
Introduction
The evaluation of knowledge base results within Generative Artificial Intelligence frameworks demands rigorous analytical methodologies to navigate complex metrics. This blog outlines a few key metrics i.e. Answer Relevance, Faithfulness Score, Context Precision, Context Relevancy, and Context Recall, aiming to improve GenAI Knowledge Base system performance. Through mathematical foundations and practical examples via the Ragas library in Python, offer a framework for utilizing these metrics effectively. Our goal is to provide a concise guide for enhancing GenAI knowledge bases, ensuring they meet rigorous standards of faithfulness and accuracy.
Answer Relevance
Answer Relevance focuses on assessing how pertinent the generated answer is to the given prompt. A lower score is assigned to an answer that is comprised of or contains redundant information, and higher scores indicate better relevancy. This metric is computed using the question, the context, and the answer.
The Answer Relevancy is defined as the mean cosine similarity of the original question to a number of related questions, which are generated (reverse-engineered) based on the answer:
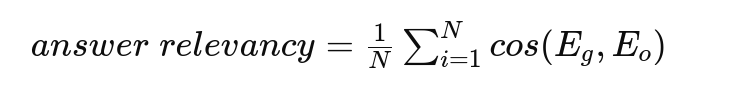
Where:
- Eg is the embedding of the generated question.
- Eo is the embedding of the original question.
- N is the number of generated questions, which is 3 by default.
Let’s make this intuitive with an example:
Original Question: What is the capital of India?
Generated Answer: New Delhi is the capital of India. It serves as the seat of the three branches of the Government of India: executive, legislature and judiciary.
- To calculate the relevance of this answer to the given question, we follow two steps:
- Reverse engineer ‘N’ variants of the question from the generated answer using a Large Language Model (LLM). For instance, for the first answer, the LLM might generate the following possible questions:
- Question 1: “Which city is the capital of India?”
- Question 2: “What is the seat of the Government of India?”
- Question 3: “Where are the three branches of the Indian government located?”
- Calculate the mean cosine similarity between the generated questions and the actual question.
from ragas import answer_relevancy
from ragas import evaluate
data_sample = {
'question': ["What is the capital of India?"],
'context': ["New Delhi is the capital of India. It serves as the seat of the three branches of the Government of India: executive, legislature and judiciary."],
'answer': ["New Delhi is the capital of India. It serves as the seat of the three branches of the Government of India: executive, legislature and judiciary."]
}
dataset = Dataset.from_dict(data_sample)
metric = evaluate.load('answer_relevancy')
score = metric.compute(dataset=dataset, metrics=[answer_relevancy])
print(f"Answer Relevancy: {score['answer_relevancy']:.2f}")
The underlying concept is that if the answer correctly addresses the question, it is highly probable that the original question can be reconstructed solely from the answer.
Faithfulness Score
The Faithfulness score assesses the factual consistency of the generated answer against the given context. It’s calculated using the following formula:

To make this intuitive, let’s consider an example. Suppose we have a GenAI system that generates the following response:
“The Taj Mahal, located in Agra, India, is an ivory-white marble mausoleum on the right bank of the Yamuna river. It was commissioned in 1632 by the Mughal emperor Shah Jahan to house the tomb of his favorite wife, Mumtaz Mahal.”
If the given context supports both claims (location of the Taj Mahal and its commissioning details), the Faithfulness score would be 1, indicating perfect factual consistency.
from ragas import faithfulness
from ragas import evaluate
data_sample = {
'question': ["Where is the Taj Mahal located and who commissioned it?"],
'context': ["The Taj Mahal, located in Agra, India, is an ivory-white marble mausoleum on the right bank of the Yamuna river. It was commissioned in 1632 by the Mughal emperor Shah Jahan to house the tomb of his favorite wife, Mumtaz Mahal."],
'answer': ["The Taj Mahal, located in Agra, India, is an ivory-white marble mausoleum on the right bank of the Yamuna river. It was commissioned in 1632 by the Mughal emperor Shah Jahan to house the tomb of his favorite wife, Mumtaz Mahal."]
}
dataset = Dataset.from_dict(data_sample)
metric = evaluate.load('faithfulness')
score = metric.compute(dataset=dataset, metrics=[faithfulness])
print(f"Faithfulness Score: {score['faithfulness']:.2f}")
Context Precision
Context Precision is a metric that evaluates whether all of the ground-truth reference items present in the context are ranked lower or not. Ideally, all the relevant chunks must appear at the top ranks. This metric is computed using the question, ground-truth, and the context, with values ranging between 0 and 1, where higher scores indicate better precision.
The formula for calculating Context Precision is:
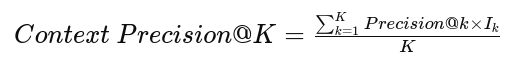
Where:
- K is the total number of chunks in context
- Ik is the relevance indicator at rank k
- Precision@ is the precision at cut-off k
Let’s consider an example:
Suppose we have a question “What is the capital of India?” and the following context chunks:
- India is a country in South Asia.
- New Delhi, India’s capital, is known for its historical monuments like the Red Fort and Qutub Minar.
- India is known for its diverse culture, languages, and cuisine.
