unique content I’ve either created myself or outsourced but it looks like a lot of it is popping it up all over the internet without my authorization. Do you know any solutions to help prevent content from being stolen? I’d definitely appreciate it.
I love the efforts you have put in this, thank you for all the great content.
Great post. I am facing a couple of these problems.
I like this post, enjoyed this one thanks for posting. “Fear not for the future, weep not for the past.” by Percy Bysshe Shelley.
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
Very interesting subject , regards for putting up.
I’ll right away snatch your rss as I can not find your email subscription link or e-newsletter service. Do you have any? Kindly let me know in order that I may subscribe. Thanks.
I have been surfing on-line greater than three hours these days, yet I by no means found any attention-grabbing article like yours. It’s lovely price enough for me. In my view, if all webmasters and bloggers made excellent content as you probably did, the net will probably be a lot more useful than ever before.
I am incessantly thought about this, thankyou for posting.
HORSE GELATIN
HORSE GELATIN
We are a gaggle of volunteers and opening a brand new scheme in our community. Your web site provided us with helpful information to paintings on. You have done a formidable job and our whole group will likely be grateful to you.
Incredible! This blog looks exactly like my old one! It’s on a completely different subject but it has pretty much the same page layout and design. Wonderful choice of colors!
Pretty! This was a really wonderful post. Thank you for your provided information.
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
This is a very good tips especially to those new to blogosphere, brief and accurate information… Thanks for sharing this one. A must read article.
Totally digging the deep dive! Understanding the odds is key, but the feel of the live action matters more. Check out 1334 app ক্যাসিনো for that real vibe!
Great blog! I am loving it!! Will be back later to read some more. I am bookmarking your feeds also.
We are a group of volunteers and starting a new scheme in our community. Your website offered us with valuable information to work on. You’ve done a formidable job and our whole community will be grateful to you.
JELLYFIL REVIEWS
Excellent post. I was checking constantly this blog and I’m impressed! Extremely helpful info particularly the last part 🙂 I care for such information much. I was seeking this certain information for a long time. Thank you and best of luck.
Of course, what a splendid website and illuminating posts, I surely will bookmark your site.Best Regards!
I have recently started a website, the info you provide on this web site has helped me tremendously. Thank you for all of your time & work. “One of the greatest pains to human nature is the pain of a new idea.” by Walter Bagehot.
Just wanna state that this is very helpful, Thanks for taking your time to write this.
Great post, I conceive website owners should larn a lot from this web site its really user genial.
I’ve recently started a blog, the information you provide on this web site has helped me greatly. Thank you for all of your time & work.
Very interesting topic, appreciate it for putting up.
of course like your web-site however you have to take a look at the spelling on quite a few of your posts. Many of them are rife with spelling problems and I in finding it very bothersome to tell the reality on the other hand I’ll definitely come back again.
Well I definitely enjoyed studying it. This subject provided by you is very constructive for good planning.
I genuinely enjoy looking through on this site, it has got superb blog posts. “Do what you fear, and the death of fear is certain.” by Anthony Robbins.
I have recently started a web site, the info you provide on this site has helped me tremendously. Thanks for all of your time & work.
horse gelatin for men
I really like your writing style, good information, thanks for putting up :D.
horse gelatin trick for men
Wow! This could be one particular of the most beneficial blogs We’ve ever arrive across on this subject. Actually Excellent. I’m also an expert in this topic therefore I can understand your effort.
I would like to thank you for the efforts you have put in writing this web site. I am hoping the same high-grade blog post from you in the upcoming also. In fact your creative writing skills has encouraged me to get my own web site now. Actually the blogging is spreading its wings fast. Your write up is a great example of it.
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
I truly wanted to compose a brief note to be able to express gratitude to you for these pleasant concepts you are showing on this site. My incredibly long internet search has at the end of the day been paid with wonderful details to go over with my neighbours. I would admit that we visitors actually are truly lucky to dwell in a magnificent place with many outstanding professionals with helpful hints. I feel somewhat blessed to have come across the webpage and look forward to plenty of more brilliant times reading here. Thanks a lot once more for all the details.
hey there and thanks in your info – I have certainly picked up something new from right here. I did on the other hand expertise several technical issues the usage of this web site, as I experienced to reload the web site lots of instances prior to I could get it to load properly. I had been thinking about if your hosting is OK? Not that I am complaining, but slow loading circumstances instances will very frequently affect your placement in google and can injury your high-quality rating if ads and ***********|advertising|advertising|advertising and *********** with Adwords. Well I’m adding this RSS to my email and could glance out for a lot more of your respective fascinating content. Make sure you update this again very soon..
I was curious if you ever considered changing the page layout of your blog? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or two images. Maybe you could space it out better?
Great goods from you, man. I have understand your stuff previous to and you are just extremely fantastic. I actually like what you have acquired here, really like what you’re saying and the way in which you say it. You make it entertaining and you still take care of to keep it sensible. I can not wait to read far more from you. This is really a terrific website.
Your style is so unique compared to many other people. Thank you for publishing when you have the opportunity,Guess I will just make this bookmarked.
I’ll right away grab your rss as I can’t find your email subscription link or newsletter service. Do you have any? Kindly let me know in order that I could subscribe. Thanks.
It’s a pity you don’t have a donate button! I’d certainly donate to this outstanding blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account. I look forward to fresh updates and will talk about this site with my Facebook group. Chat soon!
Thanks for the auspicious writeup. It in truth was a leisure account it. Glance advanced to far added agreeable from you! By the way, how could we keep up a correspondence?
WONDERFUL Post.thanks for share..extra wait .. …
Very interesting subject, thankyou for posting. “Challenge is a dragon with a gift in its mouthTame the dragon and the gift is yours.” by Noela Evans.
Great goods from you, man. I’ve understand your stuff previous to and you are just too magnificent. I really like what you have acquired here, certainly like what you are saying and the way in which you say it. You make it enjoyable and you still take care of to keep it sensible. I can’t wait to read far more from you. This is really a great web site.
Thankyou for helping out, good info .
Good info. Lucky me I reach on your website by accident, I bookmarked it.
I just couldn’t depart your web site prior to suggesting that I actually enjoyed the standard information a person provide for your visitors? Is going to be back often in order to check up on new posts
After study a few of the blog posts on your website now, and I truly like your way of blogging. I bookmarked it to my bookmark website list and will be checking back soon. Pls check out my web site as well and let me know what you think.
I envy your work, regards for all the interesting articles.
Hi there, I discovered your web site by the use of Google whilst looking for a comparable matter, your website came up, it looks great. I’ve bookmarked it in my google bookmarks.
It’s really a nice and helpful piece of info. I’m glad that you just shared this useful information with us. Please stay us informed like this. Thanks for sharing.
I’ve recently started a web site, the information you offer on this site has helped me greatly. Thanks for all of your time & work.
superb post.Ne’er knew this, thankyou for letting me know.
I like this site very much, Its a really nice billet to read and get information. “Words are like leaves and where they most abound, Much fruit of sense beneath is rarely found.” by Alexander Pope.
This really answered my problem, thank you!
I appreciate, cause I found just what I was looking for. You’ve ended my 4 day long hunt! God Bless you man. Have a nice day. Bye
Very good website you have here but I was wanting to know if you knew of any community forums that cover the same topics talked about in this article? I’d really like to be a part of community where I can get opinions from other knowledgeable people that share the same interest. If you have any suggestions, please let me know. Many thanks!
I enjoy your piece of work, appreciate it for all the informative content.
I do believe all the ideas you’ve offered to your post. They are very convincing and can definitely work. Nonetheless, the posts are too brief for beginners. May just you please prolong them a little from subsequent time? Thanks for the post.
Outstanding post, you have pointed out some superb points, I as well believe this s a very wonderful website.
You made some nice points there. I did a search on the subject matter and found most guys will agree with your blog.
You have observed very interesting points! ps decent website . “By their own follies they perished, the fools.” by Homer.
I intended to post you that bit of note in order to give many thanks once again just for the marvelous views you’ve contributed in this article. It’s certainly seriously open-handed with people like you giving publicly what exactly many people might have advertised as an e book in making some cash on their own, certainly since you could have tried it in the event you decided. These ideas as well worked to become a great way to be aware that other individuals have the identical eagerness the same as mine to grasp many more around this matter. I am certain there are millions of more fun situations up front for those who browse through your site.
Wonderful paintings! That is the type of info that should be shared around the internet. Disgrace on Google for not positioning this publish higher! Come on over and seek advice from my website . Thank you =)
I’m really impressed with your writing skills and also with the layout on your blog. Is this a paid theme or did you customize it yourself? Anyway keep up the nice quality writing, it is rare to see a great blog like this one nowadays..
I dugg some of you post as I cogitated they were handy very beneficial
There is noticeably a bundle to know about this. I assume you made certain nice points in features also.
F*ckin’ amazing things here. I am very glad to see your article. Thanks a lot and i’m looking forward to contact you. Will you kindly drop me a e-mail?
Some truly superb blog posts on this web site, thankyou for contribution.
Hmm, I was skeptical about another platform, but the user journey focus mentioned is smart. It seems less overwhelming than some others. Check out phplay88; it looks quite structured for newcomers like me!
I conceive other website owners should take this web site as an example , very clean and wonderful user pleasant design and style.
Hi there, I found your site by means of Google while searching for a comparable topic, your website came up, it seems to be great. I’ve bookmarked it in my google bookmarks.
The other day, while I was at work, my cousin stole my iPad and tested to see if it can survive a 40 foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is entirely off topic but I had to share it with someone!
Excellent beat ! I would like to apprentice at the same time as you amend your web site, how can i subscribe for a blog web site? The account helped me a acceptable deal. I had been tiny bit familiar of this your broadcast provided shiny transparent idea
You should take part in a contest for one of the best blogs on the web. I will recommend this site!
JELLYFIL
Jellyfil Supplement Review
Some really nice stuff on this internet site, I like it.
The next time I read a blog, I hope that it doesnt disappoint me as much as this one. I mean, I know it was my choice to read, but I truly thought youd have something attention-grabbing to say. All I hear is a bunch of whining about something that you could possibly repair in case you werent too busy searching for attention.
JELLYFIL
Have you ever thought about writing an e-book or guest authoring on other websites? I have a blog based upon on the same topics you discuss and would really like to have you share some stories/information. I know my visitors would enjoy your work. If you’re even remotely interested, feel free to send me an e-mail.
Wow, marvelous blog layout! How long have you been blogging for? you make blogging look easy. The overall look of your web site is magnificent, let alone the content!
JELLYFIL
Hey are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you require any coding knowledge to make your own blog? Any help would be greatly appreciated!
I like this post, enjoyed this one appreciate it for posting. “I would sooner fail than not be among the greatest.” by John Keats.
Real good info can be found on web blog. “Never violate the sacredness of your individual self-respect.” by Theodore Parker.
Some really excellent blog posts on this site, thank you for contribution. “I finally know what distinguishes man from other beasts financial worries. – Journals” by Jules Renard.
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! By the way, how could we communicate?
Woah! I’m really enjoying the template/theme of this site. It’s simple, yet effective. A lot of times it’s challenging to get that “perfect balance” between user friendliness and appearance. I must say you have done a fantastic job with this. Also, the blog loads super fast for me on Firefox. Outstanding Blog!
Usually I do not read article on blogs, but I wish to say that this write-up very forced me to try and do so! Your writing style has been surprised me. Thanks, quite nice post.
JELLYFIL
JELLYFIL
I am glad to be a visitor of this complete web blog! , appreciate it for this rare information! .
You can definitely see your expertise within the paintings you write. The arena hopes for more passionate writers such as you who aren’t afraid to mention how they believe. Always go after your heart. “What power has law where only money rules.” by Gaius Petronius.
I’m not sure where you are getting your information, but great topic. I needs to spend some time learning more or understanding more. Thanks for wonderful information I was looking for this information for my mission.
I truly enjoy looking through on this site, it has excellent posts.
I absolutely love your blog and find nearly all of your post’s to be just what I’m looking for. can you offer guest writers to write content in your case? I wouldn’t mind composing a post or elaborating on a lot of the subjects you write in relation to here. Again, awesome web log!
Howdy! I simply would like to give an enormous thumbs up for the nice information you’ve here on this post. I can be coming back to your weblog for more soon.
You can definitely see your expertise in the paintings you write. The world hopes for more passionate writers such as you who are not afraid to say how they believe. At all times follow your heart. “The point of quotations is that one can use another’s words to be insulting.” by Amanda Cross.
Your place is valueble for me. Thanks!…
Excellent post. I was checking constantly this weblog and I am inspired! Very helpful info particularly the ultimate part 🙂 I deal with such info much. I used to be looking for this particular information for a long time. Thanks and best of luck.
Thank you for every other wonderful post. Where else could anybody get that kind of information in such a perfect way of writing? I have a presentation subsequent week, and I am at the look for such information.
You can definitely see your enthusiasm in the work you write. The world hopes for more passionate writers like you who are not afraid to say how they believe. Always go after your heart.
This really answered my problem, thank you!
Thanks a bunch for sharing this with all of us you really know what you are talking about! Bookmarked. Kindly also visit my web site =). We could have a link exchange arrangement between us!
Amazing blog! Do you have any suggestions for aspiring writers? I’m planning to start my own site soon but I’m a little lost on everything. Would you advise starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally confused .. Any recommendations? Thanks a lot!
F*ckin’ tremendous things here. I’m very satisfied to peer your post. Thanks a lot and i’m looking ahead to touch you. Will you kindly drop me a e-mail?
I reckon something really special in this internet site.
The next time I read a blog, I hope that it doesnt disappoint me as much as this one. I mean, I know it was my choice to read, but I actually thought youd have something interesting to say. All I hear is a bunch of whining about something that you could fix if you werent too busy looking for attention.
Wonderful work! This is the type of info that should be shared around the net. Shame on Google for not positioning this post higher! Come on over and visit my site . Thanks =)
I like this blog very much, Its a very nice post to read and receive info . “Anger is a signal, and one worth listening to.” by Harriet Lerner.
Howdy, i read your blog from time to time and i own a similar one and i was just curious if you get a lot of spam comments? If so how do you reduce it, any plugin or anything you can recommend? I get so much lately it’s driving me mad so any support is very much appreciated.
Great article and right to the point. I am not sure if this is in fact the best place to ask but do you guys have any thoughts on where to get some professional writers? Thanks in advance 🙂
Great post. I am facing a couple of these problems.
You made some first rate points there. I regarded on the web for the problem and found most people will associate with along with your website.