If the ground truth answer is “New Delhi is the capital of India”, then:
- I1 = 0 (irrelevant)
- I2 =1 (relevant)
- I3 = 0 (irrelevant)
Therefore, the Context Precision would be:
Context Precision = (0/1+1/2+0/3)/3 = 0.17
A Context Precision of 0.17 indicates that the relevant chunk is not ranked at the very top, and there is room for improvement in the ranking of context chunks.
from ragas import context_precision
from ragas import evaluate
data_sample = {
'question': ["What is the capital of India?"],
'context': ["India is a country in South Asia. New Delhi, India's capital, is known for its historical monuments like the Red Fort and Qutub Minar. India is known for its diverse culture, languages, and cuisine."],
'ground_truth': ["New Delhi is the capital of India"]
}
dataset = Dataset.from_dict(data_sample)
metric = evaluate.load('context_precision')
score = metric.compute(dataset=dataset, metrics=[context_precision])
print(f"Context Precision: {score['context_precision']:.2f}")
Context Relevancy
Context Relevancy gauges the relevancy of the retrieved context, calculated based on both the question and context. The values fall within the range of (0, 1), with higher values indicating better relevancy.
To compute Context Relevancy, we initially estimate the value of ∣S∣ by identifying sentences within the retrieved context that are relevant for answering the given question. The final score is determined by the following formula:
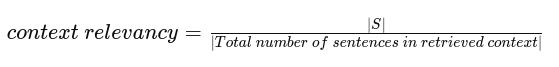
Let’s make this intuitive with an example:
Question: What is the capital of India?
Retrieved Context:
- India is a country in South Asia.
- New Delhi, India’s capital, is known for its historical monuments like the Red Fort and Qutub Minar.
In this case, only the second sentence in the retrieved context is relevant to answering the question. So, ∣S∣=1
Therefore, the Context Relevancy would be:
context relevancy=1/2=0.5
A Context Relevancy of 0.5 suggests that half of the retrieved context is relevant to answering the question.
context relevancy=1/2=0.5A Context Relevancy of 0.5 suggests that half of the retrieved context is relevant to answering the question.
from ragas import context_relevancy
from ragas import evaluate
data_sample = {
'question': ["What is the capital of India?"],
'context': ["India is a country in South Asia. New Delhi, India's capital, is known for its historical monuments like the Red Fort and Qutub Minar."],
'num_rows': 25
}
dataset = Dataset.from_dict(data_sample)
metric = evaluate.load('context_relevancy')
score = metric.compute(dataset=dataset, metrics=[context_relevancy])
print(f"Context Relevancy: {score['context_relevancy']:.2f}")
Context Recall
Context Recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth. It is computed based on the “ground truth” and the retrieved context, and the values range between 0 and 1, with higher values indicating better performance.
To estimate context recall from the ground truth answer, each sentence in the ground truth answer is analyzed to determine whether it can be attributed to the retrieved context or not. In an ideal scenario, all sentences in the ground truth answer should be attributable to the retrieved context.
The formula for calculating context recall is as follows:
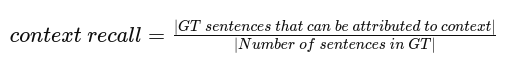
Let’s consider an example to make this intuitive:
Ground Truth Answer: “New Delhi is the capital of India. It is located in the northern part of the country.”
Retrieved Context: “New Delhi, India’s capital, is known for its historical monuments like the Red Fort and Qutub Minar. It is situated in the northern region of India.”
In this case, both sentences in the ground truth answer can be attributed to the retrieved context.
Therefore, the Context Recall would be:
context recall = 2/2 = 1
A Context Recall of 1 indicates that all the sentences in the ground truth answer are covered by the retrieved context, showcasing perfect recall.
from ragas import context_recall
from ragas import evaluate
data_sample = {
'question': ["What is the capital of India?"],
'context': ["New Delhi, India's capital, is known for its historical monuments like the Red Fort and Qutub Minar. It is situated in the northern region of India."],
'ground_truth': ["New Delhi is the capital of India. It is located in the northern part of the country."]
}
dataset = Dataset.from_dict(data_sample)
metric = evaluate.load('context_recall')
score = metric.compute(dataset=dataset, metrics=[context_recall])
print(f"Context Recall: {score['context_recall']:.2f}")
Conclusion
The accuracy and reliability of Generative AI systems hinge on comprehensive performance evaluation. By leveraging metrics like Answer Relevance, Faithfulness score, Context Precision, Context Relevancy, and Context Recall, we can systematically assess the performance of our GenAI systems. The Ragas library provides a powerful toolset for calculating these metrics effortlessly.
Throughout this blog post, we’ve tried to make the mathematics behind these metrics intuitive. By understanding how these metrics work and what they represent, you can make data-driven decisions to improve the faithfulness of your GenAI knowledge bases.
Remember, the key to effective evaluation is to use these metrics in conjunction with each other, rather than relying on a single metric alone. By considering the discussed metrics together, you can gain a comprehensive understanding of your GenAI system’s performance and identify areas for improvement.
Happy evaluating, and may your GenAI knowledge bases be faithful and reliable!