Some genuinely fantastic content on this web site, regards for contribution.
Hi there, I found your website by means of Google at the same time as searching for a related matter, your site came up, it appears good. I have bookmarked it in my google bookmarks.
hi!,I like your writing so so much! percentage we be in contact extra approximately your post on AOL? I need a specialist in this area to solve my problem. Maybe that is you! Having a look forward to see you.
I used to be more than happy to find this net-site.I wanted to thanks to your time for this excellent learn!! I positively enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
I was just searching for this information for a while. After 6 hours of continuous Googleing, finally I got it in your website. I wonder what’s the lack of Google strategy that do not rank this type of informative websites in top of the list. Generally the top sites are full of garbage.
Very interesting subject, thanks for posting. “Men who never get carried away should be.” by Malcolm Forbes.
Thankyou for this post, I am a big big fan of this web site would like to continue updated.
I was recommended this blog by my cousin. I’m not sure whether this post is written by him as no one else know such detailed about my difficulty. You’re amazing! Thanks!
Awsome website! I am loving it!! Will come back again. I am taking your feeds also.
HORSE GELATIN
HORSE GELATIN TRICK
Superb post but I was wanting to know if you could write a litte more on this topic? I’d be very thankful if you could elaborate a little bit further. Cheers!
It is appropriate time to make some plans for the future and it’s time to be happy. I have read this post and if I could I desire to suggest you few interesting things or advice. Maybe you could write next articles referring to this article. I want to read even more things about it!
Electronic Business Card – The Smart Card. Create and share your professional electronic business card easily. In minutes. Choose from 100+ templates, connect with clients, and grow your business today!
Yeah bookmaking this wasn’t a speculative determination outstanding post! .
Hi, Neat post. There is a problem with your website in internet explorer, would test this… IE still is the market leader and a good portion of people will miss your wonderful writing due to this problem.
very good put up, i definitely love this website, keep on it
naturally like your web-site but you have to check the spelling on quite a few of your posts. A number of them are rife with spelling issues and I find it very bothersome to tell the truth nevertheless I’ll certainly come back again.
You really make it appear really easy along with your presentation however I find this matter to be really something that I think I would by no means understand. It kind of feels too complicated and very vast for me. I am taking a look forward for your next submit, I’ll attempt to get the dangle of it!
you’re in point of fact a good webmaster. The site loading velocity is incredible. It kind of feels that you are doing any distinctive trick. Furthermore, The contents are masterpiece. you’ve done a great task in this subject!
Hey! I just wanted to ask if you ever have any trouble with hackers? My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no backup. Do you have any methods to stop hackers?
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
Great post, I believe blog owners should larn a lot from this web site its really user pleasant.
I have learn several excellent stuff here. Definitely price bookmarking for revisiting. I surprise how so much attempt you put to make such a excellent informative web site.
Wow that was strange. I just wrote an very long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyway, just wanted to say wonderful blog!
It’s hard to find knowledgeable people on this topic, but you sound like you know what you’re talking about! Thanks
Very interesting information!Perfect just what I was looking for! “Charity is injurious unless it helps the recipient to become independent of it.” by John Davidson Rockefeller, Sr..
I regard something really special in this web site.
I love your blog.. very nice colors & theme. Did you create this website yourself? Plz reply back as I’m looking to create my own blog and would like to know wheere u got this from. thanks
You really make it seem really easy along with your presentation but I to find this topic to be actually one thing that I believe I might by no means understand. It seems too complicated and very broad for me. I’m looking forward to your next post, I’ll try to get the hang of it!
I used to be very pleased to find this net-site.I needed to thanks on your time for this glorious read!! I positively having fun with every little bit of it and I have you bookmarked to take a look at new stuff you weblog post.
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post…
WONDERFUL Post.thanks for share..extra wait .. …
Hi my family member! I wish to say that this article is awesome, great written and come with almost all vital infos. I’d like to peer more posts like this.
Some times its a pain in the ass to read what blog owners wrote but this internet site is real user friendly! .
I got what you intend, regards for putting up.Woh I am happy to find this website through google.
Hi my loved one! I want to say that this article is amazing, nice written and come with almost all significant infos. I’d like to peer extra posts like this.
Wonderful site. Lots of helpful information here. I’m sending it to a few friends ans also sharing in delicious. And certainly, thanks to your sweat!
Thanks for the sensible critique. Me & my neighbor were just preparing to do some research on this. We got a grab a book from our area library but I think I learned more from this post. I am very glad to see such wonderful info being shared freely out there.
Hi there very cool blog!! Man .. Beautiful .. Amazing .. I’ll bookmark your website and take the feeds additionally…I am glad to find numerous useful information here within the publish, we want work out more strategies in this regard, thanks for sharing. . . . . .
I’m curious to find out what blog platform you are utilizing? I’m having some small security issues with my latest blog and I would like to find something more safe. Do you have any recommendations?
whoah this weblog is excellent i like studying your articles. Keep up the great work! You know, lots of people are hunting round for this information, you could help them greatly.
hey there and thanks in your information – I’ve certainly picked up anything new from right here. I did alternatively expertise a few technical issues the usage of this website, since I experienced to reload the web site many instances prior to I may get it to load correctly. I had been puzzling over if your web host is OK? Not that I’m complaining, however sluggish loading cases instances will sometimes have an effect on your placement in google and could harm your high-quality score if advertising and ***********|advertising|advertising|advertising and *********** with Adwords. Anyway I’m adding this RSS to my email and can look out for a lot extra of your respective exciting content. Ensure that you update this once more very soon..
You have brought up a very fantastic points, regards for the post.
ice water hack to lose weight
Ice Water Hack
I truly appreciate this post. I have been looking all over for this! Thank goodness I found it on Bing. You have made my day! Thanks again!
Thank you for the good writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! However, how could we communicate?
We stumbled over here different page and thought I should check things out. I like what I see so now i’m following you. Look forward to finding out about your web page repeatedly.
Pretty! This was a really wonderful post. Thank you for your provided information.
Hmm is anyone else having problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated.
Attractive section of content. I just stumbled upon your website and in accession capital to assert that I get actually enjoyed account your blog posts. Any way I will be subscribing to your augment and even I achievement you access consistently rapidly.
Hi there would you mind sharing which blog platform you’re using? I’m going to start my own blog in the near future but I’m having a hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something unique. P.S Sorry for getting off-topic but I had to ask!
you’re really a good webmaster. The website loading speed is incredible. It seems that you are doing any unique trick. Moreover, The contents are masterwork. you’ve done a great job on this topic!
I respect your work, regards for all the interesting articles.
Have you ever thought about publishing an e-book or guest authoring on other websites? I have a blog based on the same topics you discuss and would really like to have you share some stories/information. I know my readers would appreciate your work. If you’re even remotely interested, feel free to send me an email.
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
As I web site possessor I believe the content matter here is rattling excellent , appreciate it for your hard work. You should keep it up forever! Best of luck.
I’ve learn some excellent stuff here. Certainly worth bookmarking for revisiting. I wonder how so much attempt you put to make the sort of excellent informative site.
Nice post. I be taught something more challenging on different blogs everyday. It is going to at all times be stimulating to learn content material from other writers and practice a little bit something from their store. I’d prefer to make use of some with the content material on my weblog whether or not you don’t mind. Natually I’ll provide you with a hyperlink in your net blog. Thanks for sharing.
Pretty! This was a really wonderful post. Thank you for your provided information.
I would like to thnkx for the efforts you have put in writing this blog. I am hoping the same high-grade blog post from you in the upcoming as well. In fact your creative writing abilities has inspired me to get my own blog now. Really the blogging is spreading its wings quickly. Your write up is a good example of it.
I have recently started a blog, the information you offer on this web site has helped me tremendously. Thank you for all of your time & work.
I together with my guys were actually checking out the nice things found on your web site and instantly I had a terrible feeling I had not expressed respect to the web site owner for those secrets. All of the boys are actually excited to read through all of them and have clearly been taking pleasure in them. Appreciation for turning out to be very kind and then for obtaining certain outstanding themes most people are really desirous to know about. Our honest regret for not expressing gratitude to sooner.
Nice read, I just passed this onto a friend who was doing some research on that. And he just bought me lunch since I found it for him smile Thus let me rephrase that: Thanks for lunch! “A human being has a natural desire to have more of a good thing than he needs.” by Mark Twain.
Great write-up, I am normal visitor of one’s web site, maintain up the excellent operate, and It’s going to be a regular visitor for a long time.
Good website! I really love how it is simple on my eyes and the data are well written. I’m wondering how I could be notified when a new post has been made. I have subscribed to your RSS which must do the trick! Have a nice day!
Hello there I am so excited I found your web site, I really found you by mistake, while I was searching on Bing for something else, Nonetheless I am here now and would just like to say thanks for a fantastic post and a all round interesting blog (I also love the theme/design), I don’t have time to read through it all at the moment but I have bookmarked it and also included your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up the awesome work.
You really make it seem really easy along with your presentation but I in finding this matter to be actually something which I feel I’d never understand. It seems too complex and extremely vast for me. I’m looking forward on your next put up, I’ll attempt to get the grasp of it!
I too conceive thus, perfectly pent post! .
Real good visual appeal on this site, I’d rate it 10 10.
This is the best weblog for anybody who desires to search out out about this topic. You understand a lot its almost laborious to argue with you (not that I actually would want…HaHa). You undoubtedly put a new spin on a topic thats been written about for years. Nice stuff, simply nice!
Horse Gelatin Trick
GELATIN HORSE TRICK
Right now it seems like Drupal is the top blogging platform out there right now. (from what I’ve read) Is that what you are using on your blog?
BAKING SODA TRICK RECIPE
Wow! This can be one particular of the most beneficial blogs We’ve ever arrive across on this subject. Actually Great. I’m also an expert in this topic therefore I can understand your effort.
hi!,I like your writing very much! percentage we keep up a correspondence extra about your article on AOL? I require a specialist in this space to resolve my problem. May be that’s you! Looking ahead to peer you.
BAKING SODA TRICK RECIPE
I am not rattling wonderful with English but I come up this very easygoing to translate.
I am thankful that I detected this website, exactly the right information that I was searching for! .
Jellyfil Supplement Reviews
JELLYFIL REVIEWS
I am glad to be a visitor of this unadulterated web blog! , regards for this rare info ! .
Incredible! This blog looks just like my old one! It’s on a totally different subject but it has pretty much the same layout and design. Wonderful choice of colors!
Great, I should certainly pronounce, impressed with your website. I had no trouble navigating through all tabs and related information ended up being truly simple to do to access. I recently found what I hoped for before you know it at all. Reasonably unusual. Is likely to appreciate it for those who add forums or anything, site theme . a tones way for your customer to communicate. Nice task.
After study a few of the blog posts in your web site now, and I really like your way of blogging. I bookmarked it to my bookmark web site list and will be checking again soon. Pls try my website online as nicely and let me know what you think.
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you need any coding expertise to make your own blog? Any help would be really appreciated!
An impressive share, I simply given this onto a colleague who was doing somewhat analysis on this. And he in truth bought me breakfast as a result of I found it for him.. smile. So let me reword that: Thnx for the deal with! However yeah Thnkx for spending the time to discuss this, I feel strongly about it and love studying extra on this topic. If doable, as you turn into expertise, would you thoughts updating your weblog with more particulars? It’s extremely helpful for me. Massive thumb up for this blog publish!
Wow that was unusual. I just wrote an extremely long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyway, just wanted to say superb blog!
You should take part in a contest for one of the best blogs on the web. I will recommend this site!
I relish, result in I found exactly what I was taking a look for. You have ended my 4 day long hunt! God Bless you man. Have a great day. Bye
Does your blog have a contact page? I’m having trouble locating it but, I’d like to shoot you an email. I’ve got some creative ideas for your blog you might be interested in hearing. Either way, great website and I look forward to seeing it develop over time.
What i do not understood is actually how you’re not actually a lot more smartly-preferred than you may be right now. You’re very intelligent. You already know therefore significantly when it comes to this topic, made me in my opinion imagine it from numerous varied angles. Its like men and women aren’t interested except it is something to do with Woman gaga! Your individual stuffs outstanding. Always care for it up!
Interesting blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple adjustements would really make my blog jump out. Please let me know where you got your theme. Many thanks
I reckon something truly interesting about your website so I saved to favorites.
I do not even know how I ended up here, but I thought this post was good. I do not know who you are but certainly you’re going to a famous blogger if you are not already 😉 Cheers!
I conceive this site has very wonderful composed content articles.
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! By the way, how could we communicate?
I’ve been exploring for a little for any high-quality articles or blog posts in this sort of area . Exploring in Yahoo I ultimately stumbled upon this website. Studying this information So i’m happy to exhibit that I have an incredibly good uncanny feeling I discovered exactly what I needed. I such a lot definitely will make sure to do not overlook this site and provides it a glance on a continuing basis.
Hmm is anyone else having problems with the images on this blog loading? I’m trying to find out if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated.
Whats Taking place i’m new to this, I stumbled upon this I have found It absolutely helpful and it has aided me out loads. I am hoping to give a contribution & assist other users like its helped me. Great job.
There are some attention-grabbing closing dates on this article but I don’t know if I see all of them center to heart. There may be some validity however I’ll take maintain opinion until I look into it further. Good article , thanks and we wish more! Added to FeedBurner as properly
I respect your piece of work, regards for all the useful blog posts.
Some truly interesting details you have written.Aided me a lot, just what I was looking for :D.
That is very interesting, You’re an excessively skilled blogger. I’ve joined your rss feed and look ahead to in search of extra of your great post. Also, I’ve shared your web site in my social networks!
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
I loved as much as you will obtain carried out right here. The caricature is tasteful, your authored material stylish. however, you command get bought an edginess over that you wish be delivering the following. ill without a doubt come more previously again as exactly the similar just about a lot continuously inside case you defend this increase.
Oh my goodness! an incredible article dude. Thanks Nonetheless I am experiencing situation with ur rss . Don’t know why Unable to subscribe to it. Is there anyone getting equivalent rss problem? Anyone who is aware of kindly respond. Thnkx
An interesting discussion is worth comment. I think that you should write more on this topic, it might not be a taboo subject but generally people are not enough to speak on such topics. To the next. Cheers
certainly like your web site but you need to check the spelling on quite a few of your posts. Many of them are rife with spelling problems and I find it very troublesome to tell the truth nevertheless I’ll definitely come back again.
The UI flow for transaction management looks robust. Analyzing the payment architecture reveals solid UX principles at play; check out more insights on hi19 slot download. Great design integration!
Very interesting points you have remarked, thanks for putting up.
Jellyfil Supplement Review
Hello! I know this is kind of off topic but I was wondering if you knew where I could locate a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having problems finding one? Thanks a lot!
Woh I love your articles, saved to favorites! .
JELLYFIL
Hi! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this write-up to him. Pretty sure he will have a good read. Many thanks for sharing!
Jellyfil Supplement Review
Superb blog! Do you have any tips and hints for aspiring writers? I’m planning to start my own website soon but I’m a little lost on everything. Would you recommend starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally overwhelmed .. Any ideas? Cheers!
I like this website because so much useful material on here :D.
JELLYFIL
I couldn’t resist commenting
Spot on with this write-up, I truly suppose this website needs far more consideration. I’ll most likely be again to learn way more, thanks for that info.
Everything is very open and very clear explanation of issues. was truly information. Your website is very useful. Thanks for sharing.
After study a couple of of the weblog posts on your website now, and I really like your manner of blogging. I bookmarked it to my bookmark web site checklist and will probably be checking back soon. Pls try my website as effectively and let me know what you think.
I like this blog very much, Its a real nice post to read and get info . “From now on, ending a sentence with a preposition is something up with which I will not put.” by Sir Winston Churchill.
Yeah bookmaking this wasn’t a speculative determination great post! .
Someone essentially help to make critically articles I might state. This is the very first time I frequented your web page and so far? I surprised with the analysis you made to create this actual put up amazing. Excellent job!
It’s actually a nice and useful piece of information. I am glad that you just shared this helpful information with us. Please stay us informed like this. Thank you for sharing.
Awsome post and right to the point. I don’t know if this is actually the best place to ask but do you folks have any ideea where to get some professional writers? Thanks 🙂
JELLYFIL REVIEWS
Jellyfil Supplement Review
Simply wanna remark on few general things, The website pattern is perfect, the subject material is real fantastic : D.
I like this web site so much, saved to bookmarks. “To hold a pen is to be at war.” by Francois Marie Arouet Voltaire.
You made some first rate factors there. I regarded on the web for the problem and located most individuals will go together with with your website.
I just could not leave your web site prior to suggesting that I really loved the usual information a person supply to your guests? Is gonna be again continuously in order to inspect new posts.
Thank you for helping out, superb information. “If you would convince a man that he does wrong, do right. Men will believe what they see.” by Henry David Thoreau.
Thanks for another excellent post. Where else could anybody get that type of information in such an ideal way of writing? I have a presentation next week, and I am on the search for such information.
It is in reality a nice and helpful piece of info. I’m satisfied that you just shared this helpful information with us. Please keep us informed like this. Thanks for sharing.
Real wonderful visual appeal on this internet site, I’d value it 10 10.
Woah! I’m really enjoying the template/theme of this site. It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between usability and appearance. I must say that you’ve done a amazing job with this. Also, the blog loads extremely fast for me on Opera. Exceptional Blog!
I simply couldn’t go away your web site before suggesting that I really loved the usual info an individual supply to your guests? Is going to be back frequently in order to check up on new posts.
I enjoy your writing style truly enjoying this web site.
With havin so much content and articles do you ever run into any problems of plagorism or copyright infringement? My site has a lot of exclusive content I’ve either authored myself or outsourced but it seems a lot of it is popping it up all over the web without my authorization. Do you know any ways to help reduce content from being ripped off? I’d definitely appreciate it.
We are a group of volunteers and starting a new scheme in our community. Your web site offered us with valuable information to work on. You have done a formidable job and our whole community will be grateful to you.
Wonderful goods from you, man. I have be mindful your stuff previous to and you’re simply too excellent. I really like what you have received right here, really like what you are stating and the way wherein you assert it. You are making it entertaining and you continue to care for to keep it wise. I can’t wait to read much more from you. This is really a great site.
You must take part in a contest for top-of-the-line blogs on the web. I’ll suggest this website!
It’s arduous to seek out knowledgeable folks on this subject, but you sound like you realize what you’re talking about! Thanks
I’ve been browsing on-line more than 3 hours as of late, yet I by no means discovered any interesting article like yours. It is pretty price sufficient for me. In my opinion, if all web owners and bloggers made excellent content as you did, the net can be much more helpful than ever before. “When you are content to be simply yourself and don’t compare or compete, everybody will respect you.” by Lao Tzu.
I couldn’t resist commenting
Rattling excellent information can be found on website. “Preach not to others what they should eat, but eat as becomes you, and be silent.” by Epictetus.
Is Slimtide Legit ?
Very interesting topic, thanks for posting.
Hiya very nice site!! Guy .. Beautiful .. Superb .. I’ll bookmark your website and take the feeds additionallyKI’m glad to find so many useful info here in the publish, we’d like develop more strategies on this regard, thanks for sharing. . . . . .
SLIMTIDE
I like this post, enjoyed this one regards for posting.
SLIMTIDE SUPPLEMENT
It’s really a nice and useful piece of information. I’m glad that you shared this helpful info with us. Please keep us up to date like this. Thank you for sharing.
It’s hard to find knowledgeable people on this topic, but you sound like you know what you’re talking about! Thanks
Some genuinely nice and useful info on this internet site, also I think the style and design has got wonderful features.
Today, while I was at work, my sister stole my iphone and tested to see if it can survive a 30 foot drop, just so she can be a youtube sensation. My apple ipad is now destroyed and she has 83 views. I know this is entirely off topic but I had to share it with someone!
Thank you for the sensible critique. Me and my neighbor were just preparing to do some research on this. We got a grab a book from our local library but I think I learned more from this post. I am very glad to see such wonderful info being shared freely out there.
There’s noticeably a bundle to know about this. I assume you made certain good points in options also.
It’s arduous to search out educated folks on this topic, but you sound like you already know what you’re talking about! Thanks
Hello there! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same niche. Your blog provided us valuable information to work on. You have done a outstanding job!
I got good info from your blog
I saw a lot of website but I conceive this one has something special in it in it
As soon as I found this web site I went on reddit to share some of the love with them.
JELLYFIL REVIEWS
jellyfill review
I am glad to be one of the visitors on this outstanding site (:, regards for posting.
Some genuinely interesting information, well written and broadly user genial.
Dead written written content, Really enjoyed reading through.
Greetings! Very helpful advice on this article! It is the little changes that make the biggest changes. Thanks a lot for sharing!
JELLYFIL REVIEWS
I would like to thnkx for the efforts you have put in writing this blog. I am hoping the same high-grade blog post from you in the upcoming as well. In fact your creative writing abilities has inspired me to get my own blog now. Really the blogging is spreading its wings quickly. Your write up is a good example of it.
Woh I like your articles, saved to favorites! .
JELLYFILL
I am glad to be one of the visitors on this great web site (:, regards for posting.
I’d need to test with you here. Which is not one thing I normally do! I take pleasure in reading a post that may make folks think. Additionally, thanks for allowing me to comment!
Dead composed subject material, Really enjoyed reading through.
Whats up very cool site!! Guy .. Beautiful .. Wonderful .. I’ll bookmark your web site and take the feeds alsoKI’m satisfied to search out so many useful information here in the submit, we want develop more strategies on this regard, thank you for sharing. . . . . .
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.
Great tremendous things here. I am very happy to look your article. Thanks a lot and i am looking ahead to contact you. Will you please drop me a mail?
Hi there very nice web site!! Man .. Beautiful .. Wonderful .. I will bookmark your web site and take the feeds alsoKI’m satisfied to search out numerous useful information here within the post, we need work out more techniques in this regard, thanks for sharing. . . . . .
I simply had to thank you so much all over again. I’m not certain the things I would’ve taken care of in the absence of the entire tactics shared by you over this situation. It became a real difficult circumstance in my circumstances, however , coming across a specialised style you solved the issue made me to leap over contentment. I am happier for this information and in addition pray you are aware of a powerful job you happen to be undertaking teaching some other people via your blog post. I’m certain you’ve never come across all of us.
You really make it appear so easy with your presentation however I to find this matter to be actually one thing that I think I would never understand. It seems too complicated and extremely broad for me. I’m looking forward to your next post, I will attempt to get the cling of it!
Enjoyed studying this, very good stuff, regards.
Whoa! This blog looks just like my old one! It’s on a totally different subject but it has pretty much the same page layout and design. Outstanding choice of colors!
I have been browsing on-line more than 3 hours these days, but I by no means found any interesting article like yours. It is lovely price sufficient for me. In my view, if all site owners and bloggers made just right content as you did, the web can be much more useful than ever before.
You have brought up a very great points, thankyou for the post.
Admiring the commitment you put into your site and detailed information you provide. It’s good to come across a blog every once in a while that isn’t the same outdated rehashed material. Wonderful read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
Sweet site, super style and design, real clean and utilize genial.
I am curious to find out what blog system you happen to be working with? I’m having some small security issues with my latest website and I would like to find something more safe. Do you have any recommendations?
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
I precisely had to thank you very much again. I am not sure the things that I could possibly have implemented without the pointers contributed by you regarding such a industry. It was the intimidating crisis for me personally, but spending time with the very well-written fashion you dealt with that took me to jump with fulfillment. I’m happier for this assistance and expect you really know what a powerful job you have been providing teaching men and women using a site. More than likely you haven’t met any of us.
Appreciate it for this grand post, I am glad I found this internet site on yahoo.
You can definitely see your expertise in the work you write. The world hopes for even more passionate writers like you who aren’t afraid to say how they believe. Always go after your heart.
This internet site is my breathing in, very excellent style and perfect content.
You must take part in a contest for one of the best blogs on the web. I will advocate this site!
Hi! Someone in my Facebook group shared this site with us so I came to give it a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers! Superb blog and wonderful style and design.
Some really superb information, Gladiola I noticed this.
Hello there! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
Hello.This article was extremely motivating, especially since I was browsing for thoughts on this topic last Saturday.
Alpha Rock Review
Alpha Rock Supplement
Currently it looks like Movable Type is the best blogging platform out there right now. (from what I’ve read) Is that what you’re using on your blog?
You really make it seem really easy together with your presentation but I find this matter to be really one thing that I think I would by no means understand. It kind of feels too complicated and extremely extensive for me. I’m taking a look ahead for your next post, I will attempt to get the dangle of it!
NEXBURN
I’ve recently started a site, the info you offer on this web site has helped me greatly. Thanks for all of your time & work. “A creative man is motivated by the desire to achieve, not by the desire to beat others.” by Ayn Rand.
NexBurn Review
Saved as a favorite, I really like your blog!
Thanks a lot for sharing this with all of us you actually know what you are talking about! Bookmarked. Please also visit my site =). We could have a link exchange agreement between us!
There are some interesting time limits on this article but I don’t know if I see all of them middle to heart. There may be some validity however I’ll take maintain opinion till I look into it further. Good article , thanks and we want extra! Added to FeedBurner as well
The next time I read a blog, I hope that it doesnt disappoint me as much as this one. I mean, I know it was my choice to read, but I actually thought youd have something interesting to say. All I hear is a bunch of whining about something that you could fix if you werent too busy looking for attention.
Hello. magnificent job. I did not expect this. This is a impressive story. Thanks!
Great write-up, I’m regular visitor of one’s blog, maintain up the excellent operate, and It is going to be a regular visitor for a lengthy time.
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
We are a group of volunteers and starting a brand new scheme in our community. Your website offered us with valuable information to paintings on. You have done an impressive process and our whole neighborhood will be thankful to you.
Awesome blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple adjustements would really make my blog shine. Please let me know where you got your design. Thanks
You have brought up a very great points, thankyou for the post.
Simply a smiling visitant here to share the love (:, btw outstanding layout.
I am extremely inspired along with your writing talents and also with the format on your blog. Is that this a paid theme or did you customize it yourself? Either way keep up the nice high quality writing, it’s uncommon to peer a nice blog like this one these days..
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
Hi my friend! I wish to say that this post is awesome, nice written and include approximately all important infos. I would like to see more posts like this.
Glad to be one of many visitors on this awing web site : D.
This is the right blog for anyone who wants to find out about this topic. You realize so much its almost hard to argue with you (not that I actually would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great!
The following time I read a weblog, I hope that it doesnt disappoint me as a lot as this one. I mean, I know it was my option to read, but I really thought youd have one thing fascinating to say. All I hear is a bunch of whining about one thing that you might fix should you werent too busy looking for attention.
I’ve been exploring for a little for any high quality articles or weblog posts in this kind of space . Exploring in Yahoo I finally stumbled upon this web site. Studying this information So i’m glad to exhibit that I have a very good uncanny feeling I discovered just what I needed. I such a lot for sure will make certain to don’t overlook this site and provides it a look regularly.
I always was interested in this subject and still am, regards for posting.
Great post. I am facing a couple of these problems.
Only a smiling visitant here to share the love (:, btw outstanding layout.
Thanks a lot for giving everyone such a spectacular chance to check tips from here. It is usually so fantastic and stuffed with amusement for me and my office acquaintances to visit your website a minimum of three times a week to read through the newest stuff you will have. And lastly, I’m so at all times fulfilled for the tremendous guidelines you serve. Some 2 areas in this post are without a doubt the most beneficial we have all ever had.
Whats Taking place i’m new to this, I stumbled upon this I’ve found It positively helpful and it has helped me out loads. I’m hoping to give a contribution & help different users like its helped me. Good job.
Very interesting information!Perfect just what I was searching for!
Normally I do not read post on blogs, however I would like to say that this write-up very compelled me to check out and do so! Your writing taste has been amazed me. Thank you, very nice article.
What’s Going down i’m new to this, I stumbled upon this I’ve found It positively useful and it has aided me out loads. I’m hoping to give a contribution & help other users like its aided me. Great job.
I like this post, enjoyed this one thanks for putting up. “The reward for conformity was that everyone liked you except yourself.” by Rita Mae Brown.
It is in reality a great and helpful piece of info. I am satisfied that you just shared this helpful info with us. Please keep us informed like this. Thank you for sharing.
I’m not sure where you are getting your info, but great topic. I needs to spend some time learning much more or understanding more. Thanks for magnificent info I was looking for this information for my mission.
I am lucky that I discovered this web site, exactly the right information that I was searching for! .
Everyone loves what you guys tend to be up too. This type of clever work and reporting! Keep up the terrific works guys I’ve incorporated you guys to my own blogroll.
Great website! I am loving it!! Will be back later to read some more. I am taking your feeds also
It’s actually a cool and helpful piece of information. I’m glad that you simply shared this helpful information with us. Please keep us informed like this. Thank you for sharing.
Nice read, I just passed this onto a friend who was doing a little research on that. And he actually bought me lunch because I found it for him smile Therefore let me rephrase that: Thanks for lunch!
The following time I read a weblog, I hope that it doesnt disappoint me as much as this one. I imply, I know it was my choice to learn, however I actually thought youd have one thing attention-grabbing to say. All I hear is a bunch of whining about something that you may fix in the event you werent too busy on the lookout for attention.
Nice post. I was checking constantly this blog and I’m impressed! Extremely useful information specially the last part 🙂 I care for such information much. I was seeking this certain info for a very long time. Thank you and best of luck.
Baking Soda For Weight Loss
Hi there, You’ve done a great job. I’ll definitely digg it and in my opinion recommend to my friends. I am confident they will be benefited from this website.
Baking Soda For Weight Loss
Baking Soda For Weight Loss
Baking Soda Recipe
Baking Soda and Lemon Juice For Weight Loss
Baking Soda Water Shot
Baking Soda Recipe
JELLYFIL
JELLYFIL
hello!,I really like your writing very much! percentage we keep in touch extra about your article on AOL? I need an expert on this house to unravel my problem. May be that’s you! Taking a look forward to peer you.
Jellyfil Supplement Reviews
JELLYFIL
Jellyfil Reviews
Jellyfil Reviews
Jellyfil Reviews
Jellyfil Supplement Reviews
Whats up this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding skills so I wanted to get advice from someone with experience. Any help would be enormously appreciated!
Hey very nice web site!! Man .. Beautiful .. Amazing .. I will bookmark your site and take the feeds also…I am happy to find numerous useful information here in the post, we need work out more strategies in this regard, thanks for sharing. . . . . .
Have you ever thought about creating an e-book or guest authoring on other blogs? I have a blog centered on the same ideas you discuss and would really like to have you share some stories/information. I know my audience would value your work. If you’re even remotely interested, feel free to shoot me an email.
I conceive this web site has got some rattling excellent information for everyone :D.
I like this post, enjoyed this one appreciate it for posting.
Hiya, I’m really glad I have found this information. Nowadays bloggers publish only about gossips and web and this is actually irritating. A good site with interesting content, this is what I need. Thanks for keeping this site, I will be visiting it. Do you do newsletters? Cant find it.
Good day! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Thanks for the article, is there any way I can get an alert email when you make a fresh post?
Awsome site! I am loving it!! Will be back later to read some more. I am taking your feeds also
Your place is valueble for me. Thanks!…
I simply couldn’t leave your web site prior to suggesting that I really loved the usual information a person provide to your guests? Is gonna be again continuously in order to investigate cross-check new posts
I want looking through and I think this website got some genuinely useful stuff on it! .
You have brought up a very great points, thankyou for the post.
Awesome blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple tweeks would really make my blog stand out. Please let me know where you got your theme. With thanks
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100 certain. Any tips or advice would be greatly appreciated. Kudos
Today, I went to the beach front with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
Currently it seems like Drupal is the top blogging platform available right now. (from what I’ve read) Is that what you are using on your blog?
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
I genuinely enjoy studying on this web site, it contains wonderful articles. “I have a new philosophy. I’m only going to dread one day at a time.” by Charles M. Schulz.
I was very pleased to find this web-site.I wanted to thanks for your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
This really answered my drawback, thanks!
magnificent points altogether, you just gained a brand new reader. What would you recommend in regards to your post that you made some days ago? Any positive?
It is really a nice and useful piece of info. I’m glad that you shared this helpful info with us. Please keep us up to date like this. Thanks for sharing.
I used to be suggested this website by way of my cousin. I’m now not certain whether this publish is written by way of him as nobody else realize such precise approximately my difficulty. You are wonderful! Thanks!
Great write-up, I am normal visitor of one’s blog, maintain up the nice operate, and It is going to be a regular visitor for a lengthy time.
I want assembling utile info, this post has got me even more info! .
Nice post. I learn something more challenging on different blogs everyday. It will always be stimulating to read content from other writers and practice a little something from their store. I’d prefer to use some with the content on my blog whether you don’t mind. Natually I’ll give you a link on your web blog. Thanks for sharing.
I couldn’t resist commenting
That is the right blog for anybody who wants to search out out about this topic. You realize so much its nearly arduous to argue with you (not that I truly would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Nice stuff, simply nice!
Very interesting subject, appreciate it for putting up. “It is much easier to try one’s hand at many things than to concentrate one’s powers on one thing.” by Quintilian.
Good day! I know this is somewhat off topic but I was wondering which blog platform are you using for this website? I’m getting tired of WordPress because I’ve had issues with hackers and I’m looking at options for another platform. I would be awesome if you could point me in the direction of a good platform.
It’s appropriate time to make some plans for the future and it is time to be happy. I have read this post and if I could I want to suggest you some interesting things or advice. Perhaps you could write next articles referring to this article. I wish to read more things about it!
Heya i’m for the first time here. I found this board and I find It really useful & it helped me out much. I hope to give something back and aid others like you helped me.
hello!,I like your writing very much! share we communicate more about your post on AOL? I need a specialist on this area to solve my problem. Maybe that’s you! Looking forward to see you.
I’m really enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a developer to create your theme? Great work!
A powerful share, I just given this onto a colleague who was doing somewhat evaluation on this. And he the truth is purchased me breakfast because I found it for him.. smile. So let me reword that: Thnx for the deal with! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading extra on this topic. If potential, as you grow to be expertise, would you mind updating your weblog with more particulars? It’s extremely helpful for me. Huge thumb up for this blog submit!
Merely wanna say that this is handy, Thanks for taking your time to write this.
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
Hi there, I found your site via Google while searching for a related topic, your website came up, it looks good. I have bookmarked it in my google bookmarks.
Hmm, nhìn qua cái cách họ phân tích tần suất này hay đấy. Dù sao thì, xem kỹ các chỉ số thống kê như thế này vẫn cần cẩn thận. Thử xem thêm c188 app download apk để đối chiếu thêm thì an tâm hơn nhỉ.
An interesting discussion is worth comment. I think that you should write more on this topic, it might not be a taboo subject but generally people are not enough to speak on such topics. To the next. Cheers
Would love to always get updated outstanding web blog! .
Thankyou for this post, I am a big big fan of this web site would like to go along updated.
After study a few of the blog posts on your website now, and I truly like your way of blogging. I bookmarked it to my bookmark website list and will be checking back soon. Pls check out my web site as well and let me know what you think.
Wow, fantastic blog layout! How lengthy have you ever been blogging for? you make running a blog look easy. The entire glance of your website is magnificent, let alone the content!
I think this website contains some real great information for everyone :D. “Experience is not what happens to you it’s what you do with what happens to you.” by Aldous Huxley.
I’d have to examine with you here. Which is not one thing I usually do! I take pleasure in reading a post that may make folks think. Additionally, thanks for permitting me to comment!
Hello there, I found your website via Google while searching for a related topic, your website came up, it looks great. I’ve bookmarked it in my google bookmarks.
You should take part in a contest for one of the best blogs on the web. I will recommend this site!
My spouse and I stumbled over here different page and thought I should check things out. I like what I see so i am just following you. Look forward to finding out about your web page yet again.
I will right away clutch your rss as I can not in finding your email subscription link or e-newsletter service. Do you’ve any? Please let me recognize so that I may subscribe. Thanks.
Wonderful post however , I was wondering if you could write a litte more on this subject? I’d be very grateful if you could elaborate a little bit further. Kudos!
Some truly superb info , Glad I observed this. “Someone’s boring me. I think it’s me.” by Dylan Thomas.
very good publish, i certainly love this web site, carry on it
I dugg some of you post as I cerebrated they were very useful handy
What’s Going down i’m new to this, I stumbled upon this I’ve found It positively useful and it has aided me out loads. I hope to give a contribution & aid different customers like its helped me. Great job.
Thanks for sharing excellent informations. Your website is very cool. I am impressed by the details that you have on this website. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for more articles. You, my pal, ROCK! I found simply the information I already searched everywhere and just couldn’t come across. What a great website.
Today, I went to the beachfront with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
Hello there, You’ve done an incredible job. I will definitely digg it and personally suggest to my friends. I’m sure they will be benefited from this web site.
Rattling informative and good body structure of subject material, now that’s user friendly (:.
Rattling great information can be found on web blog.
I’ve recently started a site, the info you provide on this site has helped me greatly. Thanks for all of your time & work.
you’re in reality a excellent webmaster. The web site loading pace is incredible. It sort of feels that you are doing any unique trick. In addition, The contents are masterpiece. you’ve performed a fantastic job on this topic!
Some really good info , Gladiolus I found this.
Simply wish to say your article is as astounding. The clearness in your post is just cool and i could assume you’re an expert on this subject. Fine with your permission allow me to grab your RSS feed to keep updated with forthcoming post. Thanks a million and please continue the enjoyable work.
I’d constantly want to be update on new posts on this internet site, saved to favorites! .
you’re in reality a just right webmaster. The website loading speed is incredible. It kind of feels that you are doing any unique trick. In addition, The contents are masterwork. you have done a fantastic task on this topic!
I’m impressed, I need to say. Actually rarely do I encounter a blog that’s each educative and entertaining, and let me inform you, you’ve gotten hit the nail on the head. Your thought is excellent; the issue is something that not sufficient people are speaking intelligently about. I’m very glad that I stumbled throughout this in my seek for something regarding this.
Hi, Neat post. There is a problem along with your website in web explorer, could check thisK IE nonetheless is the market chief and a good element of people will leave out your great writing because of this problem.
Thanks for another fantastic post. Where else could anyone get that kind of information in such an ideal way of writing? I’ve a presentation next week, and I am on the look for such information.
You made a few nice points there. I did a search on the subject and found a good number of people will have the same opinion with your blog.
I just could not depart your website prior to suggesting that I actually enjoyed the standard info a person provide for your visitors? Is going to be back often to check up on new posts
Thank you for any other informative website. Where else may I get that type of info written in such an ideal means? I’ve a venture that I’m just now running on, and I have been at the look out for such info.
Those are yours alright! . We at least need to get these people stealing images to start blogging! They probably just did a image search and grabbed them. They look good though!
Hey, you used to write magnificent, but the last few posts have been kinda boring… I miss your great writings. Past several posts are just a little out of track! come on!
Greetings! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same niche. Your blog provided us beneficial information to work on. You have done a marvellous job!
Youre so cool! I dont suppose Ive read anything like this before. So nice to seek out any individual with some original ideas on this subject. realy thank you for starting this up. this web site is something that’s needed on the web, someone with a bit originality. helpful job for bringing something new to the web!
But wanna comment on few general things, The website design and style is perfect, the articles is really great : D.
Keep up the good piece of work, I read few blog posts on this site and I believe that your web blog is real interesting and has got bands of good info .
you could have an ideal blog right here! would you prefer to make some invite posts on my blog?
I am incessantly thought about this, thanks for posting.
Interesting blog! Is your theme custom made or did you download it from somewhere? A theme like yours with a few simple adjustements would really make my blog jump out. Please let me know where you got your design. Thank you
I like what you guys are up also. Such clever work and reporting! Keep up the excellent works guys I have incorporated you guys to my blogroll. I think it will improve the value of my site 🙂
Keep up the excellent piece of work, I read few posts on this website and I think that your web blog is very interesting and has got sets of excellent info .
Hmm it seems like your website ate my first comment (it was super long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to everything. Do you have any points for first-time blog writers? I’d really appreciate it.
Great post. I am facing a couple of these problems.
Hey, you used to write great, but the last several posts have been kinda boringK I miss your tremendous writings. Past several posts are just a bit out of track! come on!
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.
Great remarkable things here. I am very glad to look your post. Thanks so much and i am having a look forward to contact you. Will you please drop me a mail?
Hi there! I’m at work browsing your blog from my new iphone 4! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the outstanding work!
SODASLIM
sodaslim capsules
SODASLIM
sodaslim reviews
SODASLIM
I love the efforts you have put in this, thank you for all the great content.
sodaslim reviews
I went over this site and I think you have a lot of superb info, saved to bookmarks (:.
F*ckin’ tremendous things here. I’m very glad to see your post. Thank you so much and i’m taking a look forward to contact you. Will you kindly drop me a mail?
I really like looking through and I believe this website got some truly utilitarian stuff on it! .
I like this web blog so much, saved to favorites.
Great write-up, I’m regular visitor of one’s web site, maintain up the excellent operate, and It is going to be a regular visitor for a lengthy time.
Aw, this was a really nice post. In idea I want to put in writing like this moreover – taking time and precise effort to make a very good article… however what can I say… I procrastinate alot and by no means seem to get one thing done.
I have been surfing online greater than three hours lately, but I by no means discovered any interesting article like yours. It’s pretty worth enough for me. In my opinion, if all site owners and bloggers made good content as you did, the web will likely be much more useful than ever before. “Dignity is not negotiable. Dignity is the honor of the family.” by Vartan Gregorian.
I would like to thank you for the efforts you’ve put in writing this site. I’m hoping the same high-grade web site post from you in the upcoming also. Actually your creative writing abilities has encouraged me to get my own blog now. Actually the blogging is spreading its wings rapidly. Your write up is a great example of it.
Hiya, I’m really glad I’ve found this info. Today bloggers publish only about gossips and internet and this is really frustrating. A good site with exciting content, that’s what I need. Thanks for keeping this web site, I will be visiting it. Do you do newsletters? Can not find it.
Some genuinely marvelous work on behalf of the owner of this internet site, utterly outstanding content.
I love your writing style genuinely enjoying this website .
Really good visual appeal on this internet site, I’d value it 10 10.
Hi my friend! I wish to say that this article is awesome, great written and include approximately all vital infos. I’d like to peer extra posts like this .
good post.Never knew this, thankyou for letting me know.
Magnificent beat ! I would like to apprentice while you amend your site, how could i subscribe for a weblog site? The account helped me a applicable deal. I have been a little bit acquainted of this your broadcast offered brilliant transparent concept
I love it when people come together and share opinions, great blog, keep it up.
Hey there this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience. Any help would be greatly appreciated!
I was just searching for this info for a while. After six hours of continuous Googleing, finally I got it in your site. I wonder what’s the lack of Google strategy that do not rank this kind of informative websites in top of the list. Generally the top sites are full of garbage.
This design is incredible! You obviously know how to keep a reader amused. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job. I really enjoyed what you had to say, and more than that, how you presented it. Too cool!